Welcome to KubeFleet Documentation
Welcome ✨ This documentation can help you learn more about the KubeFleet project,
get started with a KubeFleet deployment of your own, and complete common KubeFleet related tasks.
WIP
We are actively working on the documentation site.About KubeFleet
KubeFleet is a CNCF sandbox project that aims to simplify Kubernetes multi-cluster management.
It can greatly enhance your multi-cluster management experience; specifically, with the help of KubeFleet, you can easily:
- manage clusters through one unified API; and
- place Kubernetes resources across a group of clusters with advanced scheduling capabilities; and
- roll out changes progressively; and
- perform administrative tasks easily, such as observing application status, detecting configuration drifts, and migrating workloads across clusters.
Is KubeFleet right for my multi-cluster setup?
✅ KubeFleet can work with any Kubernetes clusters running supported Kubernetes versions, regardless of where they are set up.
You can set up KubeFleet with an on-premises cluster, a cluster hosted on public clouds such as
Azure, or even a local kind cluster.
✅ KubeFleet can manage Kubernetes cluster groups of various sizes.
KubeFleet is designed with performance and scalablity in mind. It functions well with both
smaller Kubernetes cluster groups and those with up to hundreds of Kubernetes clusters and
thousands of nodes.
🚀 KubeFleet is evolving fast.
We are actively developing new features and functionalities for KubeFleet. If you have any questions, suggestions, or feedbacks, please let us know.
Get started
Find out how to deploy KubeFleet with one of our Getting Started tutorials. You can use a local setup to experiment with KubeFleet’s features, and explore its UX.
1 - Concepts
Core concepts in Fleet
The documentation in this section explains core Fleet concepts. Pick one below to proceed.
1.1 - Fleet components
Concept about the Fleet components
Components
This document provides an overview of the components required for a fully functional and operational Fleet setup.
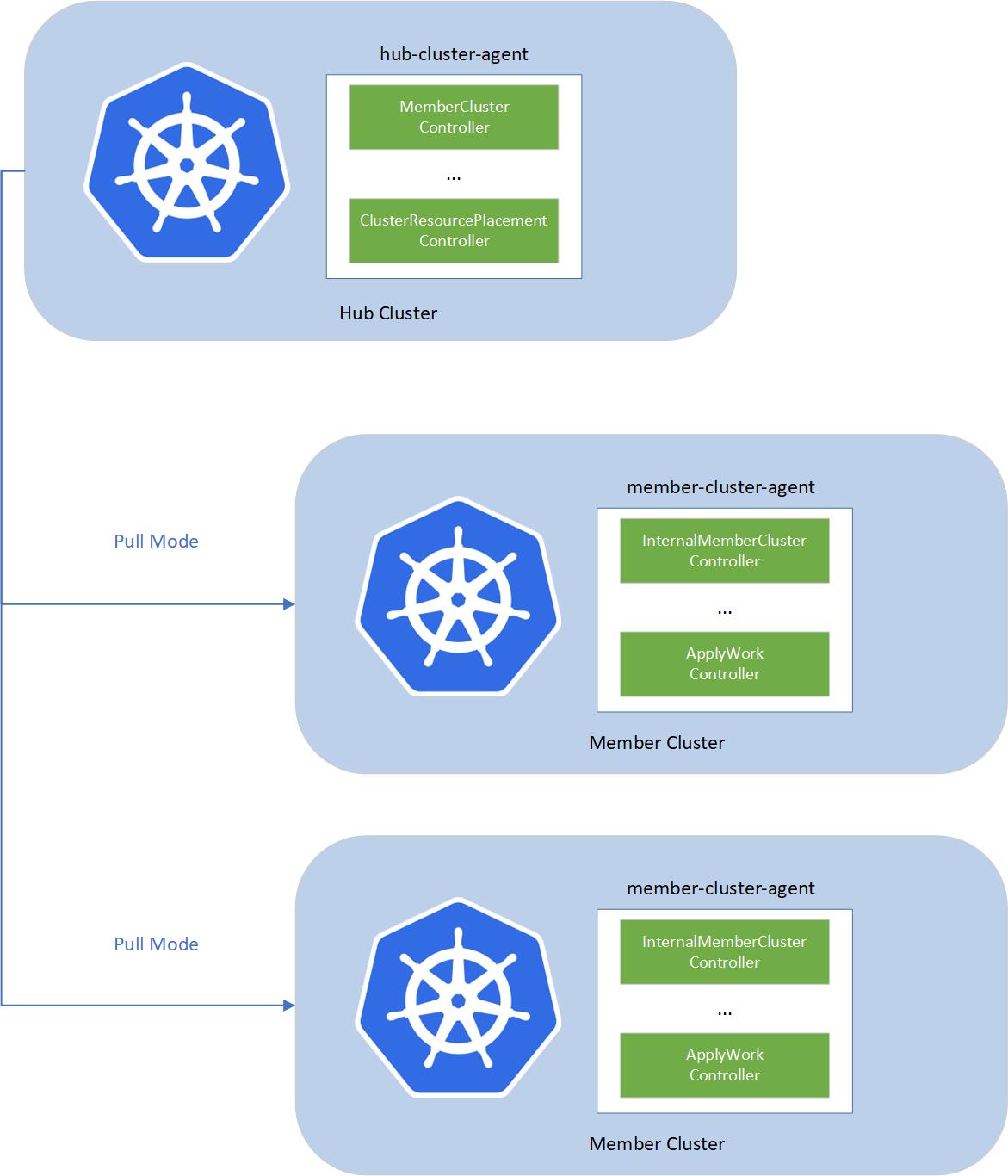
The fleet consists of the following components:
- fleet-hub-agent is a Kubernetes controller that creates and reconciles all the fleet related CRs in the hub cluster.
- fleet-member-agent is a Kubernetes controller that creates and reconciles all the fleet related CRs in the member cluster.
The fleet-member-agent is pulling the latest CRs from the hub cluster and consistently reconciles the member clusters to
the desired state.
The fleet implements agent-based pull mode. So that the working pressure can be distributed to the member clusters, and it
helps to breach the bottleneck of scalability, by dividing the load into each member cluster. On the other hand, hub
cluster does not need to directly access to the member clusters. Fleet can support the member clusters which only have
the outbound network and no inbound network access.
To allow multiple clusters to run securely, fleet will create a reserved namespace on the hub cluster to isolate the access permissions and
resources across multiple clusters.
1.2 - MemberCluster
Concept about the MemberCluster API
Overview
The fleet constitutes an implementation of a ClusterSet and
encompasses the following attributes:
- A collective of clusters managed by a centralized authority.
- Typically characterized by a high level of mutual trust within the cluster set.
- Embraces the principle of Namespace Sameness across clusters:
- Ensures uniform permissions and characteristics for a given namespace across all clusters.
- While not mandatory for every cluster, namespaces exhibit consistent behavior across those where they are present.
The MemberCluster represents a cluster-scoped API established within the hub cluster, serving as a representation of
a cluster within the fleet. This API offers a dependable, uniform, and automated approach for multi-cluster applications
(frameworks, toolsets) to identify registered clusters within a fleet. Additionally, it facilitates applications in querying
a list of clusters managed by the fleet or observing cluster statuses for subsequent actions.
Some illustrative use cases encompass:
- The Fleet Scheduler utilizing managed cluster statuses or specific cluster properties (e.g., labels, taints) of a
MemberCluster
for resource scheduling. - Automation tools like GitOps systems (e.g., ArgoCD or Flux) automatically registering/deregistering clusters in compliance
with the
MemberCluster API. - The MCS API automatically generating
ServiceImport CRs
based on the MemberCluster CR defined within a fleet.
Moreover, it furnishes a user-friendly interface for human operators to monitor the managed clusters.
MemberCluster Lifecycle
Joining the Fleet
The process to join the Fleet involves creating a MemberCluster. The MemberCluster controller, a constituent of the
hub-cluster-agent described in the Component, watches the MemberCluster CR and generates
a corresponding namespace for the member cluster within the hub cluster. It configures roles and role bindings within the
hub cluster, authorizing the specified member cluster identity (as detailed in the MemberCluster spec) access solely
to resources within that namespace. To collate member cluster status, the controller generates another internal CR named
InternalMemberCluster within the newly formed namespace. Simultaneously, the InternalMemberCluster controller, a component
of the member-cluster-agent situated in the member cluster, gathers statistics on cluster usage, such as capacity utilization,
and reports its status based on the HeartbeatPeriodSeconds specified in the CR. Meanwhile, the MemberCluster controller
consolidates agent statuses and marks the cluster as Joined.
Leaving the Fleet
Fleet administrators can deregister a cluster by deleting the MemberCluster CR. Upon detection of deletion events by
the MemberCluster controller within the hub cluster, it removes the corresponding InternalMemberCluster CR in the
reserved namespace of the member cluster. It awaits completion of the “leave” process by the InternalMemberCluster
controller of member agents, and then deletes role and role bindings and other resources including the member cluster reserved
namespaces on the hub cluster.
Taints
Taints are a mechanism to prevent the Fleet Scheduler from scheduling resources to a MemberCluster. We adopt the concept of
taints and tolerations introduced in Kubernetes to
the multi-cluster use case.
The MemberCluster CR supports the specification of list of taints, which are applied to the MemberCluster. Each Taint object comprises
the following fields:
key: The key of the taint.value: The value of the taint.effect: The effect of the taint, which can be NoSchedule for now.
Once a MemberCluster is tainted with a specific taint, it lets the Fleet Scheduler know that the MemberCluster should not receive resources
as part of the workload propagation from the hub cluster.
The NoSchedule taint is a signal to the Fleet Scheduler to avoid scheduling resources from a ClusterResourcePlacement to the MemberCluster.
Any MemberCluster already selected for resource propagation will continue to receive resources even if a new taint is added.
Taints are only honored by ClusterResourcePlacement with PickAll, PickN placement policies. In the case of PickFixed placement policy
the taints are ignored because the user has explicitly specify the MemberClusters where the resources should be placed.
For detailed instructions, please refer to this document.
What’s next
1.3 - ClusterResourcePlacement
Concept about the ClusterResourcePlacement API
Overview
ClusterResourcePlacement concept is used to dynamically select cluster scoped resources (especially namespaces and all
objects within it) and control how they are propagated to all or a subset of the member clusters.
A ClusterResourcePlacement mainly consists of three parts:
Resource selection: select which cluster-scoped Kubernetes
resource objects need to be propagated from the hub cluster to selected member clusters.
It supports the following forms of resource selection:
- Select resources by specifying just the <group, version, kind>. This selection propagates all resources with matching <group, version, kind>.
- Select resources by specifying the <group, version, kind> and name. This selection propagates only one resource that matches the <group, version, kind> and name.
- Select resources by specifying the <group, version, kind> and a set of labels using ClusterResourcePlacement -> LabelSelector.
This selection propagates all resources that match the <group, version, kind> and label specified.
Note: When a namespace is selected, all the namespace-scoped objects under this namespace are propagated to the
selected member clusters along with this namespace.
Placement policy: limit propagation of selected resources to a specific subset of member clusters.
The following types of target cluster selection are supported:
- PickAll (Default): select any member clusters with matching cluster
Affinity scheduling rules. If the Affinity
is not specified, it will select all joined and healthy member clusters. - PickFixed: select a fixed list of member clusters defined in the
ClusterNames. - PickN: select a
NumberOfClusters of member clusters with optional matching cluster Affinity scheduling rules or topology spread constraints TopologySpreadConstraints.
Strategy: how changes are rolled out (rollout strategy) and how resources are applied on the member cluster side (apply strategy).
A simple ClusterResourcePlacement looks like this:
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: crp-1
spec:
policy:
placementType: PickN
numberOfClusters: 2
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "env"
whenUnsatisfiable: DoNotSchedule
resourceSelectors:
- group: ""
kind: Namespace
name: test-deployment
version: v1
revisionHistoryLimit: 100
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
unavailablePeriodSeconds: 5
type: RollingUpdate
When To Use ClusterResourcePlacement
ClusterResourcePlacement is useful when you want for a general way of managing and running workloads across multiple clusters.
Some example scenarios include the following:
- As a platform operator, I want to place my cluster-scoped resources (especially namespaces and all objects within it)
to a cluster that resides in the us-east-1.
- As a platform operator, I want to spread my cluster-scoped resources (especially namespaces and all objects within it)
evenly across the different regions/zones.
- As a platform operator, I prefer to place my test resources into the staging AKS cluster.
- As a platform operator, I would like to separate the workloads for compliance or policy reasons.
- As a developer, I want to run my cluster-scoped resources (especially namespaces and all objects within it) on 3 clusters.
In addition, each time I update my workloads, the updates take place with zero downtime by rolling out to these three clusters incrementally.
Placement Workflow
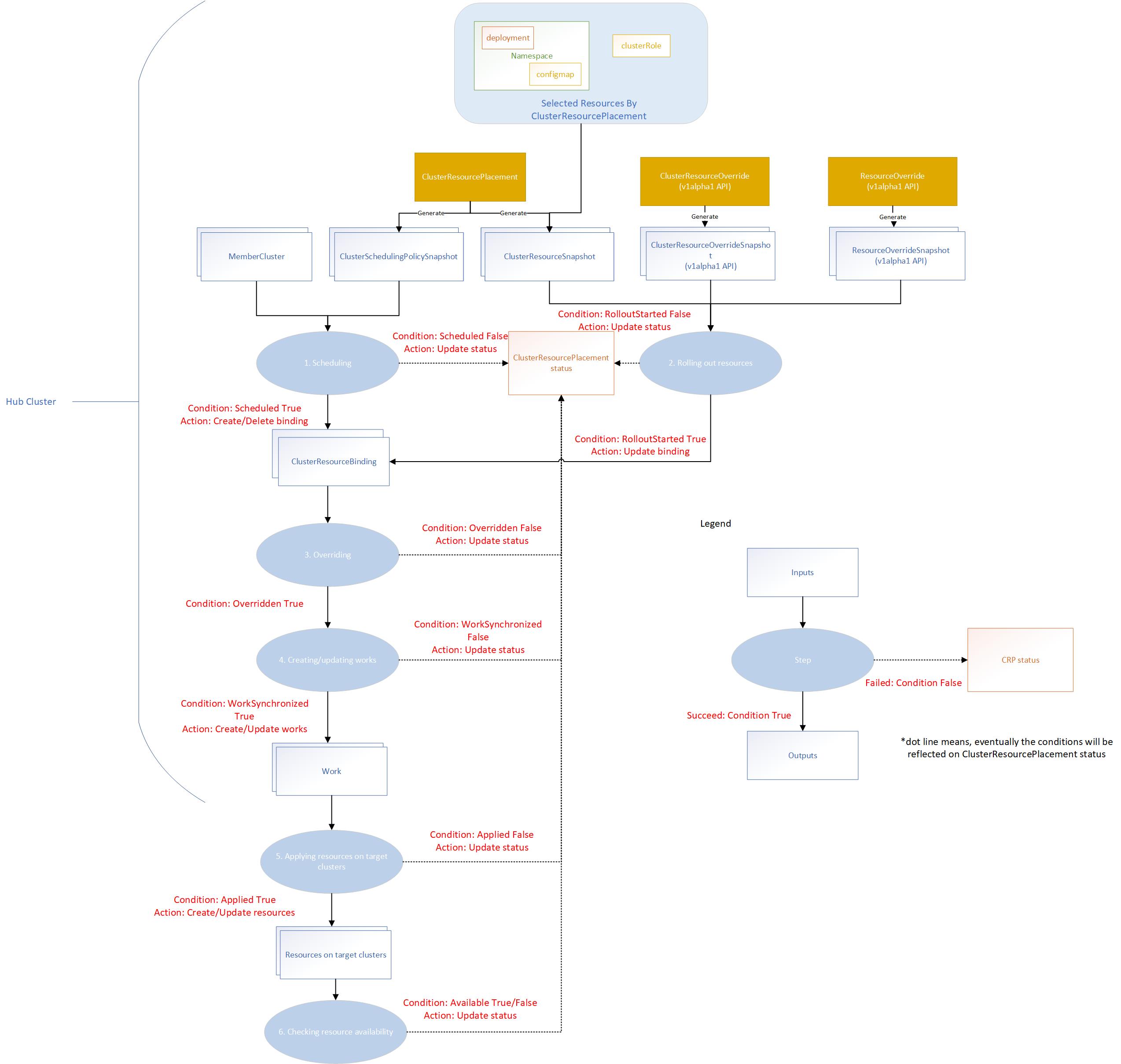
The placement controller will create ClusterSchedulingPolicySnapshot and ClusterResourceSnapshot snapshots by watching
the ClusterResourcePlacement object. So that it can trigger the scheduling and resource rollout process whenever needed.
The override controller will create the corresponding snapshots by watching the ClusterResourceOverride and ResourceOverride
which captures the snapshot of the overrides.
The placement workflow will be divided into several stages:
- Scheduling: multi-cluster scheduler makes the schedule decision by creating the
clusterResourceBinding for a bundle
of resources based on the latest ClusterSchedulingPolicySnapshotgenerated by the ClusterResourcePlacement. - Rolling out resources: rollout controller applies the resources to the selected member clusters based on the rollout strategy.
- Overriding: work generator applies the override rules defined by
ClusterResourceOverride and ResourceOverride to
the selected resources on the target clusters. - Creating or updating works: work generator creates the work on the corresponding member cluster namespace. Each work
contains the (overridden) manifest workload to be deployed on the member clusters.
- Applying resources on target clusters: apply work controller applies the manifest workload on the member clusters.
- Checking resource availability: apply work controller checks the resource availability on the target clusters.
Resource Selection
Resource selectors identify cluster-scoped objects to include based on standard Kubernetes identifiers - namely, the group,
kind, version, and name of the object. Namespace-scoped objects are included automatically when the namespace they
are part of is selected. The example ClusterResourcePlacement above would include the test-deployment namespace and
any objects that were created in that namespace.
The clusterResourcePlacement controller creates the ClusterResourceSnapshot to store a snapshot of selected resources
selected by the placement. The ClusterResourceSnapshot spec is immutable. Each time when the selected resources are updated,
the clusterResourcePlacement controller will detect the resource changes and create a new ClusterResourceSnapshot. It implies
that resources can change independently of any modifications to the ClusterResourceSnapshot. In other words, resource
changes can occur without directly affecting the ClusterResourceSnapshot itself.
The total amount of selected resources may exceed the 1MB limit for a single Kubernetes object. As a result, the controller
may produce more than one ClusterResourceSnapshots for all the selected resources.
ClusterResourceSnapshot sample:
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourceSnapshot
metadata:
annotations:
kubernetes-fleet.io/number-of-enveloped-object: "0"
kubernetes-fleet.io/number-of-resource-snapshots: "1"
kubernetes-fleet.io/resource-hash: e0927e7d75c7f52542a6d4299855995018f4a6de46edf0f814cfaa6e806543f3
creationTimestamp: "2023-11-10T08:23:38Z"
generation: 1
labels:
kubernetes-fleet.io/is-latest-snapshot: "true"
kubernetes-fleet.io/parent-CRP: crp-1
kubernetes-fleet.io/resource-index: "4"
name: crp-1-4-snapshot
ownerReferences:
- apiVersion: placement.kubernetes-fleet.io/v1
blockOwnerDeletion: true
controller: true
kind: ClusterResourcePlacement
name: crp-1
uid: 757f2d2c-682f-433f-b85c-265b74c3090b
resourceVersion: "1641940"
uid: d6e2108b-882b-4f6c-bb5e-c5ec5491dd20
spec:
selectedResources:
- apiVersion: v1
kind: Namespace
metadata:
labels:
kubernetes.io/metadata.name: test
name: test
spec:
finalizers:
- kubernetes
- apiVersion: v1
data:
key1: value1
key2: value2
key3: value3
kind: ConfigMap
metadata:
name: test-1
namespace: test
Placement Policy
ClusterResourcePlacement supports three types of policy as mentioned above. ClusterSchedulingPolicySnapshot will be
generated whenever policy changes are made to the ClusterResourcePlacement that require a new scheduling. Similar to
ClusterResourceSnapshot, its spec is immutable.
ClusterSchedulingPolicySnapshot sample:
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterSchedulingPolicySnapshot
metadata:
annotations:
kubernetes-fleet.io/CRP-generation: "5"
kubernetes-fleet.io/number-of-clusters: "2"
creationTimestamp: "2023-11-06T10:22:56Z"
generation: 1
labels:
kubernetes-fleet.io/is-latest-snapshot: "true"
kubernetes-fleet.io/parent-CRP: crp-1
kubernetes-fleet.io/policy-index: "1"
name: crp-1-1
ownerReferences:
- apiVersion: placement.kubernetes-fleet.io/v1
blockOwnerDeletion: true
controller: true
kind: ClusterResourcePlacement
name: crp-1
uid: 757f2d2c-682f-433f-b85c-265b74c3090b
resourceVersion: "1639412"
uid: 768606f2-aa5a-481a-aa12-6e01e6adbea2
spec:
policy:
placementType: PickN
policyHash: NDc5ZjQwNWViNzgwOGNmYzU4MzY2YjI2NDg2ODBhM2E4MTVlZjkxNGZlNjc1NmFlOGRmMGQ2Zjc0ODg1NDE2YQ==
status:
conditions:
- lastTransitionTime: "2023-11-06T10:22:56Z"
message: found all the clusters needed as specified by the scheduling policy
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: Scheduled
observedCRPGeneration: 5
targetClusters:
- clusterName: aks-member-1
clusterScore:
affinityScore: 0
priorityScore: 0
reason: picked by scheduling policy
selected: true
- clusterName: aks-member-2
clusterScore:
affinityScore: 0
priorityScore: 0
reason: picked by scheduling policy
selected: true
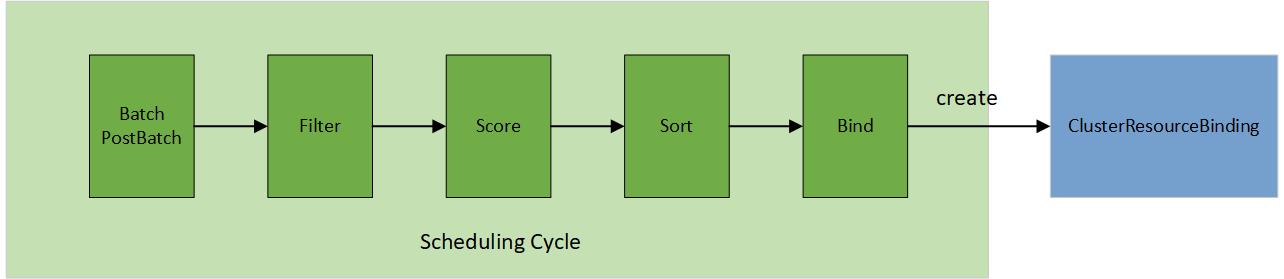
In contrast to the original scheduler framework in Kubernetes, the multi-cluster scheduling process involves selecting a cluster for placement through a structured 5-step operation:
- Batch & PostBatch
- Filter
- Score
- Sort
- Bind
The batch & postBatch step is to define the batch size according to the desired and current ClusterResourceBinding.
The postBatch is to adjust the batch size if needed.
The filter step finds the set of clusters where it’s feasible to schedule the placement, for example, whether the cluster
is matching required Affinity scheduling rules specified in the Policy. It also filters out any clusters which are
leaving the fleet or no longer connected to the fleet, for example, its heartbeat has been stopped for a prolonged period of time.
In the score step (only applied to the pickN type), the scheduler assigns a score to each cluster that survived filtering.
Each cluster is given a topology spread score (how much a cluster would satisfy the topology spread
constraints specified by the user), and an affinity score (how much a cluster would satisfy the preferred affinity terms
specified by the user).
In the sort step (only applied to the pickN type), it sorts all eligible clusters by their scores, sorting first by topology
spread score and breaking ties based on the affinity score.
The bind step is to create/update/delete the ClusterResourceBinding based on the desired and current member cluster list.
Strategy
Rollout strategy
Use rollout strategy to control how KubeFleet rolls out a resource change made on the hub cluster to all member clusters.
Right now KubeFleet supports two types of rollout strategies out of the box:
- Rolling update: this rollout strategy helps roll out changes incrementally in a way that ensures system
availability, akin to how the Kubernetes Deployment API handles updates. For more information, see the
Safe Rollout concept.
- Staged update: this rollout strategy helps roll out changes in different stages; users may group clusters
into different stages and specify the order in which each stage receives the update. The strategy also allows
users to set up timed or approval-based gates between stages to fine-control the flow. For more information, see
the Staged Update concept and Staged Update How-To Guide.
Apply strategy
Use apply strategy to control how KubeFleet applies a resource to a member cluster. KubeFleet currently features
three different types of apply strategies:
- Client-side apply: this apply strategy sets up KubeFleet to apply resources in a three-way merge that is similar to how
the Kubernetes CLI,
kubectl, performs client-side apply. - Server-side apply: this apply strategy sets up KubeFleet to apply resources via the new server-side apply mechanism.
- Report Diff mode: this apply strategy instructs KubeFleet to check for configuration differences between the resource
on the hub cluster and its counterparts among the member clusters; no apply op will be performed. For more information,
see the ReportDiff Mode How-To Guide.
To learn more about the differences between client-side apply and server-side apply, see also the
Kubernetes official documentation.
KubeFleet apply strategy is also the place where users can set up KubeFleet’s drift detection capabilities and takeover
settings:
- Drift detection helps users identify and resolve configuration drifts that are commonly observed in a multi-cluster
environment; through this feature, KubeFleet can detect the presence of drifts, reveal their details, and let users
decide how and when to handle them. See the Drift Detection How-To Guide for more
information.
- Takeover settings allows users to decide how KubeFleet can best handle pre-existing resources. When you join a cluster
with running workloads into a fleet, these settings can help bring the workloads under KubeFleet’s management in a
way that avoids interruptions. For specifics, see the Takeover Settings How-To Guide.
Placement status
After a ClusterResourcePlacement is created, details on current status can be seen by performing a kubectl describe crp <name>.
The status output will indicate both placement conditions and individual placement statuses on each member cluster that was selected.
The list of resources that are selected for placement will also be included in the describe output.
Sample output:
Name: crp-1
Namespace:
Labels: <none>
Annotations: <none>
API Version: placement.kubernetes-fleet.io/v1
Kind: ClusterResourcePlacement
Metadata:
...
Spec:
Policy:
Placement Type: PickAll
Resource Selectors:
Group:
Kind: Namespace
Name: application-1
Version: v1
Revision History Limit: 10
Strategy:
Rolling Update:
Max Surge: 25%
Max Unavailable: 25%
Unavailable Period Seconds: 2
Type: RollingUpdate
Status:
Conditions:
Last Transition Time: 2024-04-29T09:58:20Z
Message: found all the clusters needed as specified by the scheduling policy
Observed Generation: 1
Reason: SchedulingPolicyFulfilled
Status: True
Type: ClusterResourcePlacementScheduled
Last Transition Time: 2024-04-29T09:58:20Z
Message: All 3 cluster(s) start rolling out the latest resource
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: ClusterResourcePlacementRolloutStarted
Last Transition Time: 2024-04-29T09:58:20Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: ClusterResourcePlacementOverridden
Last Transition Time: 2024-04-29T09:58:20Z
Message: Works(s) are succcesfully created or updated in the 3 target clusters' namespaces
Observed Generation: 1
Reason: WorkSynchronized
Status: True
Type: ClusterResourcePlacementWorkSynchronized
Last Transition Time: 2024-04-29T09:58:20Z
Message: The selected resources are successfully applied to 3 clusters
Observed Generation: 1
Reason: ApplySucceeded
Status: True
Type: ClusterResourcePlacementApplied
Last Transition Time: 2024-04-29T09:58:20Z
Message: The selected resources in 3 cluster are available now
Observed Generation: 1
Reason: ResourceAvailable
Status: True
Type: ClusterResourcePlacementAvailable
Observed Resource Index: 0
Placement Statuses:
Cluster Name: kind-cluster-1
Conditions:
Last Transition Time: 2024-04-29T09:58:20Z
Message: Successfully scheduled resources for placement in kind-cluster-1 (affinity score: 0, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2024-04-29T09:58:20Z
Message: Detected the new changes on the resources and started the rollout process
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: RolloutStarted
Last Transition Time: 2024-04-29T09:58:20Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: Overridden
Last Transition Time: 2024-04-29T09:58:20Z
Message: All of the works are synchronized to the latest
Observed Generation: 1
Reason: AllWorkSynced
Status: True
Type: WorkSynchronized
Last Transition Time: 2024-04-29T09:58:20Z
Message: All corresponding work objects are applied
Observed Generation: 1
Reason: AllWorkHaveBeenApplied
Status: True
Type: Applied
Last Transition Time: 2024-04-29T09:58:20Z
Message: The availability of work object crp-1-work is not trackable
Observed Generation: 1
Reason: WorkNotTrackable
Status: True
Type: Available
Cluster Name: kind-cluster-2
Conditions:
Last Transition Time: 2024-04-29T09:58:20Z
Message: Successfully scheduled resources for placement in kind-cluster-2 (affinity score: 0, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2024-04-29T09:58:20Z
Message: Detected the new changes on the resources and started the rollout process
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: RolloutStarted
Last Transition Time: 2024-04-29T09:58:20Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: Overridden
Last Transition Time: 2024-04-29T09:58:20Z
Message: All of the works are synchronized to the latest
Observed Generation: 1
Reason: AllWorkSynced
Status: True
Type: WorkSynchronized
Last Transition Time: 2024-04-29T09:58:20Z
Message: All corresponding work objects are applied
Observed Generation: 1
Reason: AllWorkHaveBeenApplied
Status: True
Type: Applied
Last Transition Time: 2024-04-29T09:58:20Z
Message: The availability of work object crp-1-work is not trackable
Observed Generation: 1
Reason: WorkNotTrackable
Status: True
Type: Available
Cluster Name: kind-cluster-3
Conditions:
Last Transition Time: 2024-04-29T09:58:20Z
Message: Successfully scheduled resources for placement in kind-cluster-3 (affinity score: 0, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2024-04-29T09:58:20Z
Message: Detected the new changes on the resources and started the rollout process
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: RolloutStarted
Last Transition Time: 2024-04-29T09:58:20Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: Overridden
Last Transition Time: 2024-04-29T09:58:20Z
Message: All of the works are synchronized to the latest
Observed Generation: 1
Reason: AllWorkSynced
Status: True
Type: WorkSynchronized
Last Transition Time: 2024-04-29T09:58:20Z
Message: All corresponding work objects are applied
Observed Generation: 1
Reason: AllWorkHaveBeenApplied
Status: True
Type: Applied
Last Transition Time: 2024-04-29T09:58:20Z
Message: The availability of work object crp-1-work is not trackable
Observed Generation: 1
Reason: WorkNotTrackable
Status: True
Type: Available
Selected Resources:
Kind: Namespace
Name: application-1
Version: v1
Kind: ConfigMap
Name: app-config-1
Namespace: application-1
Version: v1
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal PlacementRolloutStarted 3m46s cluster-resource-placement-controller Started rolling out the latest resources
Normal PlacementOverriddenSucceeded 3m46s cluster-resource-placement-controller Placement has been successfully overridden
Normal PlacementWorkSynchronized 3m46s cluster-resource-placement-controller Work(s) have been created or updated successfully for the selected cluster(s)
Normal PlacementApplied 3m46s cluster-resource-placement-controller Resources have been applied to the selected cluster(s)
Normal PlacementRolloutCompleted 3m46s cluster-resource-placement-controller Resources are available in the selected clusters
ClusterResourcePlacementStatus
The ClusterResourcePlacementStatus (CRPS) is a namespaced resource that mirrors the PlacementStatus of a corresponding cluster-scoped ClusterResourcePlacement (CRP) object. It provides namespace-scoped access to cluster-scoped placement status information.
- Namespace-scoped access: Allows users with namespace-level permissions to view placement status without requiring cluster-scoped access
- Status mirroring: Contains the same placement status information as the parent CRP, but accessible within a specific namespace
- Optional feature: Only created when
StatusReportingScope is set to NamespaceAccessible. Once set, StatusReportingScope is immutable.
When StatusReportingScope is set to NamespaceAccessible for aClusterResourcePlacement, only one namespace resource selector is allowed, and it is immutable. Therefore, the namespace resource selector cannot be changed after creation.
For detailed instructions, please refer to this document.
Advanced Features
Tolerations
Tolerations are a mechanism to allow the Fleet Scheduler to schedule resources to a MemberCluster that has taints specified on it.
We adopt the concept of taints & tolerations
introduced in Kubernetes to the multi-cluster use case.
The ClusterResourcePlacement CR supports the specification of list of tolerations, which are applied to the ClusterResourcePlacement
object. Each Toleration object comprises the following fields:
key: The key of the toleration.value: The value of the toleration.effect: The effect of the toleration, which can be NoSchedule for now.operator: The operator of the toleration, which can be Exists or Equal.
Each toleration is used to tolerate one or more specific taints applied on the MemberCluster. Once all taints on a MemberCluster
are tolerated by tolerations on a ClusterResourcePlacement, resources can be propagated to the MemberCluster by the scheduler for that
ClusterResourcePlacement resource.
Tolerations cannot be updated or removed from a ClusterResourcePlacement. If there is a need to update toleration a better approach is to
add another toleration. If we absolutely need to update or remove existing tolerations, the only option is to delete the existing ClusterResourcePlacement
and create a new object with the updated tolerations.
For detailed instructions, please refer to this document.
Envelope Object
The ClusterResourcePlacement leverages the fleet hub cluster as a staging environment for customer resources. These resources are then propagated to member clusters that are part of the fleet, based on the ClusterResourcePlacement spec.
In essence, the objective is not to apply or create resources on the hub cluster for local use but to propagate these resources to other member clusters within the fleet.
Certain resources, when created or applied on the hub cluster, may lead to unintended side effects. These include:
- Validating/Mutating Webhook Configurations
- Cluster Role Bindings
- Resource Quotas
- Storage Classes
- Flow Schemas
- Priority Classes
- Ingress Classes
- Ingresses
- Network Policies
To address this, we support the use of ConfigMap with a fleet-reserved annotation. This allows users to encapsulate resources that might have side effects on the hub cluster within the ConfigMap. For detailed instructions, please refer to this document.
1.4 - ResourcePlacement
Concept about the ResourcePlacement API
Overview
ResourcePlacement is a namespace-scoped API that enables dynamic selection and multi-cluster propagation of namespace-scoped resources. It provides fine-grained control over how specific resources within a namespace are distributed across member clusters in a fleet.
Key Characteristics:
- Namespace-scoped: Both the ResourcePlacement object and the resources it manages exist within the same namespace
- Selective: Can target specific resources by type, name, or labels rather than entire namespaces
- Declarative: Uses the same placement patterns as ClusterResourcePlacement for consistent behavior
A ResourcePlacement consists of three core components:
- Resource Selectors: Define which namespace-scoped resources to include
- Placement Policy: Determine target clusters using PickAll, PickFixed, or PickN strategies
- Rollout Strategy: Control how changes propagate across selected clusters
For detailed examples and implementation guidance, see the ResourcePlacement How-To Guide.
Motivation
In multi-cluster environments, workloads often consist of both cluster-scoped and namespace-scoped resources that need to be distributed across different clusters. While ClusterResourcePlacement (CRP) handles cluster-scoped resources effectively, particularly entire namespaces and their contents, there are scenarios where you need more granular control over namespace-scoped resources within existing namespaces.
ResourcePlacement (RP) was designed to address this gap by providing:
- Namespace-scoped resource management: Target specific resources within a namespace without affecting the entire namespace
- Operational flexibility: Allow a team to manage different resources within the same namespace independently
- Complementary functionality: Work alongside CRP to provide a complete multi-cluster resource management solution
Note: ResourcePlacement can be used together with ClusterResourcePlacement in namespace-only mode. For example, you can use CRP to deploy the namespace, while using RP for fine-grained management of specific resources like environment-specific ConfigMaps or Secrets within that namespace.
Addressing Real-World Namespace Usage Patterns
While CRP assumes that namespaces represent application boundaries, real-world usage patterns are often more complex. Organizations frequently use namespaces as team boundaries rather than application boundaries, leading to several challenges that ResourcePlacement directly addresses:
Multi-Application Namespaces: In many organizations, a single namespace contains multiple independent applications owned by the same team. These applications may have:
- Different lifecycle requirements (one application may need frequent updates while another remains stable)
- Different cluster placement needs (development vs. production applications)
- Independent scaling and resource requirements
- Separate compliance or governance requirements
Individual Scheduling Decisions: Many workloads, particularly AI/ML jobs, require individual scheduling decisions:
- AI Jobs: Machine learning workloads often consist of short-lived, resource-intensive jobs that need to be scheduled based on cluster resource availability, GPU availability, or data locality
- Batch Workloads: Different batch jobs within the same namespace may target different cluster types based on computational requirements
Complete Application Team Control: ResourcePlacement provides application teams with direct control over their resource placement without requiring platform team intervention:
- Self-Service Operations: Teams can manage their own resource distribution strategies
- Independent Deployment Cycles: Different applications within a namespace can have completely independent rollout schedules
- Granular Override Capabilities: Teams can customize resource configurations per cluster without affecting other applications in the namespace
This granular approach ensures that ResourcePlacement can adapt to diverse organizational structures and workload patterns while maintaining the simplicity and power of the Fleet scheduling framework.
Key Differences Between ResourcePlacement and ClusterResourcePlacement
| Aspect | ResourcePlacement (RP) | ClusterResourcePlacement (CRP) |
|---|
| Scope | Namespace-scoped resources only | Cluster-scoped resources (especially namespaces and their contents) |
| Resource | Namespace-scoped API object | Cluster-scoped API object |
| Selection Boundary | Limited to resources within the same namespace as the RP | Can select any cluster-scoped resource |
| Typical Use Cases | AI/ML Jobs, individual workloads, specific ConfigMaps/Secrets that need independent placement decisions | Application bundles, entire namespaces, cluster-wide policies |
| Team Ownership | Can be managed by namespace owners/developers | Typically managed by platform operators |
Similarities Between ResourcePlacement and ClusterResourcePlacement
Both RP and CRP share the same core concepts and capabilities:
- Placement Policies: Same three placement types (PickAll, PickFixed, PickN) with identical scheduling logic
- Resource Selection: Both support selection by group/version/kind, name, and label selectors
- Rollout Strategy: Identical rolling update mechanisms for zero-downtime deployments
- Scheduling Framework: Use the same multi-cluster scheduler with filtering, scoring, and binding phases
- Override Support: Both integrate with ClusterResourceOverride and ResourceOverride for resource customization
- Status Reporting: Similar status structures and condition types for placement tracking
- Tolerations: Same taints and tolerations mechanism for cluster selection
- Snapshot Architecture: Both use immutable snapshots (ResourceSnapshot vs ClusterResourceSnapshot) for resource and policy tracking
This design allows teams familiar with one placement object to easily understand and use the other, while providing the appropriate level of control for different resource scopes.
When To Use ResourcePlacement
ResourcePlacement is ideal for scenarios requiring granular control over namespace-scoped resources:
- Selective Resource Distribution: Deploy specific ConfigMaps, Secrets, or Services without affecting the entire namespace
- Multi-tenant Environments: Allow different teams to manage their resources independently within shared namespaces
- Configuration Management: Distribute environment-specific configurations across different cluster environments
- Compliance and Governance: Apply different policies to different resource types within the same namespace
- Progressive Rollouts: Safely deploy resource updates across clusters with zero-downtime strategies
For practical examples and step-by-step instructions, see the ResourcePlacement How-To Guide.
Working with ClusterResourcePlacement
ResourcePlacement is designed to work in coordination with ClusterResourcePlacement (CRP) to provide a complete multi-cluster resource management solution. Understanding this relationship is crucial for effective fleet management.
Namespace Prerequisites
Important: ResourcePlacement can only place namespace-scoped resources to clusters that already have the target namespace. This creates a fundamental dependency on ClusterResourcePlacement for namespace establishment.
Typical Workflow:
- Fleet Admin: Uses ClusterResourcePlacement to deploy namespaces across the fleet
- Application Teams: Use ResourcePlacement to manage specific resources within those established namespaces
# Fleet admin creates namespace using CRP
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: app-namespace-crp
spec:
resourceSelectors:
- group: ""
kind: Namespace
name: my-app
version: v1
selectionScope: NamespaceOnly # only namespace itself is placed, no resources within the namespace
policy:
placementType: PickAll
---
# Application team manages resources using RP
apiVersion: placement.kubernetes-fleet.io/v1
kind: ResourcePlacement
metadata:
name: app-configs-rp
namespace: my-app
spec:
resourceSelectors:
- group: ""
kind: ConfigMap
version: v1
labelSelector:
matchLabels:
app: my-application
policy:
placementType: PickFixed
clusterNames: ["prod-cluster-1", "prod-cluster-2"]
Best Practices
- Establish Namespaces First: Always ensure namespaces are deployed via CRP before creating ResourcePlacement objects
- Monitor Dependencies: Use Fleet monitoring to ensure namespace-level CRPs are healthy before deploying dependent RPs
- Coordinate Policies: Align CRP and RP placement policies to avoid conflicts (e.g., if CRP places namespace on clusters A,B,C, RP can target any subset of those clusters)
- Team Boundaries: Use CRP for platform-managed resources (namespaces, RBAC) and RP for application-managed resources (app configs, secrets)
This coordinated approach ensures that ResourcePlacement provides the flexibility teams need while maintaining the foundational infrastructure managed by platform operators.
Core Concepts
ResourcePlacement orchestrates multi-cluster resource distribution through a coordinated system of controllers and snapshots that work together to ensure consistent, reliable deployments.
The Complete Flow
When you create a ResourcePlacement, the system initiates a multi-stage process:
- Resource Selection & Snapshotting: The placement controller identifies resources matching your selectors and creates immutable
ResourceSnapshot objects capturing their current state - Policy Evaluation & Snapshotting: Placement policies are evaluated and captured in
SchedulingPolicySnapshot objects to ensure stable scheduling decisions - Multi-Cluster Scheduling: The scheduler processes policy snapshots to determine target clusters through filtering, scoring, and selection
- Resource Binding: Selected clusters are bound to specific resource snapshots via
ResourceBinding objects - Rollout Execution: The rollout controller applies resources to target clusters according to the rollout strategy
- Override Processing: Environment-specific customizations are applied through override controllers
- Work Generation: Individual
Work objects are created for each target cluster containing the final resource manifests - Cluster Application: Work controllers on member clusters apply the resources locally and report status back
Status and Observability
ResourcePlacement provides comprehensive status reporting to track deployment progress:
- Overall Status: High-level conditions indicating scheduling, rollout, and availability states
- Per-Cluster Status: Individual status for each target cluster showing detailed progress
- Events: Timeline of placement activities and any issues encountered
Status information helps operators understand deployment progress, troubleshoot issues, and ensure resources are successfully propagated across the fleet.
For detailed troubleshooting guidance, see the ResourcePlacement Troubleshooting Guide.
Advanced Features
ResourcePlacement supports the same advanced features as ClusterResourcePlacement. For detailed documentation on these features, see the corresponding sections in the ClusterResourcePlacement Concept Guide - Advanced Features.
1.5 - Scheduler
Concept about the Fleet scheduler
The scheduler component is a vital element in Fleet workload scheduling. Its primary responsibility is to determine the
schedule decision for a bundle of resources based on the latest ClusterSchedulingPolicySnapshotgenerated by the ClusterResourcePlacement.
By default, the scheduler operates in batch mode, which enhances performance. In this mode, it binds a ClusterResourceBinding
from a ClusterResourcePlacement to multiple clusters whenever possible.
Batch in nature
Scheduling resources within a ClusterResourcePlacement involves more dependencies compared with scheduling pods within
a deployment in Kubernetes. There are two notable distinctions:
- In a
ClusterResourcePlacement, multiple replicas of resources cannot be scheduled on the same cluster, whereas pods
belonging to the same deployment in Kubernetes can run on the same node. - The
ClusterResourcePlacement supports different placement types within a single object.
These requirements necessitate treating the scheduling policy as a whole and feeding it to the scheduler, as opposed to
handling individual pods like Kubernetes today. Specially:
- Scheduling the entire
ClusterResourcePlacement at once enables us to increase the parallelism of the scheduler if
needed. - Supporting the
PickAll mode would require generating the replica for each cluster in the fleet to scheduler. This
approach is not only inefficient but can also result in scheduler repeatedly attempting to schedule unassigned replica when
there are no possibilities of placing them. - To support the
PickN mode, the scheduler needs to compute the filtering and scoring for each replica. Conversely,
in batch mode, these calculations are performed once. Scheduler sorts all the eligible clusters and pick the top N clusters.
Placement Decisions
The output of the scheduler is an array of ClusterResourceBindings on the hub cluster.
ClusterResourceBinding sample:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourceBinding
metadata:
annotations:
kubernetes-fleet.io/previous-binding-state: Bound
creationTimestamp: "2023-11-06T09:53:11Z"
finalizers:
- kubernetes-fleet.io/work-cleanup
generation: 8
labels:
kubernetes-fleet.io/parent-CRP: crp-1
name: crp-1-aks-member-1-2f8fe606
resourceVersion: "1641949"
uid: 3a443dec-a5ad-4c15-9c6d-05727b9e1d15
spec:
clusterDecision:
clusterName: aks-member-1
clusterScore:
affinityScore: 0
priorityScore: 0
reason: picked by scheduling policy
selected: true
resourceSnapshotName: crp-1-4-snapshot
schedulingPolicySnapshotName: crp-1-1
state: Bound
targetCluster: aks-member-1
status:
conditions:
- lastTransitionTime: "2023-11-06T09:53:11Z"
message: ""
observedGeneration: 8
reason: AllWorkSynced
status: "True"
type: Bound
- lastTransitionTime: "2023-11-10T08:23:38Z"
message: ""
observedGeneration: 8
reason: AllWorkHasBeenApplied
status: "True"
type: Applied
ClusterResourceBinding can have three states:
- Scheduled: It indicates that the scheduler has selected this cluster for placing the resources. The resource is waiting
to be picked up by the rollout controller.
- Bound: It indicates that the rollout controller has initiated the placement of resources on the target cluster. The
resources are actively being deployed.
- Unscheduled: This states signifies that the target cluster is no longer selected by the scheduler for the placement.
The resource associated with this cluster are in the process of being removed. They are awaiting deletion from the cluster.
The scheduler operates by generating scheduling decisions through the creating of new bindings in the “scheduled” state
and the removal of existing bindings by marking them as “unscheduled”. There is a separate rollout controller which is
responsible for executing these decisions based on the defined rollout strategy.
Enforcing the semantics of “IgnoreDuringExecutionTime”
The ClusterResourcePlacement enforces the semantics of “IgnoreDuringExecutionTime” to prioritize the stability of resources
running in production. Therefore, the resources should not be moved or rescheduled without explicit changes to the scheduling
policy.
Here are some high-level guidelines outlining the actions that trigger scheduling and corresponding behavior:
Policy changes trigger scheduling:
- The scheduler makes the placement decisions based on the latest
ClusterSchedulingPolicySnapshot. - When it’s just a scale out operation (
NumberOfClusters of pickN mode is increased), the ClusterResourcePlacement
controller updates the label of the existing ClusterSchedulingPolicySnapshot instead of creating a new one, so that
the scheduler won’t move any existing resources that are already scheduled and just fulfill the new requirement.
The following cluster changes trigger scheduling:
- a cluster, originally ineligible for resource placement for some reason, becomes eligible, such as:
- the cluster setting changes, specifically
MemberCluster labels has changed - an unexpected deployment which originally leads the scheduler to discard the cluster (for example, agents not joining,
networking issues, etc.) has been resolved
- a cluster, originally eligible for resource placement, is leaving the fleet and becomes ineligible
Note: The scheduler is only going to place the resources on the new cluster and won’t touch the existing clusters.
Resource-only changes do not trigger scheduling including:
ResourceSelectors is updated in the ClusterResourcePlacement spec.- The selected resources is updated without directly affecting the
ClusterResourcePlacement.
What’s next
1.6 - Scheduling Framework
Concept about the Fleet scheduling framework
The fleet scheduling framework closely aligns with the native Kubernetes scheduling framework,
incorporating several modifications and tailored functionalities.
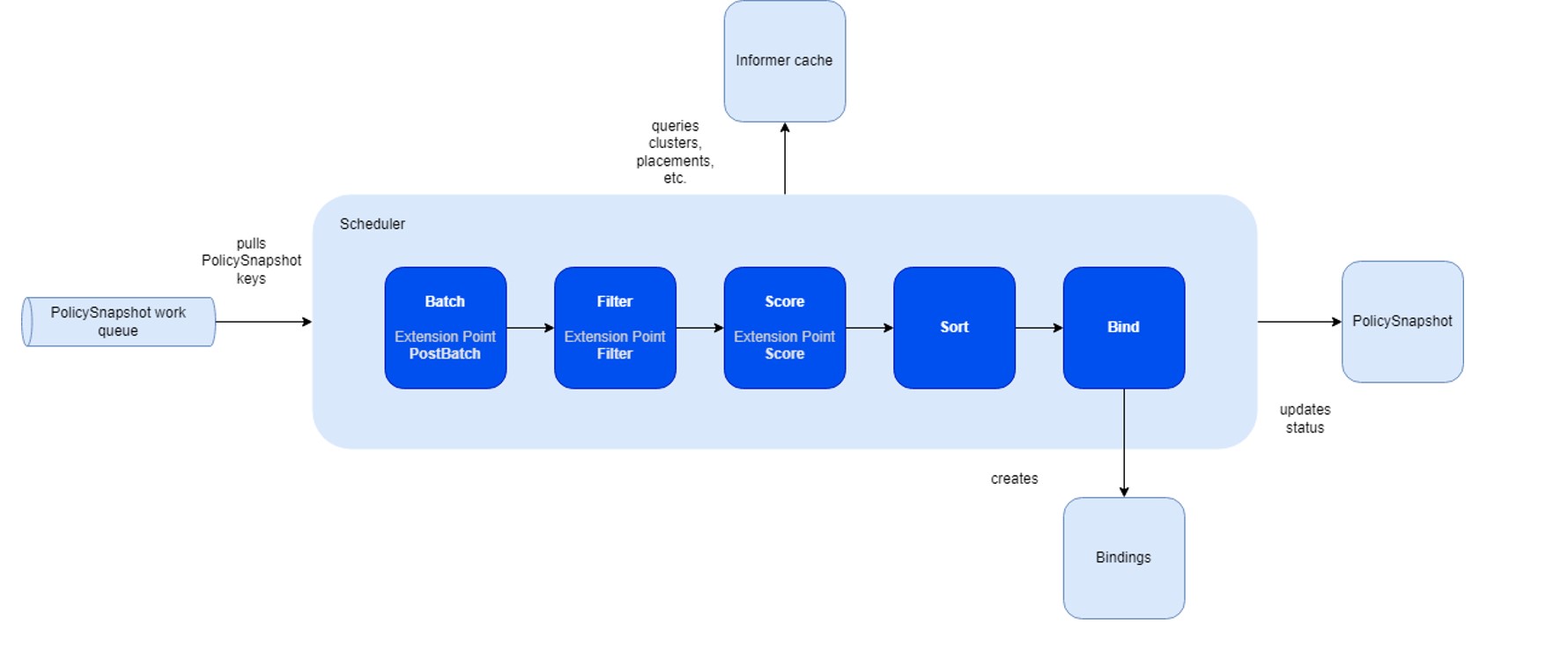
The primary advantage of this framework lies in its capability to compile plugins directly into the scheduler. Its API
facilitates the implementation of diverse scheduling features as plugins, thereby ensuring a lightweight and maintainable
core.
The fleet scheduler integrates three fundamental built-in plugin types:
- Topology Spread Plugin: Supports the TopologySpreadConstraints stipulated in the placement policy.
- Cluster Affinity Plugin: Facilitates the Affinity clause of the placement policy.
- Same Placement Affinity Plugin: Uniquely designed for the fleet, preventing multiple replicas (selected resources) from
being placed within the same cluster. This distinguishes it from Kubernetes, which allows multiple pods on a node.
- Cluster Eligibility Plugin: Enables cluster selection based on specific status criteria.
- Taint & Toleration Plugin: Enables cluster selection based on taints on the cluster & tolerations on the ClusterResourcePlacement.
Compared to the Kubernetes scheduling framework, the fleet framework introduces additional stages for the pickN placement type:
- Batch & PostBatch:
- Batch: Defines the batch size based on the desired and current
ClusterResourceBinding. - PostBatch: Adjusts the batch size as necessary. Unlike the Kubernetes scheduler, which schedules pods individually (batch size = 1).
- Sort:
- Fleet’s sorting mechanism selects a number of clusters, whereas Kubernetes’ scheduler prioritizes nodes with the highest scores.
To streamline the scheduling framework, certain stages, such as permit and reserve, have been omitted due to the absence
of corresponding plugins or APIs enabling customers to reserve or permit clusters for specific placements. However, the
framework remains designed for easy extension in the future to accommodate these functionalities.
In-tree plugins
The scheduler includes default plugins, each associated with distinct extension points:
| Plugin | PostBatch | Filter | Score |
|---|
| Cluster Affinity | ❌ | ✅ | ✅ |
| Same Placement Anti-affinity | ❌ | ✅ | ❌ |
| Topology Spread Constraints | ✅ | ✅ | ✅ |
| Cluster Eligibility | ❌ | ✅ | ❌ |
| Taint & Toleration | ❌ | ✅ | ❌ |
The Cluster Affinity Plugin serves as an illustrative example and operates within the following extension points:
- PreFilter:
Verifies whether the policy contains any required cluster affinity terms. If absent, the plugin bypasses the subsequent
Filter stage.
- Filter:
Filters out clusters that fail to meet the specified required cluster affinity terms outlined in the policy.
- PreScore:
Determines if the policy includes any preferred cluster affinity terms. If none are found, this plugin will be skipped
during the Score stage.
- Score:
Assigns affinity scores to clusters based on compliance with the preferred cluster affinity terms stipulated in the policy.
1.7 - Properties and Property Providers
Concept about cluster properties and property providers
This document explains the concepts of property provider and cluster properties in Fleet.
Fleet allows developers to implement a property provider to expose arbitrary properties about
a member cluster, such as its node count and available resources for workload placement. Platforms
could also enable their property providers to expose platform-specific properties via Fleet.
These properties can be useful in a variety of cases: for example, administrators could monitor the
health of a member cluster using related properties; Fleet also supports making scheduling
decisions based on the property data.
Property provider
A property provider implements Fleet’s property provider interface:
// PropertyProvider is the interface that every property provider must implement.
type PropertyProvider interface {
// Collect is called periodically by the Fleet member agent to collect properties.
//
// Note that this call should complete promptly. Fleet member agent will cancel the
// context if the call does not complete in time.
Collect(ctx context.Context) PropertyCollectionResponse
// Start is called when the Fleet member agent starts up to initialize the property provider.
// This call should not block.
//
// Note that Fleet member agent will cancel the context when it exits.
Start(ctx context.Context, config *rest.Config) error
}
For the details, see the Fleet source code.
A property provider should be shipped as a part of the Fleet member agent and run alongside it.
Refer to the Fleet source code
for specifics on how to set it up with the Fleet member agent.
At this moment, only one property provider can be set up with the Fleet member agent at a time.
Once connected, the Fleet member agent will attempt to start it when
the agent itself initializes; the agent will then start collecting properties from the
property provider periodically.
A property provider can expose two types of properties: resource properties, and non-resource
properties. To learn about the two types, see the section below. In addition, the provider can
choose to report its status, such as any errors encountered when preparing the properties,
in the form of Kubernetes conditions.
The Fleet member agent can run with or without a property provider. If a provider is not set up, or
the given provider fails to start properly, the agent will collect limited properties about
the cluster on its own, specifically the node count, plus the total/allocatable
CPU and memory capacities of the host member cluster.
Cluster properties
A cluster property is an attribute of a member cluster. There are two types of properties:
Resource property: the usage information of a resource in a member cluster, which consists of:
the total capacity of the resource, which is the amount of the resource
installed in the cluster;
the allocatable capacity of the resource, which is the maximum amount of the resource
that can be used for running user workloads, as some amount of the resource might be
reserved by the OS, kubelet, etc.;
the available capacity of the resource, which is the amount of the resource that
is currently free for running user workloads.
Note that you may report a virtual resource via the property provider, if applicable.
Non-resource property: a value that describes a member cluster.
A property is uniquely identified by its name, which is formatted as a string of one or more
segments, separated by slashes (/). Each segment must be 63 characters or less, start and end
with an alphanumeric character, and can include dashes (-), underscores (_), dots (.), and
alphanumerics in between. Optionally, the property name can have a prefix, which must be a DNS
subdomain up to 253 characters, followed by a slash (/). Below are some examples of valid
property names:
cpumemorykubernetes-fleet.io/node-countkubernetes.azure.com/skus/Standard_B4ms/count
Eventually, all cluster properties are exposed via the Fleet MemberCluster API, with the
non-resource properties in the .status.properties field and the resource properties
.status.resourceUsage field:
apiVersion: cluster.kubernetes-fleet.io/v1beta1
kind: MemberCluster
metadata: ...
spec: ...
status:
agentStatus: ...
conditions: ...
properties:
kubernetes-fleet.io/node-count:
observationTime: "2024-04-30T14:54:24Z"
value: "2"
...
resourceUsage:
allocatable:
cpu: 32
memory: "16Gi"
available:
cpu: 2
memory: "800Mi"
capacity:
cpu: 40
memory: "20Gi"
Note that conditions reported by the property provider (if any), would be available in the
.status.conditions array as well.
Core properties
The following properties are considered core properties in Fleet, which should be supported
in all property provider implementations. Fleet agents will collect them even when no
property provider has been set up.
| Property Type | Name | Description |
|---|
| Non-resource property | kubernetes-fleet.io/node-count | The number of nodes in a cluster. |
| Resource property | cpu | The usage information (total, allocatable, and available capacity) of CPU resource in a cluster. |
| Resource property | memory | The usage information (total, allocatable, and available capacity) of memory resource in a cluster. |
1.8 - Safe Rollout
Concept about rolling out changes safely in Fleet
One of the most important features of Fleet is the ability to safely rollout changes across multiple clusters. We do
this by rolling out the changes in a controlled manner, ensuring that we only continue to propagate the changes to the
next target clusters if the resources are successfully applied to the previous target clusters.
Overview
We automatically propagate any resource changes that are selected by a ClusterResourcePlacement from the hub cluster
to the target clusters based on the placement policy defined in the ClusterResourcePlacement. In order to reduce the
blast radius of such operation, we provide users a way to safely rollout the new changes so that a bad release
won’t affect all the running instances all at once.
Rollout Strategy
We currently only support the RollingUpdate rollout strategy. It updates the resources in the selected target clusters
gradually based on the maxUnavailable and maxSurge settings.
In place update policy
We always try to do in-place update by respecting the rollout strategy if there is no change in the placement. This is to avoid unnecessary
interrupts to the running workloads when there is only resource changes. For example, if you only change the tag of the
deployment in the namespace you want to place, we will do an in-place update on the deployments already placed on the
targeted cluster instead of moving the existing deployments to other clusters even if the labels or properties of the
current clusters are not the best to match the current placement policy.
How To Use RollingUpdateConfig
RolloutUpdateConfig is used to control behavior of the rolling update strategy.
MaxUnavailable and MaxSurge
MaxUnavailable specifies the maximum number of connected clusters to the fleet compared to target number of clusters
specified in ClusterResourcePlacement policy in which resources propagated by the ClusterResourcePlacement can be
unavailable. Minimum value for MaxUnavailable is set to 1 to avoid stuck rollout during in-place resource update.
MaxSurge specifies the maximum number of clusters that can be scheduled with resources above the target number of clusters
specified in ClusterResourcePlacement policy.
Note: MaxSurge only applies to rollouts to newly scheduled clusters, and doesn’t apply to rollouts of workload triggered by
updates to already propagated resource. For updates to already propagated resources, we always try to do the updates in
place with no surge.
target number of clusters changes based on the ClusterResourcePlacement policy.
- For PickAll, it’s the number of clusters picked by the scheduler.
- For PickN, it’s the number of clusters specified in the
ClusterResourcePlacement policy. - For PickFixed, it’s the length of the list of cluster names specified in the
ClusterResourcePlacement policy.
Example 1
Consider a fleet with 4 connected member clusters (cluster-1, cluster-2, cluster-3 & cluster-4) where every member
cluster has label env: prod. The hub cluster has a namespace called test-ns with a deployment in it.
The ClusterResourcePlacement spec is defined as follows:
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: test-ns
policy:
placementType: PickN
numberOfClusters: 3
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
strategy:
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
The rollout will be as follows:
We try to pick 3 clusters out of 4, for this scenario let’s say we pick cluster-1, cluster-2 & cluster-3.
Since we can’t track the initial availability for the deployment, we rollout the namespace with deployment to
cluster-1, cluster-2 & cluster-3.
Then we update the deployment with a bad image name to update the resource in place on cluster-1, cluster-2 & cluster-3.
But since we have maxUnavailable set to 1, we will rollout the bad image name update for deployment to one of the clusters
(which cluster the resource is rolled out to first is non-deterministic).
Once the deployment is updated on the first cluster, we will wait for the deployment’s availability to be true before
rolling out to the other clusters
And since we rolled out a bad image name update for the deployment it’s availability will always be false and hence the
rollout for the other two clusters will be stuck
Users might think maxSurge of 1 might be utilized here but in this case since we are updating the resource in place
maxSurge will not be utilized to surge and pick cluster-4.
Note: maxSurge will be utilized to pick cluster-4, if we change the policy to pick 4 cluster or change placement
type to PickAll.
Example 2
Consider a fleet with 4 connected member clusters (cluster-1, cluster-2, cluster-3 & cluster-4) where,
- cluster-1 and cluster-2 has label
loc: west - cluster-3 and cluster-4 has label
loc: east
The hub cluster has a namespace called test-ns with a deployment in it.
Initially, the ClusterResourcePlacement spec is defined as follows:
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: test-ns
policy:
placementType: PickN
numberOfClusters: 2
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
loc: west
strategy:
rollingUpdate:
maxSurge: 2
The rollout will be as follows:
- We try to pick clusters (cluster-1 and cluster-2) by specifying the label selector
loc: west. - Since we can’t track the initial availability for the deployment, we rollout the namespace with deployment to cluster-1
and cluster-2 and wait till they become available.
Then we update the ClusterResourcePlacement spec to the following:
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: test-ns
policy:
placementType: PickN
numberOfClusters: 2
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
loc: east
strategy:
rollingUpdate:
maxSurge: 2
The rollout will be as follows:
- We try to pick clusters (cluster-3 and cluster-4) by specifying the label selector
loc: east. - But this time around since we have
maxSurge set to 2 we are saying we can propagate resources to a maximum of
4 clusters but our target number of clusters specified is 2, we will rollout the namespace with deployment to both
cluster-3 and cluster-4 before removing the deployment from cluster-1 and cluster-2. - And since
maxUnavailable is always set to 25% by default which is rounded off to 1, we will remove the
resource from one of the existing clusters (cluster-1 or cluster-2) because when maxUnavailable is 1 the policy
mandates at least one cluster to be available.
UnavailablePeriodSeconds
UnavailablePeriodSeconds is used to configure the waiting time between rollout phases when we cannot determine if the
resources have rolled out successfully or not. This field is used only if the availability of resources we propagate
are not trackable. Refer to the Data only object section for more details.
Availability based Rollout
We have built-in mechanisms to determine the availability of some common Kubernetes native resources. We only mark them
as available in the target clusters when they meet the criteria we defined.
How It Works
We have an agent running in the target cluster to check the status of the resources. We have specific criteria for each
of the following resources to determine if they are available or not. Here are the list of resources we support:
Deployment
We only mark a Deployment as available when all its pods are running, ready and updated according to the latest spec.
DaemonSet
We only mark a DaemonSet as available when all its pods are available and updated according to the latest spec on all
desired scheduled nodes.
StatefulSet
We only mark a StatefulSet as available when all its pods are running, ready and updated according to the latest revision.
Job
We only mark a Job as available when it has at least one succeeded pod or one ready pod.
Service
For Service based on the service type the availability is determined as follows:
- For
ClusterIP & NodePort service, we mark it as available when a cluster IP is assigned. - For
LoadBalancer service, we mark it as available when a LoadBalancerIngress has been assigned along with an IP or Hostname. - For
ExternalName service, checking availability is not supported, so it will be marked as available with not trackable reason.
Data only objects
For the objects described below since they are a data resource we mark them as available immediately after creation,
- Namespace
- Secret
- ConfigMap
- Role
- ClusterRole
- RoleBinding
- ClusterRoleBinding
1.9 - Override
Concept about the override APIs
Overview
The ClusterResourceOverride and ResourceOverride provides a way to customize resource configurations before they are propagated
to the target cluster by the ClusterResourcePlacement.
Difference Between ClusterResourceOverride And ResourceOverride
ClusterResourceOverride represents the cluster-wide policy that overrides the cluster scoped resources to one or more
clusters while ResourceOverride will apply to resources in the same namespace as the namespace-wide policy.
Note: If a namespace is selected by the ClusterResourceOverride, ALL the resources under the namespace are selected
automatically.
If the resource is selected by both ClusterResourceOverride and ResourceOverride, the ResourceOverride will win
when resolving the conflicts.
When To Use Override
Overrides is useful when you want to customize the resources before they are propagated from the hub cluster to the target clusters.
Some example use cases are:
- As a platform operator, I want to propagate a clusterRoleBinding to cluster-us-east and cluster-us-west and would like to
grant the same role to different groups in each cluster.
- As a platform operator, I want to propagate a clusterRole to cluster-staging and cluster-production and would like to
grant more permissions to the cluster-staging cluster than the cluster-production cluster.
- As a platform operator, I want to propagate a namespace to all the clusters and would like to customize the labels for
each cluster.
- As an application developer, I would like to propagate a deployment to cluster-staging and cluster-production and would
like to always use the latest image in the staging cluster and a specific image in the production cluster.
- As an application developer, I would like to propagate a deployment to all the clusters and would like to use different
commands for my container in different regions.
Limits
- Each resource can be only selected by one override simultaneously. In the case of namespace scoped resources, up to two
overrides will be allowed, considering the potential selection through both
ClusterResourceOverride (select its namespace)
and ResourceOverride. - At most 100
ClusterResourceOverride can be created. - At most 100
ResourceOverride can be created.
Placement
This specifies which placement the override should be applied to.
Resource Selector
ClusterResourceSelector of ClusterResourceOverride selects which cluster-scoped resources need to be overridden before
applying to the selected clusters.
It supports the following forms of resource selection:
- Select resources by specifying the <group, version, kind> and name. This selection propagates only one resource that
matches the <group, version, kind> and name.
Note: Label selector of ClusterResourceSelector is not supported.
ResourceSelector of ResourceOverride selects which namespace-scoped resources need to be overridden before applying to
the selected clusters.
It supports the following forms of resource selection:
- Select resources by specifying the <group, version, kind> and name. This selection propagates only one resource that
matches the <group, version, kind> and name under the
ResourceOverride namespace.
Override Policy
Override policy defines how to override the selected resources on the target clusters.
It contains an array of override rules and its order determines the override order. For example, when there are two rules
selecting the same fields on the target cluster, the last one will win.
Each override rule contains the following fields:
ClusterSelector: which cluster(s) the override rule applies to. It supports the following forms of cluster selection:- Select clusters by specifying the cluster labels.
- An empty selector selects ALL the clusters.
- A nil selector selects NO target cluster.
IMPORTANT:
Only labelSelector is supported in the clusterSelectorTerms field.
OverrideType: which type of the override should be applied to the selected resources. The default type is JSONPatch.JSONPatch: applies the JSON patch to the selected resources using RFC 6902.Delete: deletes the selected resources on the target cluster.
JSONPatchOverrides: a list of JSON path override rules applied to the selected resources following RFC 6902 when the override type is JSONPatch.
Note: Updating the fields in the TypeMeta (e.g., apiVersion, kind) is not allowed.
Note: Updating the fields in the ObjectMeta (e.g., name, namespace) excluding annotations and labels is not allowed.
Note: Updating the fields in the Status (e.g., status) is not allowed.
Reserved Variables in the JSON Patch Override Value
There is a list of reserved variables that will be replaced by the actual values used in the value of the JSON patch override rule:
${MEMBER-CLUSTER-NAME}: this will be replaced by the name of the memberCluster that represents this cluster.${MEMBER-CLUSTER-LABEL-KEY-<label-key>}: this will be replaced by the value of the label with the key <label-key> on the memberCluster. For example, ${MEMBER-CLUSTER-LABEL-KEY-region} will be replaced by the value of the region label on the target member cluster. If the label does not exist on the cluster, the override will fail with an error.
These variables are supported in both ClusterResourceOverride and ResourceOverride.
Example: Using ${MEMBER-CLUSTER-NAME} in a ClusterResourceOverride
To add a label to the ClusterRole named secret-reader on clusters with the label env: prod,
you can use the following configuration:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ClusterResourceOverride
metadata:
name: example-cro
spec:
placement:
name: crp-example
clusterResourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
version: v1
name: secret-reader
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
jsonPatchOverrides:
- op: add
path: /metadata/labels
value:
{"cluster-name":"${MEMBER-CLUSTER-NAME}"}
Note: Using op: add with the path /metadata/labels (pointing to the entire labels map) will replace all existing labels with the value provided. To add a single label without affecting existing ones, use a more specific path such as /metadata/labels/cluster-name.
The ClusterResourceOverride object above will add a label cluster-name with the value of the memberCluster name to the ClusterRole named secret-reader on clusters with the label env: prod.
Example: Using ${MEMBER-CLUSTER-LABEL-KEY-...} in a ClusterResourceOverride
Suppose you have member clusters with a region label (e.g., region: us-west, region: eu-central) and you want
to add a label reflecting the cluster’s region to a ClusterRole:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ClusterResourceOverride
metadata:
name: cro-region-label
spec:
placement:
name: crp-example
clusterResourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
version: v1
name: secret-reader
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms: []
jsonPatchOverrides:
- op: add
path: /metadata/labels/cluster-region
value: "${MEMBER-CLUSTER-LABEL-KEY-region}"
Note: To replace an existing label value, use op: replace instead (e.g., op: replace with path /metadata/labels/cluster-region). However, op: replace will fail with an error if the label does not already exist on the resource.
When applied to a cluster with the label region: us-west, the ClusterRole will receive the label
cluster-region: us-west. When applied to a cluster with region: eu-central, the label will be
cluster-region: eu-central.
Example: Using ${MEMBER-CLUSTER-LABEL-KEY-...} in a ResourceOverride
You can also use cluster label variables in a ResourceOverride to customize namespace-scoped resources.
For example, suppose you have a Deployment named my-app in the namespace app-ns, and your member clusters
have region and env labels. You can inject those values as annotations:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
name: ro-label-vars
namespace: app-ns
spec:
placement:
name: crp-example
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: my-app
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms: []
jsonPatchOverrides:
- op: add
path: /metadata/annotations
value:
{"target-region":"${MEMBER-CLUSTER-LABEL-KEY-region}", "target-env":"${MEMBER-CLUSTER-LABEL-KEY-env}"}
When applied to a cluster with labels region: us-west and env: production, the deployment will receive the
annotations target-region: us-west and target-env: production.
You can also combine multiple variables in a single value. For example:
jsonPatchOverrides:
- op: replace
path: /spec/template/spec/containers/0/image
value: "myregistry-${MEMBER-CLUSTER-LABEL-KEY-region}.example.com/my-app:${MEMBER-CLUSTER-LABEL-KEY-env}"
On a cluster with region: us-west and env: staging, this would resolve to
myregistry-us-west.example.com/my-app:staging.
When To Trigger Rollout
It will take the snapshot of each override change as a result of ClusterResourceOverrideSnapshot and
ResourceOverrideSnapshot. The snapshot will be used to determine whether the override change should be applied to the existing
ClusterResourcePlacement or not. If applicable, it will start rolling out the new resources to the target clusters by
respecting the rollout strategy defined in the ClusterResourcePlacement.
Examples
add annotations to the configmap by using clusterResourceOverride
Suppose we create a configmap named app-config-1 under the namespace application-1 in the hub cluster, and we want to
add an annotation to it, which is applied to all the member clusters.
apiVersion: v1
data:
data: test
kind: ConfigMap
metadata:
creationTimestamp: "2024-05-07T08:06:27Z"
name: app-config-1
namespace: application-1
resourceVersion: "1434"
uid: b4109de8-32f2-4ac8-9e1a-9cb715b3261d
Create a ClusterResourceOverride named cro-1 to add an annotation to the namespace application-1.
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ClusterResourceOverride
metadata:
creationTimestamp: "2024-05-07T08:06:27Z"
finalizers:
- kubernetes-fleet.io/override-cleanup
generation: 1
name: cro-1
resourceVersion: "1436"
uid: 32237804-7eb2-4d5f-9996-ff4d8ce778e7
spec:
placement:
name: crp-example
clusterResourceSelectors:
- group: ""
kind: Namespace
name: application-1
version: v1
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms: []
jsonPatchOverrides:
- op: add
path: /metadata/annotations
value:
cro-test-annotation: cro-test-annotation-val
Check the configmap on one of the member cluster by running kubectl get configmap app-config-1 -n application-1 -o yaml command:
apiVersion: v1
data:
data: test
kind: ConfigMap
metadata:
annotations:
cro-test-annotation: cro-test-annotation-val
kubernetes-fleet.io/last-applied-configuration: '{"apiVersion":"v1","data":{"data":"test"},"kind":"ConfigMap","metadata":{"annotations":{"cro-test-annotation":"cro-test-annotation-val","kubernetes-fleet.io/spec-hash":"4dd5a08aed74884de455b03d3b9c48be8278a61841f3b219eca9ed5e8a0af472"},"name":"app-config-1","namespace":"application-1","ownerReferences":[{"apiVersion":"placement.kubernetes-fleet.io/v1beta1","blockOwnerDeletion":false,"kind":"AppliedWork","name":"crp-1-work","uid":"77d804f5-f2f1-440e-8d7e-e9abddacb80c"}]}}'
kubernetes-fleet.io/spec-hash: 4dd5a08aed74884de455b03d3b9c48be8278a61841f3b219eca9ed5e8a0af472
creationTimestamp: "2024-05-07T08:06:27Z"
name: app-config-1
namespace: application-1
ownerReferences:
- apiVersion: placement.kubernetes-fleet.io/v1beta1
blockOwnerDeletion: false
kind: AppliedWork
name: crp-1-work
uid: 77d804f5-f2f1-440e-8d7e-e9abddacb80c
resourceVersion: "1449"
uid: a8601007-1e6b-4b64-bc05-1057ea6bd21b
add annotations to the configmap by using resourceOverride
You can use the ResourceOverride to add an annotation to the configmap app-config-1 explicitly in the namespace application-1.
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
creationTimestamp: "2024-05-07T08:25:31Z"
finalizers:
- kubernetes-fleet.io/override-cleanup
generation: 1
name: ro-1
namespace: application-1
resourceVersion: "3859"
uid: b4117925-bc3c-438d-a4f6-067bc4577364
spec:
placement:
name: crp-example
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms: []
jsonPatchOverrides:
- op: add
path: /metadata/annotations
value:
ro-test-annotation: ro-test-annotation-val
resourceSelectors:
- group: ""
kind: ConfigMap
name: app-config-1
version: v1
How To Validate If Overrides Are Applied
You can validate if the overrides are applied by checking the ClusterResourcePlacement status. The status output will
indicate both placement conditions and individual placement statuses on each member cluster that was overridden.
Sample output:
status:
conditions:
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: found all the clusters needed as specified by the scheduling policy
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: All 3 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: The selected resources are successfully overridden in the 3 clusters
observedGeneration: 1
reason: OverriddenSucceeded
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: Works(s) are succcesfully created or updated in the 3 target clusters'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: The selected resources are successfully applied to 3 clusters
observedGeneration: 1
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: The selected resources in 3 cluster are available now
observedGeneration: 1
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
observedResourceIndex: "0"
placementStatuses:
- applicableClusterResourceOverrides:
- cro-1-0
clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: Successfully applied the override rules on the resources
observedGeneration: 1
reason: OverriddenSucceeded
status: "True"
type: Overridden
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-05-07T08:06:27Z"
message: The availability of work object crp-1-work is not trackable
observedGeneration: 1
reason: WorkNotTrackable
status: "True"
type: Available
...
applicableClusterResourceOverrides in placementStatuses indicates which ClusterResourceOverrideSnapshot that is applied
to the target cluster. Similarly, applicableResourceOverrides will be set if the ResourceOverrideSnapshot is applied.
1.10 - Staged Update
Concept about Staged Update
While users can rely on the RollingUpdate rollout strategy in the placement to safely roll out their workloads,
many organizations require more sophisticated deployment control mechanisms for their fleet operations.
Standard rolling updates, while effective for individual rollout, lack the granular control and coordination capabilities needed for complex, multi-cluster environments.
Why Staged Rollouts?
Staged rollouts address critical deployment challenges that organizations face when managing workloads across distributed environments:
Strategic Grouping and Ordering
Traditional rollout strategies treat all target clusters uniformly, but real-world deployments often require strategic sequencing. Staged rollouts enable you to:
- Group clusters by environment (development → staging → production)
- Prioritize by criticality (test clusters before business-critical systems)
- Sequence by dependencies (deploy foundational services before dependent applications)
This grouping capability ensures that updates follow your organization’s risk management and operational requirements rather than arbitrary ordering.
Enhanced Control and Approval Gates
Automated rollouts provide speed but can propagate issues rapidly across your entire fleet. Staged rollouts introduce deliberate checkpoints that give teams control over the rollout progression:
- Manual approval gates between stages allow human validation of rollout health
- Automated wait periods provide time for monitoring and observation
Dual-Scope Architecture
Kubefleet provides staged update capabilities at two different scopes to address different organizational roles and operational requirements:
- Cluster-scoped staged updates for fleet administrators who need to manage rollouts across entire clusters
- Namespace-scoped staged updates for application teams who need to manage rollouts within their specific namespaces
This dual approach enables fleet administrators to maintain oversight of infrastructure-level changes while empowering application teams with autonomous control over their specific workloads.
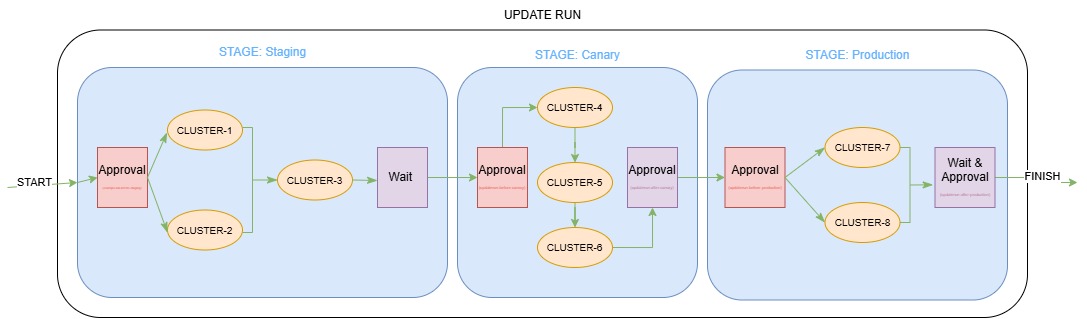
Diagram Example Configuration
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateStrategy
metadata:
name: production-rollout
spec:
stages:
- name: staging
labelSelector:
matchLabels:
environment: staging
maxConcurrency: 75%
beforeStageTasks:
- type: Approval
afterStageTasks:
- type: TimedWait
waitTime: 1h
- name: canary
labelSelector:
matchLabels:
environment: canary
# Default MaxConcurrency (1)
beforeStageTasks:
- type: Approval
afterStageTasks:
- type: Approval
- name: production
labelSelector:
matchLabels:
environment: production
maxConcurrency: 2
beforeStageTasks:
- type: Approval
afterStageTasks:
- type: TimedWait
waitTime: 1h
- type: Approval
Overview
Kubefleet provides staged update capabilities at two scopes to serve different organizational needs:
Cluster-Scoped: ClusterStagedUpdateStrategy, ClusterStagedUpdateRun, and ClusterApprovalRequest for fleet administrators managing infrastructure-level changes across clusters.
Namespace-Scoped: StagedUpdateStrategy, StagedUpdateRun, and ApprovalRequest for application teams managing rollouts within their specific namespaces.
Both systems follow the same pattern:
- Strategy resources define reusable orchestration patterns with stages, ordering, and approval gates
- UpdateRun resources execute the strategy for specific rollouts using a target placement, resource snapshot, and strategy name
- External rollout strategy must be set on the target placement to enable staged updates
Key Differences by Persona
| Aspect | Fleet Administrators (Cluster-Scoped) | Application Teams (Namespace-Scoped) |
|---|
| Scope | Entire clusters and infrastructure | Individual applications within namespaces |
| Resources | ClusterStagedUpdateStrategy, ClusterStagedUpdateRun, ClusterApprovalRequest | StagedUpdateStrategy, StagedUpdateRun, ApprovalRequest |
| Target | ClusterResourcePlacement | ResourcePlacement (namespace-scoped) |
| Use Cases | Fleet-wide updates, infrastructure changes | Application rollouts, service updates |
| Permission | Requires cluster-admin permissions | Operates within namespace boundaries |
Both placement types require setting the rollout strategy to External to enable staged updates:
Cluster-scoped example:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: example-placement
spec:
resourceSelectors:
- group: ""
kind: Namespace
name: test-namespace
version: v1
policy:
placementType: PickAll
strategy:
type: External # enables staged updates
Namespace-scoped example:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ResourcePlacement
metadata:
name: example-namespace-placement
namespace: my-app-namespace
spec:
resourceSelectors:
- group: "apps"
kind: Deployment
name: my-application
version: v1
policy:
placementType: PickAll
strategy:
type: External # enables staged updates
Define Staged Update Strategies
Staged update strategies define reusable orchestration patterns that organize target clusters into stages with specific rollout sequences and approval gates. Both scopes use similar configurations but operate at different levels.
Cluster-Scoped Strategy
ClusterStagedUpdateStrategy organizes member clusters into stages:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateStrategy
metadata:
name: cluster-config-strategy
spec:
stages:
- name: staging
labelSelector:
matchLabels:
environment: staging
maxConcurrency: 2 # Update 2 clusters concurrently
afterStageTasks:
- type: TimedWait
waitTime: 1h
- name: canary
labelSelector:
matchLabels:
environment: canary
maxConcurrency: 1 # Sequential updates (default)
beforeStageTasks:
- type: Approval # Require approval before starting canary stage
afterStageTasks:
- type: Approval
- name: production
labelSelector:
matchLabels:
environment: production
sortingLabelKey: order
maxConcurrency: 50% # Update 50% of production clusters at once
afterStageTasks:
- type: Approval
- type: TimedWait
waitTime: 1h
Namespace-Scoped Strategy
StagedUpdateStrategy follows the same pattern but operates within namespace boundaries:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: StagedUpdateStrategy
metadata:
name: app-rollout-strategy
namespace: my-app-namespace
spec:
stages:
- name: dev
labelSelector:
matchLabels:
environment: development
maxConcurrency: 3 # Update 3 dev clusters at once
afterStageTasks:
- type: TimedWait
waitTime: 30m
- name: prod
labelSelector:
matchLabels:
environment: production
sortingLabelKey: deployment-order
maxConcurrency: 1 # Sequential production updates
afterStageTasks:
- type: Approval
Stage Configuration
Each stage includes:
- name: Unique identifier for the stage
- labelSelector: Selects target clusters for this stage
- sortingLabelKey (optional): Label whose integer value determines update sequence within the stage
- maxConcurrency (optional): Maximum number of clusters to update concurrently within the stage. Can be an absolute number (e.g.,
5) or percentage (e.g., 50%). Defaults to 1 (sequential). Fractional results are rounded down with a minimum of 1 - beforeStageTasks (optional): Tasks that must complete before starting the stage (max 1 task, Approval type only)
- afterStageTasks (optional): Tasks that must complete before proceeding to the next stage (max 2 tasks, Approval and/or TimedWait type)
Stage Tasks
Stage tasks provide control gates at different points in the rollout lifecycle:
Before-Stage Tasks
Execute before a stage begins. Only one task allowed per stage. Supported types:
- Approval: Requires manual approval before starting the stage
For before-stage approval tasks, the system creates an approval request named <updateRun-name>-before-<stage-name>.
After-Stage Tasks
Execute after all clusters in a stage complete. Up to two tasks allowed (one of each type). Supported types:
- TimedWait: Waits for a specified duration before proceeding to the next stage
- Approval: Requires manual approval before proceeding to the next stage
For after-stage approval tasks, the system creates an approval request named <updateRun-name>-after-<stage-name>.
Approval Request Details
For all approval tasks, the approval request type depends on the scope:
- Cluster-scoped: Creates
ClusterApprovalRequest (short name: careq) - a cluster-scoped resource containing a spec with parentStageRollout (the UpdateRun name) and targetStage (the stage name). The spec is immutable after creation. - Namespace-scoped: Creates
ApprovalRequest (short name: areq) within the same namespace - a namespace-scoped resource with the same spec structure as ClusterApprovalRequest.
Both approval request types use status conditions to track approval state:
Approved condition (status True): indicates the request was approved by a userApprovalAccepted condition (status True): indicates the approval was processed and accepted by the system
Approve manually by setting the Approved condition to True using kubectl patch:
Note: Observed generation in the Approved condition should match the generation of the approvalRequest object.
# For cluster-scoped before-stage approvals
kubectl patch clusterapprovalrequests example-run-before-canary --type='merge' \
-p '{"status":{"conditions":[{"type":"Approved","status":"True","reason":"approved","message":"approved","lastTransitionTime":"'$(date -u +"%Y-%m-%dT%H:%M:%SZ")'","observedGeneration":1}]}}' \
--subresource=status
# For cluster-scoped after-stage approvals
kubectl patch clusterapprovalrequests example-run-after-canary --type='merge' \
-p '{"status":{"conditions":[{"type":"Approved","status":"True","reason":"approved","message":"approved","lastTransitionTime":"'$(date -u +"%Y-%m-%dT%H:%M:%SZ")'","observedGeneration":1}]}}' \
--subresource=status
# For namespace-scoped approvals
kubectl patch approvalrequests example-run-before-canary -n test-namespace --type='merge' \
-p '{"status":{"conditions":[{"type":"Approved","status":"True","reason":"approved","message":"approved","lastTransitionTime":"'$(date -u +"%Y-%m-%dT%H:%M:%SZ")'","observedGeneration":1}]}}' \
--subresource=status
Trigger Staged Rollouts
UpdateRun resources execute strategies for specific rollouts. Both scopes follow the same pattern:
Cluster-scoped example:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
name: example-run
spec:
placementName: example-placement # Required: Name of Target ClusterResourcePlacement
resourceSnapshotIndex: "0" # Optional: Resource version (omit to use the latest snapshot, creating one if it does not already exist)
stagedRolloutStrategyName: example-strategy # Required: Name of the strategy to execute
state: Run # Optional: Initialize (default), Run, or Stop
Namespace-scoped example:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: StagedUpdateRun
metadata:
name: app-rollout-v1-2-3
namespace: my-app-namespace
spec:
placementName: example-namespace-placement # Required: Name of target ResourcePlacement. The StagedUpdateRun must be created in the same namespace as the ResourcePlacement
resourceSnapshotIndex: "5" # Optional: Resource version (omit to use the latest snapshot, creating one if it does not already exist)
stagedRolloutStrategyName: app-rollout-strategy # Required: Name of the strategy to execute. Must be in the same namespace
state: Initialize # Optional: Initialize (default), Run, or Stop
Creating Latest Resource Snapshot:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
name: example-run-latest
spec:
placementName: example-placement
# resourceSnapshotIndex omitted - system uses the latest snapshot (creates one if it does not already exist)
stagedRolloutStrategyName: example-strategy
state: Run
UpdateRun State Management
UpdateRuns support three states to control execution lifecycle:
| State | Behavior | Use Case |
|---|
| Initialize | Prepares the updateRun without executing (default) | Review computed stages before starting rollout |
| Run | Executes the rollout or resumes from stopped state | Start or resume the staged rollout |
| Stop | Pauses execution at current cluster/stage | Temporarily halt rollout for investigation |
Valid State Transitions:
Initialize → Run: Start the rolloutRun → Stop: Pause the rolloutStop → Run: Resume the rollout
Invalid State Transitions:
Initialize → Stop: Cannot stop before startingRun → Initialize: Cannot reinitialize after startingStop → Initialize: Cannot reinitialize after stopping
The state field is the only mutable field in the UpdateRunSpec. You can update it to control rollout execution:
# Start a rollout
kubectl patch csur example-run --type='merge' -p '{"spec":{"state":"Run"}}'
# Pause a rollout
kubectl patch csur example-run --type='merge' -p '{"spec":{"state":"Stop"}}'
# Resume a paused rollout
kubectl patch csur example-run --type='merge' -p '{"spec":{"state":"Run"}}'
UpdateRun Execution
UpdateRuns execute in three phases:
- Initialization: Validates placement, captures latest strategy snapshot, collects target bindings, generates cluster update sequence, uses the specified resource snapshot or the latest snapshot (creating one if it does not already exist) if unspecified & records override snapshots. Occurs once on creation when state is
Initialize, Run or Stop. - Execution: Processes stages sequentially, updates clusters within each stage (respecting maxConcurrency), enforces before-stage and after-stage tasks. Only occurs when state is
Run - Stopping/Stopped When state is
Stop, the updateRun pauses execution at the current cluster/stage and can be resumed by changing state back to Run. If there are updating/deleting clusters we wait after marking updateRun as Stopping for the in-progress clusters to reach a deterministic state: succeeded, failed or stuck before marking updateRun as Stopped
Important Constraints and Validation
Immutable Fields: Once created, the following UpdateRun spec fields cannot be modified:
placementName: Target placement resource nameresourceSnapshotIndex: Resource version to deploy (empty string if omitted)stagedRolloutStrategyName: Strategy to execute
Mutable Field: The state field can be modified after creation to control execution (Initialize, Run, Stop).
Strategy Limits: Each strategy can define a maximum of 31 stages to ensure reasonable execution times.
MaxConcurrency Validation:
- Must be >= 1 for absolute numbers
- Must be 1-100% for percentages
- Fractional results are rounded down with minimum of 1
Monitor UpdateRun Status
UpdateRun status provides detailed information about rollout progress across stages and clusters. The status includes:
- Overall conditions: Initialization, progression, and completion status
- Stage status: Progress and timing for each stage
- Cluster status: Individual cluster update results with maxConcurrency respected
- Before-stage task status: Pre-stage approval progress
- After-stage task status: Post-stage approval and wait task progress
- Resource snapshot used: The actual resource snapshot index used (from spec or latest)
- Policy snapshot used: The policy snapshot index used during initialization
Use kubectl describe to view detailed status:
# Cluster-scoped (can use short name 'csur')
kubectl describe clusterstagedupdaterun example-run
kubectl describe csur example-run
# Namespace-scoped (can use short name 'sur')
kubectl describe stagedupdaterun app-rollout-v1-2-3 -n my-app-namespace
kubectl describe sur app-rollout-v1-2-3 -n my-app-namespace
UpdateRun and Placement Relationship
UpdateRuns and Placements work together to orchestrate rollouts, with each serving a distinct purpose:
The Trigger Mechanism
UpdateRuns serve as the trigger that initiates rollouts for their respective placement resources:
- Cluster-scoped:
ClusterStagedUpdateRun triggers ClusterResourcePlacement - Namespace-scoped:
StagedUpdateRun triggers ResourcePlacement
Before an UpdateRun is Created
When you create a Placement with spec.strategy.type: External, the system schedules which clusters should receive the resources, but does not deploy anything yet. The Placement remains in a scheduled but not available state, waiting for an UpdateRun to trigger the actual rollout.
Note: Resource snapshots are not automatically created for placements with spec.strategy.type: External. If you create a new placement directly with External strategy, you must omit the resourceSnapshotIndex field in your UpdateRun spec to have the system create a new snapshot during initialization.
After an UpdateRun is Created
Once you create an UpdateRun, the system begins executing the staged rollout. Both resources provide status information, but at different levels of detail:
UpdateRun Status - High-level rollout orchestration:
- Which stage is currently executing
- Which clusters have started/completed updates
- Whether after-stage tasks (approvals, waits) are complete
- Overall rollout progression through stages
Placement Status - Detailed deployment information for each cluster:
- Success or failure of individual resource creation (e.g., did the Deployment create successfully?)
- Whether overrides were applied correctly
- Specific error messages if resources failed to deploy
- Detailed conditions for troubleshooting
This separation of concerns allows you to:
- Monitor high-level rollout progress and stage execution through the UpdateRun
- Drill down into specific deployment issues on individual clusters through the Placement
- Understand whether a problem is with the staged rollout orchestration or with resource deployment itself
Concurrent UpdateRuns
Multiple UpdateRuns can execute concurrently for the same placement with one constraint: all concurrent runs must use identical strategy configurations to ensure consistent behavior.
Next Steps
1.11 - Eviction and Placement Disruption Budget
Concept about Eviction and Placement Disrupiton Budget
This document explains the concept of Eviction and Placement Disruption Budget in the context of the fleet.
Overview
Eviction provides a way to force remove resources from a target cluster once the resources have already been propagated from the hub cluster by a Placement object.
Eviction is considered as an voluntary disruption triggered by the user. Eviction alone doesn’t guarantee that resources won’t be propagated to target cluster again by the scheduler.
The users need to use taints in conjunction with Eviction to prevent the scheduler from picking the target cluster again.
The Placement Disruption Budget object protects against voluntary disruptions.
The only voluntary disruption that can occur in the fleet is the eviction of resources from a target cluster which can be achieved by creating the ClusterResourcePlacementEviction object.
Some cases of involuntary disruptions in the context of fleet,
- The removal of resources from a member cluster by the scheduler due to scheduling policy changes.
- Users manually deleting workload resources running on a member cluster.
- Users manually deleting the
ClusterResourceBinding object which is an internal resource the represents the placement of resources on a member cluster. - Workloads failing to run properly on a member cluster due to misconfiguration or cluster related issues.
For all the cases of involuntary disruptions described above, the Placement Disruption Budget object does not protect against them.
ClusterResourcePlacementEviction
An eviction object is used to remove resources from a member cluster once the resources have already been propagated from the hub cluster.
The eviction object is only reconciled once after which it reaches a terminal state. Below is the list of terminal states for ClusterResourcePlacementEviction,
ClusterResourcePlacementEviction is valid and it’s executed successfully.ClusterResourcePlacementEviction is invalid.ClusterResourcePlacementEviction is valid but it’s not executed.
To successfully evict resources from a cluster, the user needs to specify:
- The name of the
ClusterResourcePlacement object which propagated resources to the target cluster. - The name of the target cluster from which we need to evict resources.
When specifying the ClusterResourcePlacement object in the eviction’s spec, the user needs to consider the following cases:
- For
PickFixed CRP, eviction is not allowed; it is recommended that one directly edit the list of target clusters on the CRP object. - For
PickAll & PickN CRPs, eviction is allowed because the users cannot deterministically pick or unpick a cluster based on the placement strategy; it’s up to the scheduler.
Note: After an eviction is executed, there is no guarantee that the cluster won’t be picked again by the scheduler to propagate resources for a ClusterResourcePlacement resource.
The user needs to specify a taint on the cluster to prevent the scheduler from picking the cluster again. This is especially true for PickAll ClusterResourcePlacement because
the scheduler will try to propagate resources to all the clusters in the fleet.
ClusterResourcePlacementDisruptionBudget
The ClusterResourcePlacementDisruptionBudget is used to protect resources propagated by a ClusterResourcePlacement to a target cluster from voluntary disruption, i.e., ClusterResourcePlacementEviction.
Note: When specifying a ClusterResourcePlacementDisruptionBudget, the name should be the same as the ClusterResourcePlacement that it’s trying to protect.
Users are allowed to specify one of two fields in the ClusterResourcePlacementDisruptionBudget spec since they are mutually exclusive:
- MaxUnavailable - specifies the maximum number of clusters in which a placement can be unavailable due to any form of disruptions.
- MinAvailable - specifies the minimum number of clusters in which placements are available despite any form of disruptions.
for both MaxUnavailable and MinAvailable, the user can specify the number of clusters as an integer or as a percentage of the total number of clusters in the fleet.
Note: For both MaxUnavailable and MinAvailable, involuntary disruptions are not subject to the disruption budget but will still count against it.
When specifying a disruption budget for a particular ClusterResourcePlacement, the user needs to consider the following cases:
| CRP type | MinAvailable DB with an integer | MinAvailable DB with a percentage | MaxUnavailable DB with an integer | MaxUnavailable DB with a percentage |
|---|
PickFixed | ❌ | ❌ | ❌ | ❌ |
PickAll | ✅ | ❌ | ❌ | ❌ |
PickN | ✅ | ✅ | ✅ | ✅ |
Note: We don’t allow eviction for PickFixed CRP and hence specifying a ClusterResourcePlacementDisruptionBudget for PickFixed CRP does nothing.
And for PickAll CRP, the user can only specify MinAvailable because total number of clusters selected by a PickAll CRP is non-deterministic.
If the user creates an invalid ClusterResourcePlacementDisruptionBudget object, when an eviction is created, the eviction won’t be successfully executed.
2 - Getting Started
Getting started with Fleet
Fleet documentation features a number of getting started tutorials to help you learn
about Fleet with an environment of your preference. Pick one below to proceed.
If you are not sure about which one is the best option, for simplicity reasons, it is
recommended that you start with the
Getting started with Fleet using KinD clusters.
2.1 - Getting started with Fleet using KinD clusters
Use KinD clusters to learn about Fleet
In this tutorial, you will try Fleet out using
KinD clusters, which are Kubernetes clusters running on your own
local machine via Docker containers. This is the easiest way
to get started with Fleet, which can help you understand how Fleet simiplify the day-to-day multi-cluster management experience with very little setup needed.
Note
kind is a tool for setting up a Kubernetes environment for experimental purposes;
some instructions below for running Fleet in the kind environment may not apply to other
environments, and there might also be some minor differences in the Fleet
experience.
Before you begin
To complete this tutorial, you will need:
- The following tools on your local machine:
docker, to build kubefleet agent images.kind, for running Kubernetes clusters on your local machine- Docker
gitcurlhelm, the Kubernetes package managerjqbase64
Spin up a few kind clusters
The Fleet open-source project manages a multi-cluster environment using a hub-spoke pattern,
which consists of one hub cluster and one or more member clusters:
- The hub cluster is the portal to which every member cluster connects; it also serves as an
interface for centralized management, through which you can perform a number of tasks,
primarily orchestrating workloads across different clusters.
- A member cluster connects to the hub cluster and runs your workloads as orchestrated by the
hub cluster.
In this tutorial you will create two kind clusters; one of which serves as the Fleet
hub cluster, and the other the Fleet member cluster. Run the commands below to create them:
# Replace YOUR-KIND-IMAGE with a kind node image name of your
# choice. It should match with the version of kind installed
# on your system; for more information, see
# [kind releases](https://github.com/kubernetes-sigs/kind/releases).
export KIND_IMAGE=YOUR-KIND-IMAGE
# Replace YOUR-KUBECONFIG-PATH with the path to a Kubernetes
# configuration file of your own, typically $HOME/.kube/config.
export KUBECONFIG_PATH=YOUR-KUBECONFIG-PATH
# The names of the kind clusters; you may use values of your own if you'd like to.
export HUB_CLUSTER=hub
export MEMBER_CLUSTER=cluster-1
kind create cluster --name $HUB_CLUSTER \
--image=$KIND_IMAGE \
--kubeconfig=$KUBECONFIG_PATH
kind create cluster --name $MEMBER_CLUSTER \
--image=$KIND_IMAGE \
--kubeconfig=$KUBECONFIG_PATH
# Export the configurations for the kind clusters.
kind export kubeconfig -n $HUB_CLUSTER
kind export kubeconfig -n $MEMBER_CLUSTER
Set up the Fleet hub cluster
To set up the hub cluster, run the commands below:
# Replace YOUR-HUB-CLUSTER-CONTEXT with the name of the kubeconfig context for your hub cluster.
export HUB_CLUSTER_CONTEXT=YOUR-HUB-CLUSTER-CONTEXT
kubectl config use-context $HUB_CLUSTER_CONTEXT
# Please replace the following env variables with the values of your own; see the repository README for
# more information.
export REGISTRY="ghcr.io/kubefleet-dev/kubefleet" # Replace with your own container registry if you want to use a custom registry
export TARGET_ARCH="amd64" # Replace with your architecture, we support amd64 and arm64
export TAG=$(curl "https://api.github.com/repos/kubefleet-dev/kubefleet/tags" | jq -r '.[0].name') # Replace with your desired tag
export HUB_AGENT_IMAGE="hub-agent"
# Clone the KubeFleet repository from GitHub and navigate to the root directory of the repository.
git clone https://github.com/kubefleet-dev/kubefleet.git
cd kubefleet
# Build and push the hub agent image to your container registry.
export OUTPUT_TYPE="type=registry"
make docker-build-hub-agent
# Install the helm chart for running Fleet agents on the hub cluster.
helm upgrade --install hub-agent ./charts/hub-agent/ \
--set image.pullPolicy=Always \
--set image.repository=$REGISTRY/$HUB_AGENT_IMAGE \
--set image.tag=$TAG \
--set namespace=fleet-system \
--set logVerbosity=5 \
--set enableGuardRail=false \
--set enableWebhook=true \
--set forceDeleteWaitTime="3m0s" \
--set clusterUnhealthyThreshold="5m0s" \
--set logFileMaxSize=100000 \
It may take a few seconds for the installation to complete. Once it finishes, verify that
the Fleet hub agents are up and running with the commands below:
kubectl get pods -n fleet-system
You should see that all the pods are in the ready state.
Set up the Fleet member custer
Next, you will set up the other kind cluster you created earlier as the Fleet
member cluster, which requires that you install the Fleet member agent on
the cluster and connect it to the Fleet hub cluster.
For your convenience, Fleet provides a script that can automate the process of joining a cluster
into a fleet. To use the script, follow the steps below:
# Optional: build and push the member agent image to your container registry if you want to use a custom image.
make docker-build-member-agent
make docker-build-refresh-token
# Run the script.
chmod +x ./hack/membership/joinMC.sh
./hack/membership/joinMC.sh $TAG <HUB-CLUSTER-NAME> <MEMBER-CLUSTER-NAME-1> <MEMBER-CLUSTER-NAME-2> <MEMBER-CLUSTER-NAME-3> ...
It may take a few minutes for the script to finish running. Once it is completed, the script will print out something
like this:
NAME JOINED AGE MEMBER-AGENT-LAST-SEEN NODE-COUNT AVAILABLE-CPU AVAILABLE-MEMORY
hub-cluster True 30s 28s 1 748m 2870328Ki
The newly joined cluster should have the JOINED status field set to True. If you see that
the cluster is still in an unknown state, it might be that the member cluster
is still connecting to the hub cluster. Should this state persist for a prolonged
period, refer to the Troubleshooting Guide for
more information.
Note
If you would like to know more about the steps the script runs, or would like to join
a cluster into a fleet manually, refer to the Managing Clusters How-To
Guide.
Use the ClusterResourcePlacement API to orchestrate resources among member clusters
Fleet offers an API, ClusterResourcePlacement, which helps orchestrate workloads, i.e., any group
Kubernetes resources, among all member clusters. In this last part of the tutorial, you will use
this API to place some Kubernetes resources automatically into the member clusters via the hub
cluster, saving the trouble of having to create them one by one in each member cluster.
Create the resources for placement
Run the commands below to create a namespace and a config map, which will be placed onto the
member clusters.
kubectl create namespace work
kubectl create configmap app -n work --from-literal=data=test
It may take a few seconds for the commands to complete.
Create the ClusterResourcePlacement API object
Next, create a ClusterResourcePlacement API object in the hub cluster:
kubectl apply -f - <<EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: work
policy:
placementType: PickAll
EOF
Note that the CRP object features a resource selector, which targets the work namespace you
just created. This will instruct the CRP to place the namespace itself, and all resources
registered under the namespace, such as the config map, to the target clusters. Also, in the policy
field, a PickAll placement type has been specified. This allows the CRP to automatically perform
the placement on all member clusters in the fleet, including those that join after the CRP object
is created.
It may take a few seconds for Fleet to successfully place the resources. To check up on the
progress, run the commands below:
kubectl get clusterresourceplacement crp
Verify that the placement has been completed successfully; you should see that the APPLIED status
field has been set to True. You may need to repeat the commands a few times to wait for
the completion.
Confirm the placement
Now, log into the member clusters to confirm that the placement has been completed.
kubectl config use-context $MEMBER_CLUSTER_CONTEXT
kubectl get ns
kubectl get configmap -n work
You should see the namespace work and the config map app listed in the output.
Clean things up
To remove all the resources you just created, run the commands below:
# This would also remove the namespace and config map placed in all member clusters.
kubectl delete crp crp
kubectl delete ns work
kubectl delete configmap app -n work
To uninstall Fleet, run the commands below:
kubectl config use-context $HUB_CLUSTER_CONTEXT
helm uninstall hub-agent
kubectl config use-context $MEMBER_CLUSTER_CONTEXT
helm uninstall member-agent
What’s next
Congratulations! You have completed the getting started tutorial for Fleet. To learn more about
Fleet:
2.2 - Getting started with Fleet using on-premises clusters
Use on-premises clusters of your own to learn about Fleet
In this tutorial, you will try Fleet out using a few of your own Kubernetes clusters; Fleet can
help you manage workloads seamlessly across these clusters, greatly simplifying the experience
of day-to-day Kubernetes management.
Note
This tutorial assumes that you have some experience of performing administrative tasks for
Kubernetes clusters. If you are just gettings started with Kubernetes, or do not have much
experience of setting up a Kubernetes cluster, it is recommended that you follow the
Getting started with Fleet using Kind clusters tutorial instead.
Before you begin
To complete this tutorial, you will need:
- At least two Kubernetes clusters of your own.
- Note that one of these clusters will serve as your hub cluster; other clusters must be able
to reach it via the network.
- The following tools on your local machine:
docker, to build kubefleet agent images.kubectl, the Kubernetes CLI tool.gitcurlhelm, the Kubernetes package managerjqbase64
Set up a Fleet hub cluster
The Fleet open-source project manages a multi-cluster environment using a hub-spoke pattern,
which consists of one hub cluster and one or more member clusters:
- The hub cluster is the portal to which every member cluster connects; it also serves as an
interface for centralized management, through which you can perform a number of tasks,
primarily orchestrating workloads across different clusters.
- A member cluster connects to the hub cluster and runs your workloads as orchestrated by the
hub cluster.
Any Kubernetes cluster running a supported version of Kubernetes can serve as the hub cluster;
it is recommended that you reserve a cluster specifically for this responsibility, and do not run heavy workloads on it.
To set up the hub cluster, run the commands below:
# Replace YOUR-HUB-CLUSTER-CONTEXT with the name of the kubeconfig context for your hub cluster.
export HUB_CLUSTER_CONTEXT=YOUR-HUB-CLUSTER-CONTEXT
kubectl config use-context $HUB_CLUSTER_CONTEXT
# Please replace the following env variables with the values of your own; see the repository README for
# more information.
export REGISTRY="ghcr.io/kubefleet-dev/kubefleet" # Replace with your own container registry if you want to use a custom registry
export TARGET_ARCH="amd64" # Replace with your architecture, we support amd64 and arm64
export TAG=$(curl "https://api.github.com/repos/kubefleet-dev/kubefleet/tags" | jq -r '.[0].name') # Replace with your desired tag
export HUB_AGENT_IMAGE="hub-agent"
# Clone the KubeFleet repository from GitHub and navigate to the root directory of the repository.
git clone https://github.com/kubefleet-dev/kubefleet.git
cd kubefleet
# Optional: build and push the hub agent image to your container registry if you want to use a custom image.
export OUTPUT_TYPE="type=registry"
make docker-build-hub-agent
# Install the helm chart for running Fleet agents on the hub cluster.
helm upgrade --install hub-agent ./charts/hub-agent/ \
--set image.pullPolicy=Always \
--set image.repository=$REGISTRY/$HUB_AGENT_IMAGE \
--set image.tag=$TAG \
--set namespace=fleet-system \
--set logVerbosity=5 \
--set enableGuardRail=false \
--set enableWebhook=true \
--set enableWorkload=true \
--set forceDeleteWaitTime="3m0s" \
--set clusterUnhealthyThreshold="5m0s" \
--set logFileMaxSize=100000 \
--set MaxConcurrentClusterPlacement=200
It may take a few seconds for the installation to complete. Once it finishes, verify that
the Fleet hub agents are up and running with the commands below:
kubectl get pods -n fleet-system
You should see that all the pods are in the ready state.
Connect a member cluster to the hub cluster
Next, you will set up a cluster as the member cluster for your fleet. This cluster should
run a supported version of Kubernetes and be able to connect to the hub cluster via the network.
For your convenience, Fleet provides a script that can automate the process of joining a cluster
into a fleet. To use the script, follow the steps below:
# Optional: build and push the member agent image to your container registry if you want to use a custom image.
make docker-build-member-agent
make docker-build-refresh-token
# Run the script.
chmod +x ./hack/membership/joinMC.sh
./hack/membership/joinMC.sh $TAG <HUB-CLUSTER-NAME> <MEMBER-CLUSTER-NAME-1> <MEMBER-CLUSTER-NAME-2> <MEMBER-CLUSTER-NAME-3> ...
It may take a few minutes for the script to finish running. Once it is completed, the script will print out something
like this:
NAME JOINED AGE MEMBER-AGENT-LAST-SEEN NODE-COUNT AVAILABLE-CPU AVAILABLE-MEMORY
routing-cluster True 30s 28s 2 5748m 28780328Ki
The newly joined cluster should have the JOINED status field set to True. If you see that
the cluster is still in an unknown state, it might be that the member cluster
is still connecting to the hub cluster. Should this state persist for a prolonged
period, refer to the Troubleshooting Guide for more information.
Use the ClusterResourcePlacement API to orchestrate resources among member clusters
Fleet offers an API, ClusterResourcePlacement, which helps orchestrate workloads, i.e., any group
Kubernetes resources, among all member clusters. In this last part of the tutorial, you will use
this API to place some Kubernetes resources automatically into the member clusters via the hub
cluster, saving the trouble of having to create them one by one in each member cluster.
Create the resources for placement
Run the commands below to create a namespace and a config map, which will be placed onto the
member clusters.
kubectl create namespace work
kubectl create configmap app -n work --from-literal=data=test
It may take a few seconds for the commands to complete.
Create the ClusterResourcePlacement API object
Next, create a ClusterResourcePlacement API object in the hub cluster:
kubectl apply -f - <<EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: work
policy:
placementType: PickAll
EOF
Note that the CRP object features a resource selector, which targets the work namespace you
just created. This will instruct the CRP to place the namespace itself, and all resources
registered under the namespace, such as the config map, to the target clusters. Also, in the policy
field, a PickAll placement type has been specified. This allows the CRP to automatically perform
the placement on all member clusters in the fleet, including those that join after the CRP object
is created.
It may take a few seconds for Fleet to successfully place the resources. To check up on the
progress, run the commands below:
kubectl get clusterresourceplacement crp
Verify that the placement has been completed successfully; you should see that the APPLIED status
field has been set to True. You may need to repeat the commands a few times to wait for
the completion.
Confirm the placement
Now, log into the member clusters to confirm that the placement has been completed.
kubectl config use-context $MEMBER_CLUSTER_CONTEXT
kubectl get ns
kubectl get configmap -n work
You should see the namespace work and the config map app listed in the output.
Clean things up
To remove all the resources you just created, run the commands below:
# This would also remove the namespace and config map placed in all member clusters.
kubectl delete crp crp
kubectl delete ns work
kubectl delete configmap app -n work
To uninstall Fleet, run the commands below:
kubectl config use-context $HUB_CLUSTER_CONTEXT
helm uninstall hub-agent
kubectl config use-context $MEMBER_CLUSTER_CONTEXT
helm uninstall member-agent
What’s next
Congratulations! You have completed the getting started tutorial for Fleet. To learn more about
Fleet:
3 - How-To Guides
Guides for completing common Fleet tasks
Fleet documentation features a number of how-to guides to help you complete
common Fleet tasks. Pick one below to proceed.
3.1 - Managing clusters
How to join or remove a cluster from a fleet, and how to view the status of and label a member cluster
This how-to guide discusses how to manage clusters in a fleet, specifically:
- how to join a cluster into a fleet; and
- how to set a cluster to leave a fleet; and
- how to add labels to a member cluster
Joining a cluster into a fleet
A cluster can join in a fleet if:
- it runs a supported Kubernetes version; it is recommended that you use Kubernetes 1.24 or later
versions, and
- it has network connectivity to the hub cluster of the fleet.
For your convenience, Fleet provides a script that can automate the process of joining a cluster
into a fleet. To use the script, run the commands below:
Note
To run this script, make sure that you have already installed the following tools in your
system:
kubectl, the Kubernetes CLIhelm, a Kubernetes package managercurljqbase64
# Replace the value of HUB_CLUSTER_CONTEXT with the name of the kubeconfig context you use for
# accessing your hub cluster.
export HUB_CLUSTER_CONTEXT=YOUR-HUB-CLUSTER-CONTEXT
# Replace the value of HUB_CLUSTER_ADDRESS with the address of your hub cluster API server.
export HUB_CLUSTER_ADDRESS=YOUR-HUB-CLUSTER-ADDRESS
# Replace the value of MEMBER_CLUSTER with the name you would like to assign to the new member
# cluster.
#
# Note that Fleet will recognize your cluster with this name once it joins.
export MEMBER_CLUSTER=YOUR-MEMBER-CLUSTER
# Replace the value of MEMBER_CLUSTER_CONTEXT with the name of the kubeconfig context you use
# for accessing your member cluster.
export MEMBER_CLUSTER_CONTEXT=YOUR-MEMBER-CLUSTER-CONTEXT
# Clone the Fleet GitHub repository.
git clone https://github.com/kubefleet-dev/kubefleet.git
# Run the script.
chmod +x kubefleet/hack/membership/joinMC.sh
./kubefleet/hack/membership/joinMC.sh
It may take a few minutes for the script to finish running. Once it is completed, verify
that the cluster has joined successfully with the command below:
kubectl config use-context $HUB_CLUSTER_CONTEXT
kubectl get membercluster $MEMBER_CLUSTER
If you see that the cluster is still in an unknown state, it might be that the member cluster
is still connecting to the hub cluster. Should this state persist for a prolonged
period, refer to the Troubleshooting Guide for
more information.
Alternatively, if you would like to find out the exact steps the script performs, or if you feel
like fine-tuning some of the steps, you may join a cluster manually to your fleet with the
instructions below:
Joining a member cluster manually
Make sure that you have installed kubectl, helm, curl, jq, and base64 in your
system.
Create a Kubernetes service account in your hub cluster:
# Replace the value of HUB_CLUSTER_CONTEXT with the name of the kubeconfig
# context you use for accessing your hub cluster.
export HUB_CLUSTER_CONTEXT="YOUR-HUB-CLUSTER-CONTEXT"
# Replace the value of MEMBER_CLUSTER with a name you would like to assign to the new
# member cluster.
#
# Note that the value of MEMBER_CLUSTER will be used as the name the member cluster registers
# with the hub cluster.
export MEMBER_CLUSTER="YOUR-MEMBER-CLUSTER"
export SERVICE_ACCOUNT="$MEMBER_CLUSTER-hub-cluster-access"
kubectl config use-context $HUB_CLUSTER_CONTEXT
# The service account can, in theory, be created in any namespace; for simplicity reasons,
# here you will use the namespace reserved by Fleet installation, `fleet-system`.
#
# Note that if you choose a different value, commands in some steps below need to be
# modified accordingly.
kubectl create serviceaccount $SERVICE_ACCOUNT -n fleet-system
Create a Kubernetes secret of the service account token type, which the member cluster will
use to access the hub cluster.
export SERVICE_ACCOUNT_SECRET="$MEMBER_CLUSTER-hub-cluster-access-token"
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: $SERVICE_ACCOUNT_SECRET
namespace: fleet-system
annotations:
kubernetes.io/service-account.name: $SERVICE_ACCOUNT
type: kubernetes.io/service-account-token
EOF
After the secret is created successfully, extract the token from the secret:
export TOKEN=$(kubectl get secret $SERVICE_ACCOUNT_SECRET -n fleet-system -o jsonpath='{.data.token}' | base64 -d)
Note
Keep the token in a secure place; anyone with access to this token can access the hub cluster
in the same way as the Fleet member cluster does.
You may have noticed that at this moment, no access control has been set on the service
account; Fleet will set things up when the member cluster joins. The service account will be
given the minimally viable set of permissions for the Fleet member cluster to connect to the
hub cluster; its access will be restricted to one namespace, specifically reserved for the
member cluster, as per security best practices.
Register the member cluster with the hub cluster; Fleet manages cluster membership using the
MemberCluster API:
cat <<EOF | kubectl apply -f -
apiVersion: cluster.kubernetes-fleet.io/v1beta1
kind: MemberCluster
metadata:
name: $MEMBER_CLUSTER
spec:
identity:
name: $SERVICE_ACCOUNT
kind: ServiceAccount
namespace: fleet-system
apiGroup: ""
heartbeatPeriodSeconds: 60
EOF
Set up the member agent, the Fleet component that works on the member cluster end, to enable
Fleet connection:
# Clone the Fleet repository from GitHub.
git clone https://github.com/kubefleet-dev/kubefleet.git
# Install the member agent helm chart on the member cluster.
# Replace the value of MEMBER_CLUSTER_CONTEXT with the name of the kubeconfig context you use
# for member cluster access.
export MEMBER_CLUSTER_CONTEXT="YOUR-MEMBER-CLUSTER-CONTEXT"
# Replace the value of HUB_CLUSTER_ADDRESS with the address of the hub cluster API server.
export HUB_CLUSTER_ADDRESS="YOUR-HUB-CLUSTER-ADDRESS"
# The variables below uses the Fleet images kept in the Microsoft Container
# Registry (MCR) and will retrieve the latest version from the Fleet GitHub
# repository. This pulls from the Azure Fleet repository while the kubefleet
# containers are being developed.
#
# You can also build the Fleet images of your own; see the repository README
# for more information.
export REGISTRY="mcr.microsoft.com/aks/fleet"
export FLEET_VERSION=$(curl "https://api.github.com/repos/Azure/fleet/tags" | jq -r '.[0].name')
export MEMBER_AGENT_IMAGE="member-agent"
export REFRESH_TOKEN_IMAGE="refresh-token"
kubectl config use-context $MEMBER_CLUSTER_CONTEXT
# Create the secret with the token extracted previously for member agent to use.
kubectl create secret generic hub-kubeconfig-secret --from-literal=token=$TOKEN
helm install member-agent kubefleet/charts/member-agent/ \
--set config.hubURL=$HUB_CLUSTER_ADDRESS \
--set image.repository=$REGISTRY/$MEMBER_AGENT_IMAGE \
--set image.tag=$FLEET_VERSION \
--set refreshtoken.repository=$REGISTRY/$REFRESH_TOKEN_IMAGE \
--set refreshtoken.tag=$FLEET_VERSION \
--set image.pullPolicy=Always \
--set refreshtoken.pullPolicy=Always \
--set config.memberClusterName="$MEMBER_CLUSTER" \
--set logVerbosity=5 \
--set namespace=fleet-system \
--set enableV1Alpha1APIs=false \
--set enableV1Beta1APIs=true
Verify that the installation of the member agent is successful:
kubectl get pods -n fleet-system
You should see that all the returned pods are up and running. Note that it may take a few
minutes for the member agent to get ready.
Verify that the member cluster has joined the fleet successfully:
kubectl config use-context $HUB_CLUSTER_CONTEXT
kubectl get membercluster $MEMBER_CLUSTER
Setting a cluster to leave a fleet
Fleet uses the MemberCluster API to manage cluster memberships. To remove a member cluster
from a fleet, simply delete its corresponding MemberCluster object from your hub cluster:
# Replace the value of MEMBER-CLUSTER with the name of the member cluster you would like to
# remove from a fleet.
export MEMBER_CLUSTER=YOUR-MEMBER-CLUSTER
kubectl delete membercluster $MEMBER_CLUSTER
It may take a while before the member cluster leaves the fleet successfully. Fleet will perform
some cleanup; all the resources placed onto the cluster will be removed.
After the member cluster leaves, you can remove the member agent installation from it using Helm:
# Replace the value of MEMBER_CLUSTER_CONTEXT with the name of the kubeconfig context you use
# for member cluster access.
export MEMBER_CLUSTER_CONTEXT=YOUR-MEMBER-CLUSTER-CONTEXT
kubectl config use-context $MEMBER_CLUSTER_CONTEXT
helm uninstall member-agent
It may take a few moments before the uninstallation completes.
Viewing the status of a member cluster
Similarly, you can use the MemberCluster API in the hub cluster to view the status of a
member cluster:
# Replace the value of MEMBER-CLUSTER with the name of the member cluster of which you would like
# to view the status.
export MEMBER_CLUSTER=YOUR-MEMBER-CLUSTER
kubectl get membercluster $MEMBER_CLUSTER -o jsonpath="{.status}"
The status consists of:
an array of conditions, including:
the ReadyToJoin condition, which signals whether the hub cluster is ready to accept
the member cluster; and
the Joined condition, which signals whether the cluster has joined the fleet; and
the Healthy condition, which signals whether the cluster is in a healthy state.
Typically, a member cluster should have all three conditions set to true. Refer to the
Troubleshooting Guide for help if a cluster fails to join
into a fleet.
the resource usage of the cluster; at this moment Fleet reports the capacity and
the allocatable amount of each resource in the cluster, summed up from all nodes in the cluster.
an array of agent status, which reports the status of specific Fleet agents installed in
the cluster; each entry features:
- an array of conditions, in which
Joined signals whether the specific agent has been
successfully installed in the cluster, and Healthy signals whether the agent is in a
healthy state; and - the timestamp of the last received heartbeat from the agent.
Adding labels to a member cluster
You can add labels to a MemberCluster object in the same as with any other Kubernetes object.
These labels can then be used for targeting specific clusters in resource placement. To add a label,
run the command below:
# Replace the values of MEMBER_CLUSTER, LABEL_KEY, and LABEL_VALUE with those of your own.
export MEMBER_CLUSTER=YOUR-MEMBER-CLUSTER
export LABEL_KEY=YOUR-LABEL-KEY
export LABEL_VALUE=YOUR-LABEL-VALUE
kubectl label membercluster $MEMBER_CLUSTER $LABEL_KEY=$LABEL_VALUE
3.2 - Using the ClusterResourcePlacement API
How to use the ClusterResourcePlacement API
This guide provides an overview of how to use the Fleet ClusterResourcePlacement (CRP) API to orchestrate workload distribution across your fleet.
Overview
The CRP API is a core Fleet API that facilitates the distribution of specific resources from the hub cluster to
member clusters within a fleet. This API offers scheduling capabilities that allow you to target the most suitable
group of clusters for a set of resources using a complex rule set. For example, you can distribute resources to
clusters in specific regions (North America, East Asia, Europe, etc.) and/or release stages (production, canary, etc.).
You can even distribute resources according to certain topology spread constraints.
API Components
The CRP API generally consists of the following components:
- Resource Selectors: These specify the set of resources selected for placement.
- Scheduling Policy: This determines the set of clusters where the resources will be placed.
- Rollout Strategy: This controls the behavior of resource placement when the resources themselves and/or the
scheduling policy are updated, minimizing interruptions caused by refreshes.
- StatusReportingScope: This controls where ClusterResourcePlacement status information is made available.
The following sections discuss these components in depth.
Resource selectors
A ClusterResourcePlacement object may feature one or more resource selectors,
specifying which resources to select for placement. To add a resource selector, edit
the resourceSelectors field in the ClusterResourcePlacement spec:
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- group: "rbac.authorization.k8s.io"
kind: ClusterRole
version: v1
name: secretReader
The example above will pick a ClusterRole named secretReader for resource placement.
It is important to note that, as its name implies, ClusterResourcePlacement selects only
cluster-scoped resources. However, if you select a namespace, all the resources under the
namespace will also be placed.
Different types of resource selectors
You can specify a resource selector in many different ways:
To select one specific resource, such as a namespace, specify its API GVK (group, version, and
kind), and its name, in the resource selector:
# As mentioned earlier, all the resources under the namespace will also be selected.
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: work
Alternately, you may also select a set of resources of the same API GVK using a label selector;
it also requires that you specify the API GVK and the filtering label(s):
# As mentioned earlier, all the resources under the namespaces will also be selected.
resourceSelectors:
- group: ""
kind: Namespace
version: v1
labelSelector:
matchLabels:
system: critical
In the example above, all the namespaces in the hub cluster with the label system=critical
will be selected (along with the resources under them).
Fleet uses standard Kubernetes label selectors; for its specification and usage, see the
Kubernetes API reference.
Very occasionally, you may need to select all the resources under a specific GVK; to achieve
this, use a resource selector with only the API GVK added:
resourceSelectors:
- group: "rbac.authorization.k8s.io"
kind: ClusterRole
version: v1
In the example above, all the cluster roles in the hub cluster will be picked.
Multiple resource selectors
You may specify up to 100 different resource selectors; Fleet will pick a resource if it matches
any of the resource selectors specified (i.e., all selectors are OR’d).
# As mentioned earlier, all the resources under the namespace will also be selected.
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: work
- group: "rbac.authorization.k8s.io"
kind: ClusterRole
version: v1
name: secretReader
In the example above, Fleet will pick the namespace work (along with all the resources
under it) and the cluster role secretReader.
Note
You can find the GVKs of built-in Kubernetes API objects in the
Kubernetes API reference.
Scheduling policy
Each scheduling policy is associated with a placement type, which determines how Fleet will
pick clusters. The ClusterResourcePlacement API supports the following placement types:
| Placement type | Description |
|---|
PickFixed | Pick a specific set of clusters by their names. |
PickAll | Pick all the clusters in the fleet, per some standard. |
PickN | Pick a count of N clusters in the fleet, per some standard. |
Note
Scheduling policy itself is optional. If you do not specify a scheduling policy,
Fleet will assume that you would like to use
a scheduling of the PickAll placement type; it effectively sets Fleet to pick
all the clusters in the fleet.
Fleet does not support switching between different placement types; if you need to do
so, re-create a new ClusterResourcePlacement object.
PickFixed placement type
PickFixed is the most straightforward placement type, through which you directly tell Fleet
which clusters to place resources at. To use this placement type, specify the target cluster
names in the clusterNames field, such as
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickFixed
clusterNames:
- bravelion
- smartfish
The example above will place resources to two clusters, bravelion and smartfish.
PickAll placement type
PickAll placement type allows you to pick all clusters in the fleet per some standard. With
this placement type, you may use affinity terms to fine-tune which clusters you would like
for Fleet to pick:
An affinity term specifies a requirement that a cluster needs to meet, usually the presence
of a label.
There are two types of affinity terms:
requiredDuringSchedulingIgnoredDuringExecution terms are requirements that a cluster
must meet before it can be picked; and
preferredDuringSchedulingIgnoredDuringExecution terms are requirements that, if a
cluster meets, will set Fleet to prioritize it in scheduling.
In the scheduling policy of the PickAll placement type, you may only use the
requiredDuringSchedulingIgnoredDuringExecution terms.
Note
You can learn more about affinities in Using Affinities to Pick Clusters How-To
Guide.
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickAll
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
system: critical
The ClusterResourcePlacement object above will pick all the clusters with the label
system:critical on them; clusters without the label will be ignored.
Fleet is forward-looking with the PickAll placement type: any cluster that satisfies the
affinity terms of a ClusterResourcePlacement object, even if it joins after the
ClusterResourcePlacement object is created, will be picked.
Note
You may specify a scheduling policy of the PickAll placement with no affinity; this will set
Fleet to select all clusters currently present in the fleet.
PickN placement type
PickN placement type allows you to pick a specific number of clusters in the fleet for resource
placement; with this placement type, you may use affinity terms and topology spread constraints
to fine-tune which clusters you would like Fleet to pick.
An affinity term specifies a requirement that a cluster needs to meet, usually the presence
of a label.
There are two types of affinity terms:
requiredDuringSchedulingIgnoredDuringExecution terms are requirements that a cluster
must meet before it can be picked; andpreferredDuringSchedulingIgnoredDuringExecution terms are requirements that, if a
cluster meets, will set Fleet to prioritize it in scheduling.
A topology spread constraint can help you spread resources evenly across different groups
of clusters. For example, you may want to have a database replica deployed in each region
to enable high-availability.
Note
You can learn more about affinities in Using Affinities to Pick Clusters
How-To Guide, and more about topology spread constraints in
Using Topology Spread Constraints to Pick Clusters How-To Guide.
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickN
numberOfClusters: 3
affinity:
clusterAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 20
preference:
- labelSelector:
matchLabels:
critical-level: 1
The ClusterResourcePlacement object above will pick first clusters with the critical-level=1
on it; if only there are not enough (less than 3) such clusters, will Fleet pick clusters with no
such label.
To be more precise, with this placement type, Fleet scores clusters on how well it satisfies the
affinity terms and the topology spread constraints; Fleet will assign:
- an affinity score, for how well the cluster satisfies the affinity terms; and
- a topology spread score, for how well the cluster satisfies the topology spread constraints.
Note
For more information on the scoring specifics, see
Using Affinities to Pick Clusters How-To Guide (for affinity score) and
Using Topology Spread Constraints to Pick Clusters How-To
Guide (for topology spread score).
After scoring, Fleet ranks the clusters using the rule below and picks the top N clusters:
the cluster with the highest topology spread score ranks the highest;
if there are multiple clusters with the same topology spread score, the one with the highest
affinity score ranks the highest;
if there are multiple clusters with same topology spread score and affinity score, sort their
names by alphanumeric order; the one with the most significant name ranks the highest.
This helps establish deterministic scheduling behavior.
Both affinity terms and topology spread constraints are optional. If you do not specify
affinity terms or topology spread constraints, all clusters will be assigned 0 in
affinity score or topology spread score respectively. When neither is added in the scheduling
policy, Fleet will simply rank clusters by their names, and pick N out of them, with
most significant names in alphanumeric order.
When there are not enough clusters to pick
It may happen that Fleet cannot find enough clusters to pick. In this situation, Fleet will
keep looking until all N clusters are found.
Note that Fleet will stop looking once all N clusters are found, even if there appears a
cluster that scores higher.
Up-scaling and downscaling
You can edit the numberOfClusters field in the scheduling policy to pick more or less clusters.
When up-scaling, Fleet will score all the clusters that have not been picked earlier, and find
the most appropriate ones; for downscaling, Fleet will unpick the clusters that ranks lower
first.
Note
For downscaling, the ranking Fleet uses for unpicking clusters is composed when the scheduling
is performed, i.e., it may not reflect the latest setup in the Fleet.
A few more points about scheduling policies
Responding to changes in the fleet
Generally speaking, once a cluster is picked by Fleet for a ClusterResourcePlacement object,
it will not be unpicked even if you modify the cluster in a way that renders it unfit for
the scheduling policy, e.g., you have removed a label for the cluster, which is required for
some affinity term. Fleet will also not remove resources from the cluster even if the cluster
becomes unhealthy, e.g., it gets disconnected from the hub cluster. This helps reduce service
interruption.
However, Fleet will unpick a cluster if it leaves the fleet. If you are using a scheduling
policy of the PickN placement type, Fleet will attempt to find a new cluster as replacement.
Finding the scheduling decisions Fleet makes
You can find out why Fleet picks a cluster in the status of a ClusterResourcePlacement object.
For more information, see the
Understanding the Status of a ClusterResourcePlacement How-To Guide.
Available fields for each placement type
The table below summarizes the available scheduling policy fields for each placement type:
| PickFixed | PickAll | PickN |
|---|
placementType | ✅ | ✅ | ✅ |
numberOfClusters | ❌ | ❌ | ✅ |
clusterNames | ✅ | ❌ | ❌ |
affinity | ❌ | ✅ | ✅ |
topologySpreadConstraints | ❌ | ❌ | ✅ |
Rollout strategy
After a ClusterResourcePlacement is created, you may want to
- Add, update, or remove the resources that have been selected by the
ClusterResourcePlacement in the hub cluster - Update the resource selectors in the
ClusterResourcePlacement - Update the scheduling policy in the
ClusterResourcePlacement
These changes may trigger the following outcomes:
- New resources may need to be placed on all picked clusters
- Resources already placed on a picked cluster may get updated or deleted
- Some clusters picked previously are now unpicked, and resources must be removed from such clusters
- Some clusters are newly picked, and resources must be added to them
Most outcomes can lead to service interruptions. Apps running on member clusters may temporarily become
unavailable as Fleet dispatches updated resources. Clusters that are no longer selected will lose all placed resources,
resulting in lost traffic. If too many new clusters are selected and Fleet places resources on them simultaneously,
your backend may become overloaded. The exact interruption pattern may vary depending on the resources you place using Fleet.
To minimize interruption, Fleet allows users to configure the rollout strategy, similar to native Kubernetes deployment,
to transition between changes as smoothly as possible. Currently, Fleet supports only one rollout strategy: rolling update.
This strategy ensures changes, including the addition or removal of selected clusters and resource refreshes,
are applied incrementally in a phased manner at a pace suitable for you. This is the default option and applies to all changes you initiate.
This rollout strategy can be configured with the following parameters:
maxSurge determines the number of additional clusters, beyond the required number, that will receive resource placements.
It can also be set as an absolute number or a percentage. The default is 25%, and zero should not be used for this value.
unavailablePeriodSeconds allows users to inform the fleet when the resources are deemed “ready”.
The default value is 60 seconds.
- Fleet only considers newly applied resources on a cluster as “ready” once
unavailablePeriodSeconds seconds
have passed after the resources have been successfully applied to that cluster. - Setting a lower value for this parameter will result in faster rollouts. However, we strongly
recommend that users set it to a value that all the initialization/preparation tasks can be completed within
that time frame. This ensures that the resources are typically ready after the
unavailablePeriodSeconds have passed. - We are currently designing a generic “ready gate” for resources being applied to clusters. Please feel free to raise
issues or provide feedback if you have any thoughts on this.
Note
Fleet will round numbers up if you use a percentage for maxUnavailable and/or maxSurge.
For example, if you have a ClusterResourcePlacement with a scheduling policy of the PickN
placement type and a target number of clusters of 10, with the default rollout strategy, as
shown in the example below,
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
...
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
unavailablePeriodSeconds: 60
Every time you initiate a change on selected resources, Fleet will:
- Find
10 * 25% = 2.5, rounded up to 3 clusters, which will receive the resource refresh; - Wait for 60 seconds (
unavailablePeriodSeconds), and repeat the process; - Stop when all the clusters have received the latest version of resources.
The exact period of time it takes for Fleet to complete a rollout depends not only on the
unavailablePeriodSeconds, but also the actual condition of a resource placement; that is,
if it takes longer for a cluster to get the resources applied successfully, Fleet will wait
longer to complete the rollout, in accordance with the rolling update strategy you specified.
Note
In very extreme circumstances, rollout may get stuck, if Fleet just cannot apply resources
to some clusters. You can identify this behavior if CRP status; for more information, see
Understanding the Status of a ClusterResourcePlacement How-To Guide.
StatusReportingScope
The two supported values for StatusReportingScope are:
- ClusterScopeOnly: Default behavior, placement status is part of the
ClusterResourcePlacement object. - NamespaceAccessible: A
ClusterResourcePlacementStatus object is created in the namespace selected by the ClusterResourcePlacement.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: test-crp
spec:
resourceSelectors:
- group: ""
kind: Namespace
name: test-ns
version: v1
policy:
placementType: PickAll
strategy:
type: RollingUpdate
statusReportingScope: NamespaceAccessible
Lets take a look at the ClusterResourcePlacment object’s status,
% kubectl get clusterresourceplacements.v1beta1.placement.kubernetes-fleet.io test-crp -o yaml
...
status:
conditions:
- lastTransitionTime: ...
message: found all cluster needed as specified by the scheduling policy, found
3 cluster(s)
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: ...
message: Successfully created or updated ClusterResourcePlacementStatus in namespace
'test-ns'
observedGeneration: 1
reason: StatusSyncSucceeded
status: "True"
type: ClusterResourcePlacementStatusSynced # Only present for NamespaceAccessible CRPs to indicate corresponding ClusterResourcePlacementStatus is created/updated successfully.
- lastTransitionTime: ...
message: All 3 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: ...
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: ...
message: Works(s) are succcesfully created or updated in 3 target cluster(s)'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: ...
message: The selected resources are successfully applied to 3 cluster(s)
observedGeneration: 1
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: ...
message: The selected resources in 3 cluster(s) are available now
observedGeneration: 1
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
...
selectedResources:
- kind: Namespace
name: test-ns
version: v1
- kind: ConfigMap
name: test-cm
namespace: test-ns
version: v1
Let’s take a look at the corresponding ClusterResourcePlacementStatus object created in test-ns namespace selected by our NamespaceAccessible ClusterResourcePlacement.
% kubectl get clusterresourceplacementstatus.v1beta1.placement.kubernetes-fleet.io test-crp -n test-ns -o yaml
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacementStatus
lastUpdatedTime: ...
metadata:
creationTimestamp: ...
generation: 11
name: test-crp
namespace: test-ns
ownerReferences:
- apiVersion: placement.kubernetes-fleet.io/v1beta1
blockOwnerDeletion: true
controller: true
kind: ClusterResourcePlacement
name: test-crp
uid: 7877ff66-74db-4f13-b84a-91e43da5d06e
resourceVersion: "1837"
uid: df6adcc3-54a3-41d8-b954-a72992a4e35f
sourceStatus:
conditions:
- lastTransitionTime: ...
message: found all cluster needed as specified by the scheduling policy, found
3 cluster(s)
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: ...
message: All 3 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: ...
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: ...
message: Works(s) are succcesfully created or updated in 3 target cluster(s)'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: ...
message: The selected resources are successfully applied to 3 cluster(s)
observedGeneration: 1
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: ...
message: The selected resources in 3 cluster(s) are available now
observedGeneration: 1
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
...
selectedResources:
- kind: Namespace
name: test-ns
version: v1
- kind: ConfigMap
name: test-cm
namespace: test-ns
version: v1
Note: From the output above we can see that the ClusterResourcePlacementSyncedCondition condition is not part of the copied status from the ClusterResourcePlacement.
This allows users with only namespace-level access to view the status of the cluster-scoped ClusterResourcePlacement object within the target namespace.
Snapshots and revisions
Internally, Fleet keeps a history of all the scheduling policies you have used with a
ClusterResourcePlacement, and all the resource versions (snapshots) the
ClusterResourcePlacement has selected. These are kept as ClusterSchedulingPolicySnapshot
and ClusterResourceSnapshot objects respectively.
You can list and view such objects for reference, but you should not modify their contents
(in a typical setup, such requests will be rejected automatically). To control the length
of the history (i.e., how many snapshot objects Fleet will keep for a ClusterResourcePlacement),
configure the revisionHistoryLimit field:
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
...
strategy:
...
revisionHistoryLimit: 10
The default value is 10.
Note
In this early stage, the history is kept for reference purposes only; in the future, Fleet
may add features to allow rolling back to a specific scheduling policy and/or resource version.
3.3 - Using the ResourcePlacement API
How to use the ResourcePlacement API
This guide provides an overview of how to use the KubeFleet ResourcePlacement (RP) API to orchestrate workload distribution across your fleet.
NOTE: The ResourcePlacement is a namespace-scoped CR.
Overview
The RP API is a core KubeFleet API that facilitates the distribution of specific resources from the hub cluster to
member clusters within a fleet. This API offers scheduling capabilities that allow you to target the most suitable
group of clusters for a set of resources using a complex rule set. For example, you can distribute resources to
clusters in specific regions (North America, East Asia, Europe, etc.) and/or release stages (production, canary, etc.).
You can even distribute resources according to certain topology spread constraints.
API Components
The RP API generally consists of the following components:
- Resource Selectors: These specify the set of resources selected for placement.
- Scheduling Policy: This determines the set of clusters where the resources will be placed.
- Rollout Strategy: This controls the behavior of resource placement when the resources themselves and/or the
scheduling policy are updated, minimizing interruptions caused by refreshes.
The following sections discuss these components in depth.
Resource selectors
A ResourcePlacement object may feature one or more resource selectors,
specifying which resources to select for placement. To add a resource selector, edit
the resourceSelectors field in the ResourcePlacement spec:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ResourcePlacement
metadata:
name: rp
namespace: test-ns
spec:
resourceSelectors:
- group: "rbac.authorization.k8s.io"
kind: Role
version: v1
name: secretReader
The example above will pick a Role named secretReader for resource placement.
It is important to note that, as its name implies, ResourcePlacement selects only
namespace-scoped resources. It only places the resources selected within the namespaces
where the ResourcePlacement object itself resides.
Different types of resource selectors
You can specify a resource selector in many different ways:
To select one specific resource, such as a deployment, specify its API GVK (group, version, and
kind), and its name, in the resource selector:
# As mentioned earlier, the resource selector will only pick resources under the same namespace as the RP object.
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: work
Alternately, you may also select a set of resources of the same API GVK using a label selector;
it also requires that you specify the API GVK and the filtering label(s):
# As mentioned earlier, the resource selector will only pick resources under the same namespace as the RP object.
resourceSelectors:
- group: apps
kind: Deployment
version: v1
labelSelector:
matchLabels:
system: critical
In the example above, all the deployments in namespace test-ns with the label system=critical in the hub cluster
will be selected.
Fleet uses standard Kubernetes label selectors; for its specification and usage, see the
Kubernetes API reference.
Very occasionally, you may need to select all the resources under a specific GVK; to achieve
this, use a resource selector with only the API GVK added:
resourceSelectors:
- group: apps
kind: Deployment
version: v1
In the example above, all the deployments in test-ns in the hub cluster will be picked.
Multiple resource selectors
You may specify up to 100 different resource selectors; Fleet will pick a resource if it matches
any of the resource selectors specified (i.e., all selectors are OR’d).
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: work
- group: "rbac.authorization.k8s.io"
kind: Role
version: v1
name: secretReader
In the example above, Fleet will pick the deployment work and the role secretReader in the namespace test-ns.
Note
You can find the GVKs of built-in Kubernetes API objects in the
Kubernetes API reference.
Scheduling policy
Each scheduling policy is associated with a placement type, which determines how KubeFleet will
pick clusters. The ResourcePlacement API supports the same placement types as ClusterResourcePlacement;
for more information about placement types, see the ClusterResourcePlacement - Scheduling Policy How-To Guide.
Rollout strategy
The rollout strategy controls how KubeFleet rolls out changes; for more information, see the ClusterResourcePlacement - Rollout Strategy How-To Guide.
3.4 - Using Affinity to Pick Clusters
How to use affinity settings in the ClusterResourcePlacement API to fine-tune Fleet scheduling decisions
This how-to guide discusses how to use affinity settings to fine-tune how Fleet picks clusters
for resource placement.
Affinities terms are featured in the ClusterResourcePlacement API, specifically the scheduling
policy section. Each affinity term is a particular requirement that Fleet will check against clusters;
and the fulfillment of this requirement (or the lack of) would have certain effect on whether
Fleet would pick a cluster for resource placement.
Fleet currently supports two types of affinity terms:
requiredDuringSchedulingIgnoredDuringExecution affinity terms; andperferredDuringSchedulingIgnoredDuringExecution affinity terms
Most affinity terms deal with cluster labels. To manage member clusters, specifically
adding/removing labels from a member cluster, see Managing Member Clusters How-To
Guide.
requiredDuringSchedulingIgnoredDuringExecution affinity terms
The requiredDuringSchedulingIgnoredDuringExecution type of affinity terms serves as a hard
constraint that a cluster must satisfy before it can be picked. Each term may feature:
- a label selector, which specifies a set of labels that a cluster must have or not have before
it can be picked;
- a property selector, which specifies a cluster property requirement that a cluster must satisfy
before it can be picked;
- a combination of both.
For the specifics about property selectors, see the
How-To Guide: Using Property-Based Scheduling.
matchLabels
The most straightforward way is to specify matchLabels in the label selector, as showcased below:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickAll
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
system: critical
The example above includes a requiredDuringSchedulingIgnoredDuringExecution term which requires
that the label system=critical must be present on a cluster before Fleet can pick it for the
ClusterResourcePlacement.
You can add multiple labels to matchLabels; any cluster that satisfy this affinity term would
have all the labels present.
matchExpressions
For more complex logic, consider using matchExpressions, which allow you to use operators to
set rules for validating labels on a member cluster. Each matchExpressions requirement
includes:
a key, which is the key of the label; and
a list of values, which are the possible values for the label key; and
an operator, which represents the relationship between the key and the list of values.
Supported operators include:
In: the cluster must have a label key with one of the listed values.
NotIn: the cluster must have a label key that is not associated with any of the listed values.
Exists: the cluster must have the label key present; any value is acceptable.
NotExists: the cluster must not have the label key.
If you plan to use Exists and/or NotExists, you must leave the list of values empty.
Below is an example of matchExpressions affinity term using the In operator:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickAll
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchExpressions:
- key: system
operator: In
values:
- critical
- standard
Any cluster with the label system=critical or system=standard will be picked by Fleet.
Similarly, you can also specify multiple matchExpressions requirements; any cluster that
satisfy this affinity term would meet all the requirements.
Using both matchLabels and matchExpressions in one affinity term
You can specify both matchLabels and matchExpressions in one requiredDuringSchedulingIgnoredDuringExecution affinity term, as showcased below:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickAll
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
region: east
matchExpressions:
- key: system
operator: Exists
With this affinity term, any cluster picked must:
- have the label
region=east present; - have the label
system present, any value would do.
Using multiple affinity terms
You can also specify multiple requiredDuringSchedulingIgnoredDuringExecution affinity terms,
as showcased below; a cluster will be picked if it can satisfy any affinity term.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickAll
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
region: west
- labelSelector:
matchExpressions:
- key: system
operator: DoesNotExist
With these two affinity terms, any cluster picked must:
- have the label
region=west present; or - does not have the label
system
preferredDuringSchedulingIgnoredDuringExecution affinity terms
The preferredDuringSchedulingIgnoredDuringExecution type of affinity terms serves as a soft
constraint for clusters; any cluster that satisfy such terms would receive an affinity score,
which Fleet uses to rank clusters when processing ClusterResourcePlacement with scheduling
policy of the PickN placement type.
Each term features:
- a weight, between -100 and 100, which is the affinity score that Fleet would assign to a
cluster if it satisfies this term; and
- a label selector, or a property sorter.
Both are required for this type of affinity terms to function.
The label selector is of the same struct as the one used in
requiredDuringSchedulingIgnoredDuringExecution type of affinity terms; see
the documentation above for usage.
For the specifics about property sorters, see the
How-To Guide: Using Property-Based Scheduling.
Below is an example with a preferredDuringSchedulingIgnoredDuringExecution affinity term:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickN
numberOfClusters: 10
affinity:
clusterAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 20
preference:
labelSelector:
matchLabels:
region: west
Any cluster with the region=west label would receive an affinity score of 20.
Using multiple affinity terms
Similarly, you can use multiple preferredDuringSchedulingIgnoredDuringExection affinity terms,
as showcased below:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickN
numberOfClusters: 10
affinity:
clusterAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 20
preference:
labelSelector:
matchLabels:
region: west
- weight: -20
preference:
labelSelector:
matchLabels:
environment: prod
Cluster will be validated against each affinity term individually; the affinity scores it
receives will be summed up. For example:
- if a cluster has only the
region=west label, it would receive an affinity score of 20; however - if a cluster has both the
region=west and environment=prod labels, it would receive an
affinity score of 20 + (-20) = 0.
Use both types of affinity terms
You can, if necessary, add both requiredDuringSchedulingIgnoredDuringExecution and
preferredDuringSchedulingIgnoredDuringExection types of affinity terms. Fleet will
first run all clusters against all the requiredDuringSchedulingIgnoredDuringExecution type
of affinity terms, filter out any that does not meet the requirements, and then
assign the rest with affinity scores per preferredDuringSchedulingIgnoredDuringExection type of
affinity terms.
Below is an example with both types of affinity terms:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickN
numberOfClusters: 10
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchExpressions:
- key: system
operator: Exists
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 20
preference:
labelSelector:
matchLabels:
region: west
With these affinity terms, only clusters with the label system (any value would do) can be
picked; and among them, those with the region=west will be prioritized for resource placement
as they receive an affinity score of 20.
3.5 - Using Topology Spread Constraints to Spread Resources
How to use topology spread constraints in the ClusterResourcePlacement API to fine-tune Fleet scheduling decisions
This how-to guide discusses how to use topology spread constraints to fine-tune how Fleet picks
clusters for resource placement.
Topology spread constraints are features in the ClusterResourcePlacement API, specifically
the scheduling policy section. Generally speaking, these constraints can help you spread
resources evenly across different groups of clusters in your fleet; or in other words, it
assures that Fleet will not pick too many clusters from one group, and too little from another.
You can use topology spread constraints to, for example:
- achieve high-availability for your database backend by making sure that there is at least
one database replica in each region; or
- verify if your application can support clusters of different configurations; or
- eliminate resource utilization hotspots in your infrastructure through spreading jobs
evenly across sections.
Specifying a topology spread constraint
A topology spread constraint consists of three fields:
topologyKey is a label key which Fleet uses to split your clusters from a fleet into different
groups.
Specifically, clusters are grouped by the label values they have. For example, if you have
three clusters in a fleet:
cluster bravelion with the label system=critical and region=east; and
cluster smartfish with the label system=critical and region=west; and
cluster jumpingcat with the label system=normal and region=east,
and you use system as the topology key, the clusters will be split into 2 groups:
group 1 with cluster bravelion and smartfish, as they both have the value critical
for label system; and
group 2 with cluster jumpingcat, as it has the value normal for label system.
Note that the splitting concerns only one label system; other labels,
such as region, do not count.
If a cluster does not have the given topology key, it does not belong to any group.
Fleet may still pick this cluster, as placing resources on it does not violate the
associated topology spread constraint.
This is a required field.
maxSkew specifies how unevenly resource placements are spread in your fleet.
The skew of a set of resource placements are defined as the difference in count of
resource placements between the group with the most and the group with
the least, as split by the topology key.
For example, in the fleet described above (3 clusters, 2 groups):
if Fleet picks two clusters from group A, but none from group B, the skew would be
2 - 0 = 2; however,
if Fleet picks one cluster from group A and one from group B, the skew would be
1 - 1 = 0.
The minimum value of maxSkew is 1. The less you set this value with, the more evenly
resource placements are spread in your fleet.
This is a required field.
Note
Naturally, maxSkew only makes sense when there are no less than two groups. If you
set a topology key that will not split the Fleet at all (i.e., all clusters with
the given topology key has exactly the same value), the associated topology spread
constraint will take no effect.
whenUnsatisfiable specifies what Fleet would do when it exhausts all options to satisfy the
topology spread constraint; that is, picking any cluster in the fleet would lead to a violation.
Two options are available:
DoNotSchedule: with this option, Fleet would guarantee that the topology spread constraint
will be enforced all time; scheduling may fail if there is simply no possible way to satisfy
the topology spread constraint.
ScheduleAnyway: with this option, Fleet would enforce the topology spread constraint
in a best-effort manner; Fleet may, however, pick clusters that would violate the topology
spread constraint if there is no better option.
This is an optional field; if you do not specify a value, Fleet will use DoNotSchedule by
default.
Below is an example of topology spread constraint, which tells Fleet to pick clusters evenly
from different groups, split based on the value of the label system:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickN
numberOfClusters: 3
topologySpreadConstraints:
- maxSkew: 2
topologyKey: system
whenUnsatisfiable: DoNotSchedule
How Fleet enforces topology spread constraints: topology spread scores
When you specify some topology spread constraints in the scheduling policy of
a ClusterResourcePlacement object, Fleet will start picking clusters one at a time.
More specifically, Fleet will:
for each cluster in the fleet, evaluate how skew would change if resources were placed on it.
Depending on the current spread of resource placements, there are three possible outcomes:
placing resources on the cluster reduces the skew by 1; or
placing resources on the cluster has no effect on the skew; or
placing resources on the cluster increases the skew by 1.
Fleet would then assign a topology spread score to the cluster:
if the provisional placement reduces the skew by 1, the cluster receives a topology spread
score of 1; or
if the provisional placement has no effect on the skew, the cluster receives a topology
spread score of 0; or
if the provisional placement increases the skew by 1, but does not yet exceed the max skew
specified in the constraint, the cluster receives a topology spread score of -1; or
if the provisional placement increases the skew by 1, and has exceeded the max skew specified in the constraint,
- for topology spread constraints with the
ScheduleAnyway effect, the cluster receives a topology spread score of -1000; and - for those with the
DoNotSchedule effect, the cluster will be removed from
resource placement consideration.
rank the clusters based on the topology spread score and other factors (e.g., affinity),
pick the one that is most appropriate.
repeat the process, until all the needed count of clusters are found.
Below is an example that illustrates the process:
Suppose you have a fleet of 4 clusters:
- cluster
bravelion, with label region=east and system=critical; and - cluster
smartfish, with label region=east; and - cluster
jumpingcat, with label region=west, and system=critical; and - cluster
flyingpenguin, with label region=west,
And you have created a ClusterResourcePlacement as follows:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickN
numberOfClusters: 2
topologySpreadConstraints:
- maxSkew: 1
topologyKey: region
whenUnsatisfiable: DoNotSchedule
Fleet will first scan all the 4 clusters in the fleet; they all have the region label, with
two different values east and west (2 cluster in each of them). This divides the clusters
into two groups, the east and the west
At this stage, no cluster has been picked yet, so there is no resource placement at all. The
current skew is thus 0, and placing resources on any of them would increase the skew by 1. This
is still below the maxSkew threshold given, so all clusters would receive a topology spread
score of -1.
Fleet could not find the most appropriate cluster based on the topology spread score so far,
so it would resort to other measures for ranking clusters. This would lead Fleet to pick cluster
smartfish.
Note
See Using ClusterResourcePlacement to Place Resources How-To Guide for more
information on how Fleet picks clusters.
Now, one cluster has been picked, and one more is needed by the ClusterResourcePlacement
object (as the numberOfClusters field is set to 2). Fleet scans the left 3 clusters again,
and this time, since smartfish from group east has been picked, any more resource placement
on clusters from group east would increase the skew by 1 more, and would lead to violation
of the topology spread constraint; Fleet will then assign the topology spread score of -1000 to
cluster bravelion, which is in group east. On the contrary, picking a cluster from any
cluster in group west would reduce the skew by 1, so Fleet assigns the topology spread score
of 1 to cluster jumpingcat and flyingpenguin.
With the higher topology spread score, jumpingcat and flyingpenguin become the leading
candidate in ranking. They have the same topology spread score, and based on the rules Fleet
has for picking clusters, jumpingcat would be picked finally.
Using multiple topology spread constraints
You can, if necessary, use multiple topology spread constraints. Fleet will evaluate each of them
separately, and add up topology spread scores for each cluster for the final ranking. A cluster
would be removed from resource placement consideration if placing resources on it would violate
any one of the DoNotSchedule topology spread constraints.
Below is an example where two topology spread constraints are used:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickN
numberOfClusters: 2
topologySpreadConstraints:
- maxSkew: 2
topologyKey: region
whenUnsatisfiable: DoNotSchedule
- maxSkew: 3
topologyKey: environment
whenUnsatisfiable: ScheduleAnyway
Note
It might be very difficult to find candidate clusters when multiple topology spread constraints
are added. Considering using the ScheduleAnyway effect to add some leeway to the scheduling,
if applicable.
3.6 - Using Property-Based Scheduling
How to use property-based scheduling to produce scheduling decisions
This how-to guide discusses how to use property-based scheduling to produce scheduling decisions
based on cluster properties.
Note
The availability of properties depend on which (and if) you have a property provider
set up in your Fleet deployment. For more information, see the
Concept: Property Provider and Cluster Properties
documentation.
It is also recommended that you read the
How-To Guide: Using Affinity to Pick Clusters first before following
instructions in this document.
Fleet allows users to pick clusters based on exposed cluster properties via the affinity
terms in the ClusterResourcePlacement API:
- for the
requiredDuringSchedulingIgnoredDuringExecution affinity terms, you may specify
property selectors to filter clusters based on their properties; - for the
preferredDuringSchedulingIgnoredDuringExecution affinity terms, you may specify
property sorters to prefer clusters with a property that ranks higher or lower.
Property selectors in requiredDuringSchedulingIgnoredDuringExecution affinity terms
A property selector is an array of expression matchers against cluster properties.
In each matcher you will specify:
A name, which is the name of the property.
If the property is a non-resource one, you may refer to it directly here; however, if the
property is a resource one, the name here should be of the following format:
resources.kubernetes-fleet.io/[CAPACITY-TYPE]-[RESOURCE-NAME]
where [CAPACITY-TYPE] is one of total, allocatable, or available, depending on
which capacity (usage information) you would like to check against, and [RESOURCE-NAME] is
the name of the resource.
For example, if you would like to select clusters based on the available CPU capacity of
a cluster, the name used in the property selector should be
resources.kubernetes-fleet.io/available-cpu
and for the allocatable memory capacity, use
resources.kubernetes-fleet.io/allocatable-memory
A list of values, which are possible values of the property.
An operator, which describes the relationship between a cluster’s observed value of the given
property and the list of values in the matcher.
Currently, available operators are
Gt (Greater than): a cluster’s observed value of the given property must be greater than
the value in the matcher before it can be picked for resource placement.
Ge (Greater than or equal to): a cluster’s observed value of the given property must be
greater than or equal to the value in the matcher before it can be picked for resource placement.
Lt (Less than): a cluster’s observed value of the given property must be less than
the value in the matcher before it can be picked for resource placement.
Le (Less than or equal to): a cluster’s observed value of the given property must be
less than or equal to the value in the matcher before it can be picked for resource placement.
Eq (Equal to): a cluster’s observed value of the given property must be equal to
the value in the matcher before it can be picked for resource placement.
Ne (Not equal to): a cluster’s observed value of the given property must be
not equal to the value in the matcher before it can be picked for resource placement.
Note that if you use the operator Gt, Ge, Lt, Le, Eq, or Ne, the list of values
in the matcher should have exactly one value.
Fleet will evaluate each cluster, specifically their exposed properties, against the matchers;
failure to satisfy any matcher in the selector will exclude the cluster from resource
placement.
Note that if a cluster does not have the specified property for a matcher, it will automatically
fail the matcher.
Below is an example that uses a property selector to select only clusters with a node count of
at least 5 for resource placement:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickAll
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- propertySelector:
matchExpressions:
- name: "kubernetes-fleet.io/node-count"
operator: Ge
values:
- "5"
You may use both label selector and property selector in a
requiredDuringSchedulingIgnoredDuringExecution affinity term. Both selectors must be satisfied
before a cluster can be picked for resource placement:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickAll
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
region: east
propertySelector:
matchExpressions:
- name: "kubernetes-fleet.io/node-count"
operator: Ge
values:
- "5"
In the example above, Fleet will only consider a cluster for resource placement if it has the
region=east label and a node count no less than 5.
Property sorters in preferredDuringSchedulingIgnoredDuringExecution affinity terms
A property sorter ranks all the clusters in the Fleet based on their values of a specified
property in ascending or descending order, then yields weights for the clusters in proportion
to their ranks. The proportional weights are calculated based on the weight value given in the
preferredDuringSchedulingIgnoredDuringExecution term.
A property sorter consists of:
A name, which is the name of the property; see the format in the previous section for more
information.
A sort order, which is one of Ascending and Descending, for ranking in ascending and
descending order respectively.
As a rule of thumb, when the Ascending order is used, Fleet will prefer clusters with lower
observed values, and when the Descending order is used, clusters with higher observed values
will be preferred.
When using the sort order Descending, the proportional weight is calculated using the formula:
((Observed Value - Minimum observed value) / (Maximum observed value - Minimum observed value)) * Weight
For example, suppose that you would like to rank clusters based on the property of available CPU
capacity in descending order and currently, you have a fleet of 3 clusters with the available CPU
capacities as follows:
| Cluster | Available CPU capacity |
|---|
| bravelion | 100 |
| smartfish | 20 |
| jumpingcat | 10 |
The sorter would yield the weights below:
| Cluster | Available CPU capacity | Weight |
|---|
| bravelion | 100 | (100 - 10) / (100 - 10) = 100% of the weight |
| smartfish | 20 | (20 - 10) / (100 - 10) = 11.11% of the weight |
| jumpingcat | 10 | (10 - 10) / (100 - 10) = 0% of the weight |
And when using the sort order Ascending, the proportional weight is calculated using the formula:
(1 - ((Observed Value - Minimum observed value) / (Maximum observed value - Minimum observed value))) * Weight
For example, suppose that you would like to rank clusters based on their per CPU core cost
in ascending order and currently across the fleet, you have a fleet of 3 clusters with the
per CPU core costs as follows:
| Cluster | Per CPU core cost |
|---|
| bravelion | 1 |
| smartfish | 0.2 |
| jumpingcat | 0.1 |
The sorter would yield the weights below:
| Cluster | Per CPU core cost | Weight |
|---|
| bravelion | 1 | 1 - ((1 - 0.1) / (1 - 0.1)) = 0% of the weight |
| smartfish | 0.2 | 1 - ((0.2 - 0.1) / (1 - 0.1)) = 88.89% of the weight |
| jumpingcat | 0.1 | 1 - (0.1 - 0.1) / (1 - 0.1) = 100% of the weight |
The example below showcases a property sorter using the Descending order:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickN
numberOfClusters: 10
affinity:
clusterAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 20
preference:
propertySorter:
name: kubernetes-fleet.io/node-count
sortOrder: Descending
In this example, Fleet will prefer clusters with higher node counts. The cluster with the highest
node count would receive a weight of 20, and the cluster with the lowest would receive 0. Other
clusters receive proportional weights calculated using the formulas above.
You may use both label selector and property sorter in a
preferredDuringSchedulingIgnoredDuringExecution affinity term. A cluster that fails the label
selector would receive no weight, and clusters that pass the label selector receive proportional
weights under the property sorter.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp
spec:
resourceSelectors:
- ...
policy:
placementType: PickN
numberOfClusters: 10
affinity:
clusterAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 20
preference:
labelSelector:
matchLabels:
env: prod
propertySorter:
name: resources.kubernetes-fleet.io/total-cpu
sortOrder: Descending
In the example above, a cluster would only receive additional weight if it has the label
env=prod, and the more total CPU capacity it has, the more weight it will receive, up to the
limit of 20.
3.7 - Using Taints and Tolerations
How to use taints and tolerations to fine-tune scheduling decisions
This how-to guide discusses how to add/remove taints on MemberCluster and how to add tolerations on ClusterResourcePlacement.
Adding taint to MemberCluster
In this example, we will add a taint to a MemberCluster. Then try to propagate resources to the MemberCluster using a ClusterResourcePlacement
with PickAll placement policy. The resources should not be propagated to the MemberCluster because of the taint.
We will first create a namespace that we will propagate to the member cluster,
kubectl create ns test-ns
Then apply the MemberCluster with a taint,
Example MemberCluster with taint:
apiVersion: cluster.kubernetes-fleet.io/v1beta1
kind: MemberCluster
metadata:
name: kind-cluster-1
spec:
identity:
name: fleet-member-agent-cluster-1
kind: ServiceAccount
namespace: fleet-system
apiGroup: ""
taints:
- key: test-key1
value: test-value1
effect: NoSchedule
After applying the above MemberCluster, we will apply a ClusterResourcePlacement with the following spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: test-ns
policy:
placementType: PickAll
The ClusterResourcePlacement CR should not propagate the test-ns namespace to the member cluster because of the taint,
looking at the status of the CR should show the following:
status:
conditions:
- lastTransitionTime: "2024-04-16T19:03:17Z"
message: found all the clusters needed as specified by the scheduling policy
observedGeneration: 2
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-04-16T19:03:17Z"
message: All 0 cluster(s) are synchronized to the latest resources on the hub
cluster
observedGeneration: 2
reason: SynchronizeSucceeded
status: "True"
type: ClusterResourcePlacementSynchronized
- lastTransitionTime: "2024-04-16T19:03:17Z"
message: There are no clusters selected to place the resources
observedGeneration: 2
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
observedResourceIndex: "0"
selectedResources:
- kind: Namespace
name: test-ns
version: v1
Looking at the ClusterResourcePlacementSynchronized, ClusterResourcePlacementApplied conditions and reading the message fields
we can see that no clusters were selected to place the resources.
Removing taint from MemberCluster
In this example, we will remove the taint from the MemberCluster from the last section. This should automatically trigger the Fleet scheduler to propagate the resources to the MemberCluster.
After removing the taint from the MemberCluster. Let’s take a look at the status of the ClusterResourcePlacement:
status:
conditions:
- lastTransitionTime: "2024-04-16T20:00:03Z"
message: found all the clusters needed as specified by the scheduling policy
observedGeneration: 2
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-04-16T20:02:57Z"
message: All 1 cluster(s) are synchronized to the latest resources on the hub
cluster
observedGeneration: 2
reason: SynchronizeSucceeded
status: "True"
type: ClusterResourcePlacementSynchronized
- lastTransitionTime: "2024-04-16T20:02:57Z"
message: Successfully applied resources to 1 member clusters
observedGeneration: 2
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
observedResourceIndex: "0"
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-04-16T20:02:52Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 2
reason: ScheduleSucceeded
status: "True"
type: Scheduled
- lastTransitionTime: "2024-04-16T20:02:57Z"
message: Successfully Synchronized work(s) for placement
observedGeneration: 2
reason: WorkSynchronizeSucceeded
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-04-16T20:02:57Z"
message: Successfully applied resources
observedGeneration: 2
reason: ApplySucceeded
status: "True"
type: Applied
selectedResources:
- kind: Namespace
name: test-ns
version: v1
From the status we can clearly see that the resources were propagated to the member cluster after removing the taint.
Adding toleration to ClusterResourcePlacement
Adding a toleration to a ClusterResourcePlacement CR allows the Fleet scheduler to tolerate specific taints on the MemberClusters.
For this section we will start from scratch, we will first create a namespace that we will propagate to the MemberCluster
kubectl create ns test-ns
Then apply the MemberCluster with a taint,
Example MemberCluster with taint:
spec:
heartbeatPeriodSeconds: 60
identity:
apiGroup: ""
kind: ServiceAccount
name: fleet-member-agent-cluster-1
namespace: fleet-system
taints:
- effect: NoSchedule
key: test-key1
value: test-value1
The ClusterResourcePlacement CR will not propagate the test-ns namespace to the member cluster because of the taint.
Now we will add a toleration to a ClusterResourcePlacement CR as part of the placement policy, which will use the Exists operator to tolerate the taint.
Example ClusterResourcePlacement spec with tolerations after adding new toleration:
spec:
policy:
placementType: PickAll
tolerations:
- key: test-key1
operator: Exists
resourceSelectors:
- group: ""
kind: Namespace
name: test-ns
version: v1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
Let’s take a look at the status of the ClusterResourcePlacement CR after adding the toleration:
status:
conditions:
- lastTransitionTime: "2024-04-16T20:16:10Z"
message: found all the clusters needed as specified by the scheduling policy
observedGeneration: 3
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-04-16T20:16:15Z"
message: All 1 cluster(s) are synchronized to the latest resources on the hub
cluster
observedGeneration: 3
reason: SynchronizeSucceeded
status: "True"
type: ClusterResourcePlacementSynchronized
- lastTransitionTime: "2024-04-16T20:16:15Z"
message: Successfully applied resources to 1 member clusters
observedGeneration: 3
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
observedResourceIndex: "0"
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-04-16T20:16:10Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 3
reason: ScheduleSucceeded
status: "True"
type: Scheduled
- lastTransitionTime: "2024-04-16T20:16:15Z"
message: Successfully Synchronized work(s) for placement
observedGeneration: 3
reason: WorkSynchronizeSucceeded
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-04-16T20:16:15Z"
message: Successfully applied resources
observedGeneration: 3
reason: ApplySucceeded
status: "True"
type: Applied
selectedResources:
- kind: Namespace
name: test-ns
version: v1
From the status we can see that the resources were propagated to the MemberCluster after adding the toleration.
Now let’s try adding a new taint to the member cluster CR and see if the resources are still propagated to the MemberCluster,
Example MemberCluster CR with new taint:
heartbeatPeriodSeconds: 60
identity:
apiGroup: ""
kind: ServiceAccount
name: fleet-member-agent-cluster-1
namespace: fleet-system
taints:
- effect: NoSchedule
key: test-key1
value: test-value1
- effect: NoSchedule
key: test-key2
value: test-value2
Let’s take a look at the ClusterResourcePlacement CR status after adding the new taint:
status:
conditions:
- lastTransitionTime: "2024-04-16T20:27:44Z"
message: found all the clusters needed as specified by the scheduling policy
observedGeneration: 2
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-04-16T20:27:49Z"
message: All 1 cluster(s) are synchronized to the latest resources on the hub
cluster
observedGeneration: 2
reason: SynchronizeSucceeded
status: "True"
type: ClusterResourcePlacementSynchronized
- lastTransitionTime: "2024-04-16T20:27:49Z"
message: Successfully applied resources to 1 member clusters
observedGeneration: 2
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
observedResourceIndex: "0"
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-04-16T20:27:44Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 2
reason: ScheduleSucceeded
status: "True"
type: Scheduled
- lastTransitionTime: "2024-04-16T20:27:49Z"
message: Successfully Synchronized work(s) for placement
observedGeneration: 2
reason: WorkSynchronizeSucceeded
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-04-16T20:27:49Z"
message: Successfully applied resources
observedGeneration: 2
reason: ApplySucceeded
status: "True"
type: Applied
selectedResources:
- kind: Namespace
name: test-ns
version: v1
Nothing changes in the status because even if the new taint is not tolerated, the exising resources on the MemberCluster
will continue to run because the taint effect is NoSchedule and the cluster was already selected for resource propagation in a
previous scheduling cycle.
3.8 - Using the ClusterResourceOverride API
How to use the ClusterResourceOverride API to override cluster-scoped resources
This guide provides an overview of how to use the Fleet ClusterResourceOverride API to override cluster resources.
Overview
ClusterResourceOverride is a feature within Fleet that allows for the modification or override of specific attributes
across cluster-wide resources. With ClusterResourceOverride, you can define rules based on cluster labels or other
criteria, specifying changes to be applied to various cluster-wide resources such as namespaces, roles, role bindings,
or custom resource definitions. These modifications may include updates to permissions, configurations, or other
parameters, ensuring consistent management and enforcement of configurations across your Fleet-managed Kubernetes clusters.
API Components
The ClusterResourceOverride API consists of the following components:
- Placement: This specifies which placement the override is applied to.
- Cluster Resource Selectors: These specify the set of cluster resources selected for overriding.
- Policy: This specifies the policy to be applied to the selected resources.
The following sections discuss these components in depth.
Placement
To configure which placement the override is applied to, you can use the name of ClusterResourcePlacement.
Cluster Resource Selectors
A ClusterResourceOverride object may feature one or more cluster resource selectors, specifying which resources to select to be overridden.
The ClusterResourceSelector object supports the following fields:
group: The API group of the resourceversion: The API version of the resourcekind: The kind of the resourcename: The name of the resource
Note: The resource can only be selected by name.
To add a resource selector, edit the clusterResourceSelectors field in the ClusterResourceOverride spec:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ClusterResourceOverride
metadata:
name: example-cro
spec:
placement:
name: crp-example
clusterResourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
version: v1
name: secret-reader
The example in the tutorial will pick the ClusterRole named secret-reader, as shown below, to be overridden.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: secret-reader
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]
Policy
The Policy is made up of a set of rules (OverrideRules) that specify the changes to be applied to the selected
resources on selected clusters.
Each OverrideRule supports the following fields:
- Cluster Selector: This specifies the set of clusters to which the override applies.
- Override Type: This specifies the type of override to be applied. The default type is
JSONPatch.JSONPatch: applies the JSON patch to the selected resources using RFC 6902.Delete: deletes the selected resources on the target cluster.
- JSON Patch Override: This specifies the changes to be applied to the selected resources when the override type is
JSONPatch.
Cluster Selector
To specify the clusters to which the override applies, you can use the clusterSelector field in the OverrideRule spec.
The clusterSelector field supports the following fields:
clusterSelectorTerms: A list of terms that are used to select clusters.- Each term in the list is used to select clusters based on the label selector.
IMPORTANT:
Only labelSelector is supported in the clusterSelectorTerms field.
Override Type
To specify the type of override to be applied, you can use the overrideType field in the OverrideRule spec.
The default value is JSONPatch.
JSONPatch: applies the JSON patch to the selected resources using RFC 6902.Delete: deletes the selected resources on the target cluster.
JSON Patch Override
To specify the changes to be applied to the selected resources, you can use the jsonPatchOverrides field in the OverrideRule spec.
The jsonPatchOverrides field supports the following fields:
JSONPatchOverride applies a JSON patch on the selected resources following RFC 6902.
All the fields defined follow this RFC.
op: The operation to be performed. The supported operations are add, remove, and replace.
add: Adds a new value to the specified path.remove: Removes the value at the specified path.replace: Replaces the value at the specified path.
path: The path to the field to be modified.
- Some guidelines for the path are as follows:
- Must start with a
/ character. - Cannot be empty.
- Cannot contain an empty string ("///").
- Cannot be a TypeMeta Field ("/kind", “/apiVersion”).
- Cannot be a Metadata Field ("/metadata/name", “/metadata/namespace”), except the fields “/metadata/annotations” and “metadata/labels”.
- Cannot be any field in the status of the resource.
- Some examples of valid paths are:
/metadata/labels/new-label/metadata/annotations/new-annotation/spec/template/spec/containers/0/resources/limits/cpu/spec/template/spec/containers/0/resources/requests/memory
value: The value to be set.
- If the
op is remove, the value cannot be set. - There is a list of reserved variables that will be replaced by the actual values:
${MEMBER-CLUSTER-NAME}: this will be replaced by the name of the memberCluster that represents this cluster.${MEMBER-CLUSTER-LABEL-KEY-<label-key>}: this will be replaced by the value of the label with the key <label-key> on the memberCluster. For example, ${MEMBER-CLUSTER-LABEL-KEY-region} will be replaced by the value of the region label on the target member cluster. If the label does not exist on the cluster, the override will fail with an error.
Example: Override Labels
To overwrite the existing labels on the ClusterRole named secret-reader on clusters with the label env: prod,
you can use the following configuration:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ClusterResourceOverride
metadata:
name: example-cro
spec:
placement:
name: crp-example
clusterResourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
version: v1
name: secret-reader
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
jsonPatchOverrides:
- op: add
path: /metadata/labels
value:
{"cluster-name":"${MEMBER-CLUSTER-NAME}"}
Note: Using op: add with the path /metadata/labels (pointing to the entire labels map) will replace all existing labels with the value provided. To add a new label to the existing labels, please use the below configuration:
- op: add
path: /metadata/labels/new-label
value: "new-value"
The ClusterResourceOverride object above will add a label cluster-name with the value of the memberCluster name to the ClusterRole named secret-reader on clusters with the label env: prod.
Example: Override Using Cluster Label Variables
To dynamically set a label based on a member cluster’s region label, you can use the ${MEMBER-CLUSTER-LABEL-KEY-<label-key>} variable.
For instance, if your member clusters have a label region with values like us-west or eu-central:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ClusterResourceOverride
metadata:
name: cro-region
spec:
placement:
name: crp-example
clusterResourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
version: v1
name: secret-reader
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms: []
jsonPatchOverrides:
- op: add
path: /metadata/labels/cluster-region
value: "${MEMBER-CLUSTER-LABEL-KEY-region}"
When applied to a cluster with the label region: us-west, the ClusterRole will receive the label cluster-region: us-west.
Note: To replace an existing label value, use op: replace instead (e.g., op: replace with path /metadata/labels/cluster-region). However, op: replace will fail with an error if the label does not already exist on the resource.
You can also use multiple label variables together. For example, to add annotations sourced from cluster labels:
jsonPatchOverrides:
- op: add
path: /metadata/annotations
value:
{"target-region":"${MEMBER-CLUSTER-LABEL-KEY-region}", "target-env":"${MEMBER-CLUSTER-LABEL-KEY-env}"}
On a cluster with labels region: us-west and env: production, the annotations will be set to
target-region: us-west and target-env: production.
Example: Remove Verbs
To remove the verb “list” in the ClusterRole named secret-reader on clusters with the label env: prod,
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ClusterResourceOverride
metadata:
name: example-cro
spec:
placement:
name: crp-example
clusterResourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
version: v1
name: secret-reader
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
jsonPatchOverrides:
- op: remove
path: /rules/0/verbs/2
The ClusterResourceOverride object above will remove the verb “list” in the ClusterRole named secret-reader on
clusters with the label env: prod selected by the clusterResourcePlacement crp-example.
The ClusterResourceOverride mentioned above utilizes the cluster role displayed below:
Name: secret-reader
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
secrets [] [] [get watch list]
Delete
The Delete override type can be used to delete the selected resources on the target cluster.
Example: Delete Selected Resource
To delete the secret-reader on the clusters with the label env: test selected by the clusterResourcePlacement crp-example, you can use the Delete override type.
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ClusterResourceOverride
metadata:
name: example-cro
spec:
placement:
name: crp-example
clusterResourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
version: v1
name: secret-reader
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: test
overrideType: Delete
Multiple Override Patches
You may add multiple JSONPatchOverride to an OverrideRule to apply multiple changes to the selected cluster resources.
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ClusterResourceOverride
metadata:
name: example-cro
spec:
placement:
name: crp-example
clusterResourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
version: v1
name: secret-reader
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
jsonPatchOverrides:
- op: remove
path: /rules/0/verbs/2
- op: remove
path: /rules/0/verbs/1
The ClusterResourceOverride object above will remove the verbs “list” and “watch” in the ClusterRole named
secret-reader on clusters with the label env: prod.
Breaking down the paths
- First
JSONPatchOverride:/rules/0: This denotes the first rule in the rules array of the ClusterRole. In the provided ClusterRole definition,
there’s only one rule defined (“secrets”), so this corresponds to the first (and only) rule./verbs/2: Within this rule, the third element of the verbs array is targeted (“list”).
- Second
JSONPatchOverride:/rules/0: This denotes the first rule in the rules array of the ClusterRole. In the provided ClusterRole definition,
there’s only one rule defined (“secrets”), so this corresponds to the first (and only) rule./verbs/1: Within this rule, the second element of the verbs array is targeted (“watch”).
The ClusterResourceOverride mentioned above utilizes the cluster role displayed below:
Name: secret-reader
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
secrets [] [] [get watch list]
Applying the ClusterResourceOverride
Create a ClusterResourcePlacement resource to specify the placement rules for distributing the cluster resource overrides across
the cluster infrastructure. Ensure that you select the appropriate resource.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp-example
spec:
resourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
version: v1
name: secret-reader
policy:
placementType: PickAll
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
- labelSelector:
matchLabels:
env: test
The ClusterResourcePlacement configuration outlined above will disperse resources across all clusters labeled with env: prod.
As the changes are implemented, the corresponding ClusterResourceOverride configurations will be applied to the
designated clusters, triggered by the selection of matching cluster role resource secret-reader.
Verifying the Cluster Resource is Overridden
To ensure that the ClusterResourceOverride object is applied to the selected clusters, verify the ClusterResourcePlacement
status by running kubectl describe crp crp-example command:
Status:
Conditions:
...
Message: The selected resources are successfully overridden in the 10 clusters
Observed Generation: 1
Reason: OverriddenSucceeded
Status: True
Type: ClusterResourcePlacementOverridden
...
Observed Resource Index: 0
Placement Statuses:
Applicable Cluster Resource Overrides:
example-cro-0
Cluster Name: member-50
Conditions:
...
Message: Successfully applied the override rules on the resources
Observed Generation: 1
Reason: OverriddenSucceeded
Status: True
Type: Overridden
...
Each cluster maintains its own Applicable Cluster Resource Overrides which contain the cluster resource override snapshot
if relevant. Additionally, individual status messages for each cluster indicate whether the override rules have been
effectively applied.
The ClusterResourcePlacementOverridden condition indicates whether the resource override has been successfully applied
to the selected resources in the selected clusters.
To verify that the ClusterResourceOverride object has been successfully applied to the selected resources,
check resources in the selected clusters:
- Get cluster credentials:
az aks get-credentials --resource-group <resource-group> --name <cluster-name> - Get the
ClusterRole object in the selected cluster:
kubectl --context=<member-cluster-context> get clusterrole secret-reader -o yaml
Upon inspecting the described ClusterRole object, it becomes apparent that the verbs “watch” and “list” have been
removed from the permissions list within the ClusterRole named “secret-reader” on the prod clusters.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
...
rules:
- apiGroups:
- ""
resources:
- secrets
verbs:
- get
Similarly, you can verify that this cluster role does not exist in the test clusters.
3.9 - Using the ResourceOverride API
How to use the ResourceOverride API to override namespace-scoped resources
This guide provides an overview of how to use the Fleet ResourceOverride API to override resources.
Overview
ResourceOverride is a Fleet API that allows you to modify or override specific attributes of
existing resources within your cluster. With ResourceOverride, you can define rules based on cluster
labels or other criteria, specifying changes to be applied to resources such as Deployments, StatefulSets, ConfigMaps, or Secrets.
These changes can include updates to container images, environment variables, resource limits, or any other configurable parameters.
API Components
The ResourceOverride API consists of the following components:
- Placement: This specifies which placement the override is applied to.
- Resource Selectors: These specify the set of resources selected for overriding.
- Policy: This specifies the policy to be applied to the selected resources.
The following sections discuss these components in depth.
Placement
To configure which placement the override is applied to, you can use the name of ClusterResourcePlacement.
Resource Selectors
A ResourceOverride object may feature one or more resource selectors, specifying which resources to select to be overridden.
The ResourceSelector object supports the following fields:
group: The API group of the resourceversion: The API version of the resourcekind: The kind of the resourcename: The name of the resource
Note: The resource can only be selected by name.
To add a resource selector, edit the resourceSelectors field in the ResourceOverride spec:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
name: example-ro
namespace: test-namespace
spec:
placement:
name: crp-example
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: my-deployment
Note: The ResourceOverride needs to be in the same namespace as the resources it is overriding.
The examples in the tutorial will pick a Deployment named my-deployment from the namespace test-namespace, as shown below, to be overridden.
apiVersion: apps/v1
kind: Deployment
metadata:
...
name: my-deployment
namespace: test-namespace
...
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
app: test-nginx
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: test-nginx
spec:
containers:
- image: nginx:1.14.2
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
...
Policy
The Policy is made up of a set of rules (OverrideRules) that specify the changes to be applied to the selected
resources on selected clusters.
Each OverrideRule supports the following fields:
- Cluster Selector: This specifies the set of clusters to which the override applies.
- Override Type: This specifies the type of override to be applied. The default type is
JSONPatch.JSONPatch: applies the JSON patch to the selected resources using RFC 6902.Delete: deletes the selected resources on the target cluster.
- JSON Patch Override: This specifies the changes to be applied to the selected resources when the override type is
JSONPatch.
Cluster Selector
To specify the clusters to which the override applies, you can use the clusterSelector field in the OverrideRule spec.
The clusterSelector field supports the following fields:
clusterSelectorTerms: A list of terms that are used to select clusters.- Each term in the list is used to select clusters based on the label selector.
IMPORTANT:
Only labelSelector is supported in the clusterSelectorTerms field.
Override Type
To specify the type of override to be applied, you can use the overrideType field in the OverrideRule spec.
The default value is JSONPatch.
JSONPatch: applies the JSON patch to the selected resources using RFC 6902.Delete: deletes the selected resources on the target cluster.
JSON Patch Override
To specify the changes to be applied to the selected resources, you can use the jsonPatchOverrides field in the OverrideRule spec.
The jsonPatchOverrides field supports the following fields:
JSONPatchOverride applies a JSON patch on the selected resources following RFC 6902.
All the fields defined follow this RFC.
The jsonPatchOverrides field supports the following fields:
op: The operation to be performed. The supported operations are add, remove, and replace.
add: Adds a new value to the specified path.remove: Removes the value at the specified path.replace: Replaces the value at the specified path.
path: The path to the field to be modified.
- Some guidelines for the path are as follows:
- Must start with a
/ character. - Cannot be empty.
- Cannot contain an empty string ("///").
- Cannot be a TypeMeta Field ("/kind", “/apiVersion”).
- Cannot be a Metadata Field ("/metadata/name", “/metadata/namespace”), except the fields “/metadata/annotations” and “metadata/labels”.
- Cannot be any field in the status of the resource.
- Some examples of valid paths are:
/metadata/labels/new-label/metadata/annotations/new-annotation/spec/template/spec/containers/0/resources/limits/cpu/spec/template/spec/containers/0/resources/requests/memory
value: The value to be set.
- If the
op is remove, the value cannot be set. - There is a list of reserved variables that will be replaced by the actual values:
${MEMBER-CLUSTER-NAME}: this will be replaced by the name of the memberCluster that represents this cluster.${MEMBER-CLUSTER-LABEL-KEY-<label-key>}: this will be replaced by the value of the label with the key <label-key> on the memberCluster. For example, ${MEMBER-CLUSTER-LABEL-KEY-region} will be replaced by the value of the region label on the target member cluster. If the label does not exist on the cluster, the override will fail with an error.
Example: Override Labels
To overwrite the existing labels on the Deployment named my-deployment on clusters with the label env: prod,
you can use the following configuration:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
name: example-ro
namespace: test-namespace
spec:
placement:
name: crp-example
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: my-deployment
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
jsonPatchOverrides:
- op: add
path: /metadata/labels
value:
{"cluster-name":"${MEMBER-CLUSTER-NAME}"}
Note: Using op: add with the path /metadata/labels (pointing to the entire labels map) will replace all existing labels with the value provided. To add a new label to the existing labels, please use the below configuration:
- op: add
path: /metadata/labels/new-label
value: "new-value"
The ResourceOverride object above will add a label cluster-name with the value of the memberCluster name to the Deployment named example-ro on clusters with the label env: prod.
Example: Override Using Cluster Label Variables
To dynamically customize resources based on member cluster labels, you can use the ${MEMBER-CLUSTER-LABEL-KEY-<label-key>} variable.
For instance, if your member clusters have labels such as region: us-west and env: production, you can inject
those values into a deployment’s annotations:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
name: ro-label-vars
namespace: test-namespace
spec:
placement:
name: crp-example
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: my-deployment
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms: []
jsonPatchOverrides:
- op: add
path: /metadata/annotations
value:
{"target-region":"${MEMBER-CLUSTER-LABEL-KEY-region}", "target-env":"${MEMBER-CLUSTER-LABEL-KEY-env}"}
When applied to a cluster with labels region: us-west and env: production, the deployment will receive the
annotations target-region: us-west and target-env: production.
You can also combine multiple variables in a single value. For example, to construct a container image path
from cluster labels:
jsonPatchOverrides:
- op: replace
path: /spec/template/spec/containers/0/image
value: "myregistry-${MEMBER-CLUSTER-LABEL-KEY-region}.example.com/my-app:${MEMBER-CLUSTER-LABEL-KEY-env}"
On a cluster with region: us-west and env: staging, this would resolve to
myregistry-us-west.example.com/my-app:staging.
Example: Override Image
To override the image of the container in the Deployment named my-deployment on all clusters with the label env: prod:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
name: example-ro
namespace: test-namespace
spec:
placement:
name: crp-example
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: my-deployment
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
jsonPatchOverrides:
- op: replace
path: /spec/template/spec/containers/0/image
value: "nginx:1.20.0"
The ResourceOverride object above will replace the image of the container in the Deployment named my-deployment
with the image nginx:1.20.0 on all clusters with the label env: prod selected by the clusterResourcePlacement crp-example.
The ResourceOverride mentioned above utilizes the deployment displayed below:
apiVersion: apps/v1
kind: Deployment
metadata:
...
name: my-deployment
namespace: test-namespace
...
spec:
...
template:
...
spec:
containers:
- image: nginx:1.14.2
imagePullPolicy: IfNotPresent
name: nginx
ports:
...
...
...
Delete
The Delete override type can be used to delete the selected resources on the target cluster.
Example: Delete Selected Resource
To delete the my-deployment on the clusters with the label env: test selected by the clusterResourcePlacement crp-example,
you can use the Delete override type.
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
name: example-ro
namespace: test-namespace
spec:
placement:
name: crp-example
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: my-deployment
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: test
overrideType: Delete
Multiple Override Rules
You may add multiple OverrideRules to a Policy to apply multiple changes to the selected resources.
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
name: example-ro
namespace: test-namespace
spec:
placement:
name: crp-example
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: my-deployment
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
jsonPatchOverrides:
- op: replace
path: /spec/template/spec/containers/0/image
value: "nginx:1.20.0"
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: test
jsonPatchOverrides:
- op: replace
path: /spec/template/spec/containers/0/image
value: "nginx:latest"
The ResourceOverride object above will replace the image of the container in the Deployment named my-deployment
with the image nginx:1.20.0 on all clusters with the label env: prod and the image nginx:latest on all clusters with the label env: test.
The ResourceOverride mentioned above utilizes the deployment displayed below:
apiVersion: apps/v1
kind: Deployment
metadata:
...
name: my-deployment
namespace: test-namespace
...
spec:
...
template:
...
spec:
containers:
- image: nginx:1.14.2
imagePullPolicy: IfNotPresent
name: nginx
ports:
...
...
...
Applying the ResourceOverride
Create a ClusterResourcePlacement resource to specify the placement rules for distributing the resource overrides across
the cluster infrastructure. Ensure that you select the appropriate namespaces containing the matching resources.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp-example
spec:
resourceSelectors:
- group: ""
kind: Namespace
name: test-namespace
version: v1
policy:
placementType: PickAll
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
- labelSelector:
matchLabels:
env: test
The ClusterResourcePlacement configuration outlined above will disperse resources within test-namespace across all
clusters labeled with env: prod and env: test. As the changes are implemented, the corresponding ResourceOverride
configurations will be applied to the designated clusters, triggered by the selection of matching deployment resource
my-deployment.
Verifying the Cluster Resource is Overridden
To ensure that the ResourceOverride object is applied to the selected resources, verify the ClusterResourcePlacement
status by running kubectl describe crp crp-example command:
Status:
Conditions:
...
Message: The selected resources are successfully overridden in the 10 clusters
Observed Generation: 1
Reason: OverriddenSucceeded
Status: True
Type: ClusterResourcePlacementOverridden
...
Observed Resource Index: 0
Placement Statuses:
Applicable Resource Overrides:
Name: example-ro-0
Namespace: test-namespace
Cluster Name: member-50
Conditions:
...
Message: Successfully applied the override rules on the resources
Observed Generation: 1
Reason: OverriddenSucceeded
Status: True
Type: Overridden
...
Each cluster maintains its own Applicable Resource Overrides which contain the resource override snapshot and
the resource override namespace if relevant. Additionally, individual status messages for each cluster indicates
whether the override rules have been effectively applied.
The ClusterResourcePlacementOverridden condition indicates whether the resource override has been successfully applied
to the selected resources in the selected clusters.
To verify that the ResourceOverride object has been successfully applied to the selected resources,
check resources in the selected clusters:
- Get cluster credentials:
az aks get-credentials --resource-group <resource-group> --name <cluster-name> - Get the
Deployment object in the selected cluster:
kubectl --context=<member-cluster-context> get deployment my-deployment -n test-namespace -o yaml
Upon inspecting the member cluster, it was found that the selected cluster had the label env: prod.
Consequently, the image on deployment my-deployment was modified to be nginx:1.20.0 on selected cluster.
apiVersion: apps/v1
kind: Deployment
metadata:
...
name: my-deployment
namespace: test-namespace
...
spec:
...
template:
...
spec:
containers:
- image: nginx:1.20.0
imagePullPolicy: IfNotPresent
name: nginx
ports:
...
...
status:
...
3.10 - Using Envelope Objects to Place Resources
How to use envelope objects with the ClusterResourcePlacement API
Propagating Resources with Envelope Objects
This guide provides instructions on propagating a set of resources from the hub cluster to joined member clusters within an envelope object.
Why Use Envelope Objects?
When propagating resources to member clusters using Fleet, it’s important to understand that the hub cluster itself is also a Kubernetes cluster. Without envelope objects, any resource you want to propagate would first be applied directly to the hub cluster, which can lead to some potential side effects:
Unintended Side Effects: Resources like ValidatingWebhookConfigurations, MutatingWebhookConfigurations, or Admission Controllers would become active on the hub cluster, potentially intercepting and affecting hub cluster operations.
Security Risks: RBAC resources (Roles, ClusterRoles, RoleBindings, ClusterRoleBindings) intended for member clusters could grant unintended permissions on the hub cluster.
Resource Limitations: ResourceQuotas, FlowSchema or LimitRanges defined for member clusters would take effect on the hub cluster. While this is generally not a critical issue, there may be cases where you want to avoid these constraints on the hub.
Envelope objects solve these problems by allowing you to define resources that should be propagated without actually deploying their contents on the hub cluster. The envelope object itself is applied to the hub, but the resources it contains are only extracted and applied when they reach the member clusters.
Envelope Objects with CRDs
Fleet now supports two types of envelope Custom Resource Definitions (CRDs) for propagating resources:
- ClusterResourceEnvelope: Used to wrap cluster-scoped resources for placement.
- ResourceEnvelope: Used to wrap namespace-scoped resources for placement.
These CRDs provide a more structured and Kubernetes-native way to package resources for propagation to member clusters without causing unintended side effects on the hub cluster.
ClusterResourceEnvelope Example
The ClusterResourceEnvelope is a cluster-scoped resource that can only wrap other cluster-scoped resources. For example:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourceEnvelope
metadata:
name: example
data:
"webhook.yaml":
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
name: guard
webhooks:
- name: guard.example.com
rules:
- operations: ["CREATE"]
apiGroups: ["*"]
apiVersions: ["*"]
resources: ["*"]
clientConfig:
service:
name: guard
namespace: ops
admissionReviewVersions: ["v1"]
sideEffects: None
timeoutSeconds: 10
"clusterrole.yaml":
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
ResourceEnvelope Example
The ResourceEnvelope is a namespace-scoped resource that can only wrap namespace-scoped resources. For example:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ResourceEnvelope
metadata:
name: example
namespace: app
data:
"cm.yaml":
apiVersion: v1
kind: ConfigMap
metadata:
name: config
namespace: app
data:
foo: bar
"deploy.yaml":
apiVersion: apps/v1
kind: Deployment
metadata:
name: ingress
namespace: app
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: web
image: nginx
Propagating envelope objects from hub cluster to member cluster
We apply our envelope objects on the hub cluster and then use a ClusterResourcePlacement object to propagate these resources from the hub to member clusters.
Example CRP spec for propagating a ResourceEnvelope
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp-with-envelope
spec:
policy:
clusterNames:
- kind-cluster-1
placementType: PickFixed
resourceSelectors:
- group: ""
kind: Namespace
name: app
version: v1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
Example CRP spec for propagating a ClusterResourceEnvelope
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: crp-with-cluster-envelop
spec:
policy:
clusterNames:
- kind-cluster-1
placementType: PickFixed
resourceSelectors:
- group: placement.kubernetes-fleet.io
kind: ClusterResourceEnvelope
name: example
version: v1beta1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
CRP status for ResourceEnvelope
status:
conditions:
- lastTransitionTime: "2023-11-30T19:54:13Z"
message: found all the clusters needed as specified by the scheduling policy
observedGeneration: 2
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2023-11-30T19:54:18Z"
message: All 1 cluster(s) are synchronized to the latest resources on the hub
cluster
observedGeneration: 2
reason: SynchronizeSucceeded
status: "True"
type: ClusterResourcePlacementSynchronized
- lastTransitionTime: "2023-11-30T19:54:18Z"
message: Successfully applied resources to 1 member clusters
observedGeneration: 2
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2023-11-30T19:54:13Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1:
picked by scheduling policy'
observedGeneration: 2
reason: ScheduleSucceeded
status: "True"
type: ResourceScheduled
- lastTransitionTime: "2023-11-30T19:54:18Z"
message: Successfully Synchronized work(s) for placement
observedGeneration: 2
reason: WorkSynchronizeSucceeded
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2023-11-30T19:54:18Z"
message: Successfully applied resources
observedGeneration: 2
reason: ApplySucceeded
status: "True"
type: ResourceApplied
selectedResources:
- kind: Namespace
name: app
version: v1
- group: placement.kubernetes-fleet.io
kind: ResourceEnvelope
name: example
namespace: app
version: v1beta1
Note: In the selectedResources section, we specifically display the propagated envelope object. We do not individually list all the resources contained within the envelope object in the status.
Upon inspection of the selectedResources, it indicates that the namespace app and the ResourceEnvelope example have been successfully propagated. Users can further verify the successful propagation of resources contained within the envelope object by ensuring that the failedPlacements section in the placementStatus for the target cluster does not appear in the status.
Example CRP status where resources within an envelope object failed to apply
CRP status with failed ResourceEnvelope resource
In the example below, within the placementStatus section for kind-cluster-1, the failedPlacements section provides details on a resource that failed to apply along with information about the envelope object which contained the resource.
status:
conditions:
- lastTransitionTime: "2023-12-06T00:09:53Z"
message: found all the clusters needed as specified by the scheduling policy
observedGeneration: 2
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2023-12-06T00:09:58Z"
message: All 1 cluster(s) are synchronized to the latest resources on the hub
cluster
observedGeneration: 2
reason: SynchronizeSucceeded
status: "True"
type: ClusterResourcePlacementSynchronized
- lastTransitionTime: "2023-12-06T00:09:58Z"
message: Failed to apply manifests to 1 clusters, please check the `failedPlacements`
status
observedGeneration: 2
reason: ApplyFailed
status: "False"
type: ClusterResourcePlacementApplied
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2023-12-06T00:09:53Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1:
picked by scheduling policy'
observedGeneration: 2
reason: ScheduleSucceeded
status: "True"
type: ResourceScheduled
- lastTransitionTime: "2023-12-06T00:09:58Z"
message: Successfully Synchronized work(s) for placement
observedGeneration: 2
reason: WorkSynchronizeSucceeded
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2023-12-06T00:09:58Z"
message: Failed to apply manifests, please check the `failedPlacements` status
observedGeneration: 2
reason: ApplyFailed
status: "False"
type: ResourceApplied
failedPlacements:
- condition:
lastTransitionTime: "2023-12-06T00:09:53Z"
message: 'Failed to apply manifest: namespaces "app" not found'
reason: AppliedManifestFailedReason
status: "False"
type: Applied
envelope:
name: example
namespace: app
type: ResourceEnvelope
kind: Deployment
name: ingress
namespace: app
version: apps/v1
selectedResources:
- kind: Namespace
name: app
version: v1
- group: placement.kubernetes-fleet.io
kind: ResourceEnvelope
name: example
namespace: app
version: v1beta1
CRP status with failed ClusterResourceEnvelope resource
Similar to namespace-scoped resources, cluster-scoped resources within a ClusterResourceEnvelope can also fail to apply:
status:
conditions:
- lastTransitionTime: "2023-12-06T00:09:53Z"
message: found all the clusters needed as specified by the scheduling policy
observedGeneration: 2
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2023-12-06T00:09:58Z"
message: Failed to apply manifests to 1 clusters, please check the `failedPlacements`
status
observedGeneration: 2
reason: ApplyFailed
status: "False"
type: ClusterResourcePlacementApplied
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2023-12-06T00:09:58Z"
message: Failed to apply manifests, please check the `failedPlacements` status
observedGeneration: 2
reason: ApplyFailed
status: "False"
type: ResourceApplied
failedPlacements:
- condition:
lastTransitionTime: "2023-12-06T00:09:53Z"
message: 'Failed to apply manifest: service "guard" not found in namespace "ops"'
reason: AppliedManifestFailedReason
status: "False"
type: Applied
envelope:
name: example
type: ClusterResourceEnvelope
kind: ValidatingWebhookConfiguration
name: guard
group: admissionregistration.k8s.io
version: v1
selectedResources:
- group: placement.kubernetes-fleet.io
kind: ClusterResourceEnvelope
name: example
version: v1beta1
3.11 - Controlling How Fleet Handles Pre-Existing Resources
How to fine-tune the way Fleet handles pre-existing resources
This guide provides an overview on how to set up Fleet’s takeover experience, which allows
developers and admins to choose what will happen when Fleet encounters a pre-existing resource.
This occurs most often in the Fleet adoption scenario, where a cluster just joins into a fleet and
the system finds out that the resources to place onto the new member cluster via the CRP API have
already been running there.
A concern commonly associated with this scenario is that the running (pre-existing) set of
resources might have configuration differences from their equivalents on the hub cluster,
for example: On the hub cluster one might have a namespace work where it hosts a deployment
web-server that runs the image rpd-stars:latest; while on the member cluster in the same
namespace lives a deployment of the same name but with the image umbrella-biolab:latest.
If Fleet applies the resource template from the hub cluster, unexpected service interruptions
might occur.
To address this concern, Fleet also introduces a new field, whenToTakeOver, in the apply
strategy. Three options are available:
Always: This is the default option 😑. With this setting, Fleet will take over a
pre-existing resource as soon as it encounters it. Fleet will apply the corresponding
resource template from the hub cluster, and any value differences in the managed fields
will be overwritten. This is consistent with the behavior before the new takeover experience is
added.IfNoDiff: This is the new option ✨ provided by the takeover mechanism. With this setting,
Fleet will check for configuration differences when it finds a pre-existing resource and
will only take over the resource (apply the resource template) if no configuration
differences are found. Consider using this option for a safer adoption journey.Never: This is another new option ✨ provided by the takeover mechanism. With this setting,
Fleet will ignore pre-existing resources and no apply op will be performed. This will be considered
as an apply error. Use this option if you would like to check for the presence of pre-existing
resources without taking any action.
Before you begin
The new takeover experience is currently in preview.
Note that the APIs for the new experience are only available in the Fleet v1beta1 API, not the v1 API. If you do not see the new APIs in command outputs, verify that you are explicitly requesting the v1beta1 API objects, as opposed to the v1 API objects (the default).
How Fleet can be used to safely take over pre-existing resources
The steps below explain how the takeover experience functions. The code assumes that you have
a fleet of two clusters, member-1 and member-2:
Switch to the second member cluster, and create a namespace, work-2, with labels:
kubectl config use-context member-2-admin
kubectl create ns work-2
kubectl label ns work-2 app=work-2
kubectl label ns work-2 owner=wesker
Switch to the hub cluster, and create the same namespace, but with a slightly different set of labels:
kubectl config use-context hub-admin
kubectl create ns work-2
kubectl label ns work-2 app=work-2
kubectl label ns work-2 owner=redfield
Create a CRP object that places the namespace to all member clusters:
cat <<EOF | kubectl apply -f -
# The YAML configuration of the CRP object.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: work-2
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
# Select all namespaces with the label app=work.
labelSelector:
matchLabels:
app: work-2
policy:
placementType: PickAll
strategy:
# For simplicity reasons, the CRP is configured to roll out changes to
# all member clusters at once. This is not a setup recommended for production
# use.
type: RollingUpdate
rollingUpdate:
maxUnavailable: 100%
unavailablePeriodSeconds: 1
applyStrategy:
whenToTakeOver: Never
EOF
Give Fleet a few seconds to handle the placement. Check the status of the CRP object; you should see a failure there that complains about an apply error on the cluster member-2:
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work -o jsonpath='{.status.placementStatuses}' | jq
# The command above uses JSON paths to query the relevant status information
# directly and uses the jq utility to pretty print the output JSON.
#
# jq might not be available in your environment. You may have to install it
# separately, or omit it from the command.
#
# If the output is empty, the status might have not been populated properly
# yet. Retry in a few seconds; you may also want to switch the output type
# from jsonpath to yaml to see the full object.
The output should look like this:
{
"clusterName": "member-1",
"conditions": [
...
{
...
"status": "True",
"type": "Applied"
}
]
},
{
"clusterName": "member-2",
"conditions": [
...
{
...
"status": "False",
"type": "Applied"
}
],
"failedPlacements": ...
}
You can take a look at the failedPlacements part in the placement status for error details:
The output should look like this:
[
{
"condition": {
"lastTransitionTime": "...",
"message": "Failed to apply the manifest (error: no ownership of the object in the member cluster; takeover is needed)",
"reason": "NotTakenOver",
"status": "False",
"type": "Applied"
},
"kind": "Namespace",
"name": "work-2",
"version": "v1"
}
]
Fleet finds out that the namespace work-2 already exists on the member cluster, and
it is not owned by Fleet; since the takeover policy is set to Never, Fleet will not assume
ownership of the namespace; no apply will be performed and an apply error will be raised
instead.
The following jq query can help you better locate clusters with failed placements and their
failure details:
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work -o jsonpath='{.status.placementStatuses}' \
| jq '[.[] | select (.failedPlacements != null)] | map({clusterName, failedPlacements})'
# The command above uses JSON paths to retrieve the relevant status information
# directly and uses the jq utility to query the data.
#
# jq might not be available in your environment. You may have to install it
# separately, or omit it from the command.
It would filter out all the clusters that do not have failures and report only
the failed clusters with the failure details:
{
"clusterName": "member-2",
"failedPlacements": [
{
"condition": {
"lastTransitionTime": "...",
"message": "Failed to apply the manifest (error: no ownership of the object in the member cluster; takeover is needed)",
"reason": "NotTakenOver",
"status": "False",
"type": "Applied"
},
"kind": "Namespace",
"name": "work-2",
"version": "v1"
}
]
}
Next, update the CRP object and set the whenToTakeOver field to IfNoDiff:
cat <<EOF | kubectl apply -f -
# The YAML configuration of the CRP object.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: work-2
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
# Select all namespaces with the label app=work.
labelSelector:
matchLabels:
app: work-2
policy:
placementType: PickAll
strategy:
# For simplicity reasons, the CRP is configured to roll out changes to
# all member clusters at once. This is not a setup recommended for production
# use.
type: RollingUpdate
rollingUpdate:
maxUnavailable: 100%
unavailablePeriodSeconds: 1
applyStrategy:
whenToTakeOver: IfNoDiff
EOF
Give Fleet a few seconds to handle the placement. Check the status of the CRP object; you should see the apply op still fails.
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work-2
Verify the error details reported in the failedPlacements field for another time:
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work -o jsonpath='{.status.placementStatuses}' \
| jq '[.[] | select (.failedPlacements != null)] | map({clusterName, failedPlacements})'
# The command above uses JSON paths to retrieve the relevant status information
# directly and uses the jq utility to query the data.
#
# jq might not be available in your environment. You may have to install it
# separately, or omit it from the command.
The output has changed:
{
"clusterName": "member-2",
"failedPlacements": [
{
"condition": {
"lastTransitionTime": "...",
"message": "Failed to apply the manifest (error: cannot take over object: configuration differences are found between the manifest object and the corresponding object in the member cluster)",
"reason": "FailedToTakeOver",
"status": "False",
"type": "Applied"
},
"kind": "Namespace",
"name": "work-2",
"version": "v1"
}
]
}
Now, with the takeover policy set to IfNoDiff, Fleet can assume ownership of pre-existing
resources; however, as a configuration difference has been found between the hub cluster
and the member cluster, takeover is blocked.
Similar to the drift detection mechanism, Fleet will report details about the found
configuration differences as well. You can learn about them in the diffedPlacements part
of the status.
Use the jq query below to list all clusters with the diffedPlacements status information
populated:
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work -o jsonpath='{.status.placementStatuses}' \
| jq '[.[] | select (.diffedPlacements != null)] | map({clusterName, diffedPlacements})'
# The command above uses JSON paths to retrieve the relevant status information
# directly and uses the jq utility to query the data.
#
# jq might not be available in your environment. You may have to install it
# separately, or omit it from the command.
{
"clusterName": "member-2",
"diffedPlacements": [
{
"firstDiffedObservedTime": "...",
"group": "",
"version": "v1",
"kind": "Namespace",
"name": "work-2",
"observationTime": "...",
"observedDiffs": [
{
"path": "/metadata/labels/owner",
"valueInHub": "redfield",
"valueInMember": "wesker"
}
],
"targetClusterObservedGeneration": 0
}
]
}
Fleet will report the following information about a configuration difference:
group, kind, version, namespace, and name: the resource that has configuration differences.observationTime: the timestamp where the current diff detail is collected.firstDiffedObservedTime: the timestamp where the current diff is first observed.observedDiffs: the diff details, specifically:path: A JSON path (RFC 6901) that points to the diff’d field;valueInHub: the value at the JSON path as seen from the hub cluster resource template
(the desired state). If this value is absent, the field does not exist in the resource template.valueInMember: the value at the JSON path as seen from the member cluster resource
(the current state). If this value is absent, the field does not exist in the current state.
targetClusterObservedGeneration: the generation of the member cluster resource.
To fix the configuration difference, consider one of the following options:
Switch the whenToTakeOver setting back to Always, which will instruct Fleet to take over the resource right away and overwrite all configuration differences; or
Edit the diff’d field directly on the member cluster side, so that the value is consistent with that on the hub cluster; Fleet will periodically re-evaluate diffs and should take over the resource soon after.
Delete the resource from the member cluster. Fleet will then re-apply the resource template and re-create the resource.
Here the guide will take the first option available, setting the whenToTakeOver field to
Always:
cat <<EOF | kubectl apply -f -
# The YAML configuration of the CRP object.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: work-2
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
# Select all namespaces with the label app=work.
labelSelector:
matchLabels:
app: work-2
policy:
placementType: PickAll
strategy:
# For simplicity reasons, the CRP is configured to roll out changes to
# all member clusters at once. This is not a setup recommended for production
# use.
type: RollingUpdate
rollingUpdate:
maxUnavailable: 100%
unavailablePeriodSeconds: 1
applyStrategy:
whenToTakeOver: Always
EOF
Check the CRP status; in a few seconds, Fleet will report that all objects have been applied.
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work-2
If you switch to the member cluster member-2 now, you should see that the object looks
exactly the same as the resource template kept on the hub cluster; the owner label has been
over-written.
Important
When Fleet fails to take over an object, the pre-existing resource will not be put under Fleet’s management: any change made on the hub cluster side will have no effect on the pre-existing resource. If you choose to delete the resource template, or remove the CRP object, Fleet will not attempt to delete the pre-existing resource.
Takeover and comparison options
Fleet provides a comparisonOptions setting that allows you to fine-tune how Fleet calculates configuration differences between a resource template created on the hub cluster and the corresponding pre-existing resource on a member cluster.
Note
The comparisonOptions setting also controls how Fleet detects drifts. See the how-to guide on drift detection for more information.
If partialComparison is used, Fleet will only report configuration differences in managed fields, i.e., fields that are explicitly specified in the resource template; the presence of additional fields on the member cluster side will not stop Fleet from taking over the pre-existing resource; on the contrary, with fullComparison, Fleet will only take over a pre-existing resource if it looks exactly the same as its hub cluster counterpart.
Below is a table that summarizes the combos of different options and their respective effects:
whenToTakeOver setting | comparisonOption setting | Configuration difference scenario | Outcome |
|---|
IfNoDiff | partialComparison | There exists a value difference in a managed field between a pre-existing resource on a member cluster and the hub cluster resource template. | Fleet will report an apply error in the status, plus the diff details. |
IfNoDiff | partialComparison | The pre-existing resource has a field that is absent on the hub cluster resource template. | Fleet will take over the resource; the configuration difference in the unmanaged field will be left untouched. |
IfNoDiff | fullComparison | Difference has been found on a field, managed or not. | Fleet will report an apply error in the status, plus the diff details. |
Always | Any option | Difference has been found on a field, managed or not. | Fleet will take over the resource; configuration differences in unmanaged fields will be left untouched. |
3.12 - Enabling Drift Detection in Fleet
How to enable drift detection in Fleet
This guide provides an overview on how to enable drift detection in Fleet. This feature can help
developers and admins identify (and act upon) configuration drifts in their KubeFleet system,
which are often brought by temporary fixes, inadvertent changes, and failed automations.
Before you begin
The new drift detection experience is currently in preview.
Note that the APIs for the new experience are only available in the Fleet v1beta1 API, not the v1 API. If you do not see the new APIs in command outputs, verify that you are explicitly requesting the v1beta1 API objects, as opposed to the v1 API objects (the default).
What is a drift?
A drift occurs when a non-Fleet agent (e.g., a developer or a controller) makes changes to
a field of a Fleet-managed resource directly on the member cluster side without modifying
the corresponding resource template created on the hub cluster.
See the steps below for an example; the code assumes that you have a Fleet of two clusters,
member-1 and member-2.
Switch to the hub cluster in the preview environment:
kubectl config use-context hub-admin
Create a namespace, work, on the hub cluster, with some labels:
kubectl create ns work
kubectl label ns work app=work
kubectl label ns work owner=redfield
Create a CRP object, which places the namespace on all member clusters:
cat <<EOF | kubectl apply -f -
# The YAML configuration of the CRP object.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: work
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
# Select all namespaces with the label app=work.
labelSelector:
matchLabels:
app: work
policy:
placementType: PickAll
strategy:
# For simplicity reasons, the CRP is configured to roll out changes to
# all member clusters at once. This is not a setup recommended for production
# use.
type: RollingUpdate
rollingUpdate:
maxUnavailable: 100%
unavailablePeriodSeconds: 1
EOF
Fleet should be able to finish the placement within seconds. To verify the progress, run the command below:
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work
Confirm that in the output, Fleet has reported that the placement is of the Available state.
Switch to the first member cluster, member-1:
kubectl config use-context member-1-admin
You should see the namespace, work, being placed in this member cluster:
kubectl get ns work --show-labels
The output should look as follows; note that all the labels have been set
(the kubernetes.io/metadata.name label is added by the Kubernetes system automatically):
NAME STATUS AGE LABELS
work Active 91m app=work,owner=redfield,kubernetes.io/metadata.name=work
Anyone with proper access to the member cluster could modify the namespace as they want;
for example, one can set the owner label to a different value:
kubectl label ns work owner=wesker --overwrite
kubectl label ns work use=hack --overwrite
Now the namespace has drifted from its intended state.
Note that drifts are not necessarily a bad thing: to ensure system availability, often developers
and admins would need to make ad-hoc changes to the system; for example, one might need to set a
Deployment on a member cluster to use a different image from its template (as kept on the hub
cluster) to test a fix. In the current version of Fleet, the system is not drift-aware, which
means that Fleet will simply re-apply the resource template periodically with or without drifts.
In the case above:
Since the owner label has been set on the resource template, its value would be overwritten by
Fleet, from wesker to redfield, within minutes. This provides a great consistency guarantee
but also blocks out all possibilities of expedient fixes/changes, which can be an inconvenience at times.
The use label is not a part of the resource template, so it will not be affected by any
apply op performed by Fleet. Its prolonged presence might pose an issue, depending on the
nature of the setup.
How Fleet can be used to handle drifts gracefully
Fleet aims to provide an experience that:
- ✅ allows developers and admins to make changes on the member cluster side when necessary; and
- ✅ helps developers and admins to detect drifts, esp. long-living ones, in their systems,
so that they can be handled properly; and
- ✅ grants developers and admins great flexibility on when and how drifts should be handled.
To enable the new experience, set proper apply strategies in the CRP object, as
illustrated by the steps below:
Switch to the hub cluster:
kubectl config use-context hub-admin
Update the existing CRP (work), to use an apply strategy with the whenToApply field set to
IfNotDrifted:
cat <<EOF | kubectl apply -f -
# The YAML configuration of the CRP object.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: work
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
# Select all namespaces with the label app=work.
labelSelector:
matchLabels:
app: work
policy:
placementType: PickAll
strategy:
applyStrategy:
whenToApply: IfNotDrifted
# For simplicity reasons, the CRP is configured to roll out changes to
# all member clusters at once. This is not a setup recommended for production
# use.
type: RollingUpdate
rollingUpdate:
maxUnavailable: 100%
unavailablePeriodSeconds: 1
EOF
The whenToApply field features two options:
Always: this is the default option 😑. With this setting, Fleet will periodically apply
the resource templates from the hub cluster to member clusters, with or without drifts.
This is consistent with the behavior before the new drift detection and takeover experience.IfNotDrifted: this is the new option ✨ provided by the drift detection mechanism. With
this setting, Fleet will check for drifts periodically; if drifts are found, Fleet will stop
applying the resource templates and report in the CRP status.
Switch to the first member cluster and edit the labels for a second time, effectively re-introducing
a drift in the system. After it’s done, switch back to the hub cluster:
kubectl config use-context member-1-admin
kubectl label ns work owner=wesker --overwrite
kubectl label ns work use=hack --overwrite
#
kubectl config use-context hub-admin
Fleet should be able to find the drifts swiftly (w/in a few seconds). Inspect the placement status Fleet
reports for each cluster:
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work -o jsonpath='{.status.placementStatuses}' | jq
# The command above uses JSON paths to query the relevant status information
# directly and uses the jq utility to pretty print the output JSON.
#
# jq might not be available in your environment. You may have to install it
# separately, or omit it from the command.
#
# If the output is empty, the status might have not been populated properly
# yet. Retry in a few seconds; you may also want to switch the output type
# from jsonpath to yaml to see the full object.
The output should look like this:
{
"clusterName": "member-1",
"conditions": [
...
{
...
"status": "False",
"type": "Applied"
}
],
"driftedPlacements": [
{
"firstDriftedObservedTime": "...",
"kind": "Namespace",
"name": "work",
"observationTime": "...",
"observedDrifts": [
{
"path": "/metadata/labels/owner",
"valueInHub": "redfield",
"valueInMember": "wesker"
}
],
"targetClusterObservedGeneration": 0,
"version": "v1"
}
],
"failedPlacements": [
{
"condition": {
"lastTransitionTime": "...",
"message": "Failed to apply the manifest (error: cannot apply manifest: drifts are found between the manifest and the object from the member cluster)",
"reason": "FoundDrifts",
"status": "False",
"type": "Applied"
},
"kind": "Namespace",
"name": "work",
"version": "v1"
}
]
},
{
"clusterName": "member-2",
"conditions": [...]
}
You should see that cluster member-1 has encountered an apply failure. The
failedPlacements part explains exactly which manifests have failed on member-1
and its reason; in this case, the apply op fails as Fleet finds out that the namespace
work has drifted from its intended state. The driftedPlacements part specifies in
detail which fields have drifted and the value differences between the hub
cluster and the member cluster.
Fleet will report the following information about a drift:
group, kind, version, namespace, and name: the resource that has drifted from its desired state.
observationTime: the timestamp where the current drift detail is collected.
firstDriftedObservedTime: the timestamp where the current drift is first observed.
observedDrifts: the drift details, specifically:
path: A JSON path (RFC 6901) that points to the drifted field;valueInHub: the value at the JSON path as seen from the hub cluster resource template
(the desired state). If this value is absent, the field does not exist in the resource template.valueInMember: the value at the JSON path as seen from the member cluster resource
(the current state). If this value is absent, the field does not exist in the current state.
targetClusterObservedGeneration: the generation of the member cluster resource.
The following jq query can help you better extract the drifted clusters and the drift
details from the CRP status output:
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work -o jsonpath='{.status.placementStatuses}' \
| jq '[.[] | select (.driftedPlacements != null)] | map({clusterName, driftedPlacements})'
# The command above uses JSON paths to query the relevant status information
# directly and uses the jq utility to pretty print the output JSON.
#
# jq might not be available in your environment. You may have to install it
# separately, or omit it from the command.
This query would filter out all the clusters that do not have drifts and report only
the drifted clusters with the drift details:
{
"clusterName": "member-1",
"driftedPlacements": [
{
"firstDriftedObservedTime": "...",
"kind": "Namespace",
"name": "work",
"observationTime": "...",
"observedDrifts": [
{
"path": "/metadata/labels/owner",
"valueInHub": "redfield",
"valueInMember": "wesker"
}
],
"targetClusterObservedGeneration": 0,
"version": "v1"
}
]
}
To fix the drift, consider one of the following options:
Switch the whenToApply setting back to Always, which will instruct Fleet to overwrite
the drifts using values from the hub cluster resource template; or
Edit the drifted field directly on the member cluster side, so that the value is
consistent with that on the hub cluster; Fleet will periodically re-evaluate drifts
and should report that no drifts are found soon after.
Delete the resource from the member cluster. Fleet will then re-apply the resource
template and re-create the resource.
Important:
The presence of drifts will NOT stop Fleet from rolling out newer resource versions. If you choose to edit the resource template on the hub cluster, Fleet will always apply the new resource template in the rollout process, which may also resolve the drift.
Comparison options
One may have found out that the namespace on the member cluster has another drift, the
label use=hack, which is not reported in the CRP status by Fleet. This is because by default
Fleet compares only managed fields, i.e., fields that are explicitly specified in the resource
template. If a field is not populated on the hub cluster side, Fleet will not recognize its
presence on the member cluster side as a drift. This allows controllers on the member cluster
side to manage some fields automatically without Fleet’s involvement; for example, one might would
like to use an HPA solution to auto-scale Deployments as appropriate and consequently decide not
to include the .spec.replicas field in the resource template.
Fleet recognizes that there might be cases where developers and admins would like to have their
resources look exactly the same across their fleet. If this scenario applies, one might set up
the comparisonOptions field in the apply strategy from the partialComparison value
(the default) to fullComparison:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: work
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
labelSelector:
matchLabels:
app: work
policy:
placementType: PickAll
strategy:
applyStrategy:
whenToApply: IfNotDrifted
comparisonOption: fullComparison
With this setting, Fleet will recognize the presence of any unmanaged fields (i.e., fields that
are present on the member cluster side, but not set on the hub cluster side) as drifts as well.
If anyone adds a field to a Fleet-managed object directly on the member cluster, it would trigger
an apply error, which you can find out about the details the same way as illustrated in the
section above.
Summary
Below is a summary of the synergy between the whenToApply and comparisonOption settings:
whenToApply setting | comparisonOption setting | Drift scenario | Outcome |
|---|
IfNotDrifted | partialComparison | A managed field (i.e., a field that has been explicitly set in the hub cluster resource template) is edited. | Fleet will report an apply error in the status, plus the drift details. |
IfNotDrifted | partialComparison | An unmanaged field (i.e., a field that has not been explicitly set in the hub cluster resource template) is edited/added. | N/A; the change is left untouched, and Fleet will ignore it. |
IfNotDrifted | fullComparison | Any field is edited/added. | Fleet will report an apply error in the status, plus the drift details. |
Always | partialComparison | A managed field (i.e., a field that has been explicitly set in the hub cluster resource template) is edited. | N/A; the change is overwritten shortly. |
Always | partialComparison | An unmanaged field (i.e., a field that has not been explicitly set in the hub cluster resource template) is edited/added. | N/A; the change is left untouched, and Fleet will ignore it. |
Always | fullComparison | Any field is edited/added. | The change on managed fields will be overwritten shortly; Fleet will report drift details about changes on unmanaged fields, but this is not considered as an apply error. |
3.13 - Using the ReportDiff Apply Mode
How to use the ReportDiff apply mode
This guide provides an overview on how to use the ReportDiff apply mode, which allows one to
easily evaluate how things will change in the system without the risk of incurring unexpected
changes. In this mode, Fleet will check for configuration differences between the hub cluster
resource templates and their corresponding resources on the member clusters, but will not
perform any apply op. This is most helpful in cases of experimentation and drift/diff analysis.
How the ReportDiff mode can help
To use this mode, simply set the type field in the apply strategy part of the CRP API
from ClientSideApply (the default) or ServerSideApply to ReportDiff. Configuration
differences are checked per comparisonOption setting, in consistency with the behavior
documented in the drift detection how-to guide; see the document for more information.
The steps below might help explain the workflow better; it assumes that you have a fleet
of two member clusters, member-1 and member-2:
Switch to the hub cluster and create a namespace, work-3, with some labels.
kubectl config use-context hub-admin
kubectl create ns work-3
kubectl label ns work-3 app=work-3
kubectl label ns work-3 owner=leon
Create a CRP object that places the namespace to all member clusters:
cat <<EOF | kubectl apply -f -
# The YAML configuration of the CRP object.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: work-3
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
# Select all namespaces with the label app=work-3.
labelSelector:
matchLabels:
app: work-3
policy:
placementType: PickAll
strategy:
# For simplicity reasons, the CRP is configured to roll out changes to
# all member clusters at once. This is not a setup recommended for production
# use.
type: RollingUpdate
rollingUpdate:
maxUnavailable: 100%
unavailablePeriodSeconds: 1
EOF
In a few seconds, Fleet will complete the placement. Verify that the CRP is available by checking its status.
After the CRP becomes available, edit its apply strategy and set it to use the ReportDiff mode:
cat <<EOF | kubectl apply -f -
# The YAML configuration of the CRP object.
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: work-3
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
# Select all namespaces with the label app=work-3.
labelSelector:
matchLabels:
app: work-3
policy:
placementType: PickAll
strategy:
# For simplicity reasons, the CRP is configured to roll out changes to
# all member clusters at once. This is not a setup recommended for production
# use.
type: RollingUpdate
rollingUpdate:
maxUnavailable: 100%
unavailablePeriodSeconds: 1
applyStrategy:
type: ReportDiff
EOF
The CRP should remain available, as currently there is no configuration difference at all.
Check the ClusterResourcePlacementDiffReported condition in the status; it should report no error:
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work-3 -o jsonpath='{.status.conditions[?(@.type=="ClusterResourcePlacementDiffReported")]}' | jq
# The command above uses JSON paths to query the drift details directly and
# uses the jq utility to pretty print the output JSON.
#
# jq might not be available in your environment. You may have to install it
# separately, or omit it from the command.
#
# If the output is empty, the status might have not been populated properly
# yet. You can switch the output type from jsonpath to yaml to see the full
# object.
{
"lastTransitionTime": "2025-03-19T06:45:58Z",
"message": "Diff reporting in 2 cluster(s) has been completed",
"observedGeneration": ...,
"reason": "DiffReportingCompleted",
"status": "True",
"type": "ClusterResourcePlacementDiffReported"
}
Now, switch to the second member cluster and make a label change on the applied namespace.
After the change is done, switch back to the hub cluster.
kubectl config use-context member-2-admin
kubectl label ns work-3 owner=krauser --overwrite
#
kubectl config use-context hub-admin
Fleet will detect this configuration difference shortly (w/in 15 seconds).
Verify that the diff details have been added to the CRP status, specifically reported
in the diffedPlacements part of the status; the jq query below
will list all the clusters with the diffedPlacements status information populated:
kubectl get clusterresourceplacement.v1beta1.placement.kubernetes-fleet.io work-3 -o jsonpath='{.status.placementStatuses}' \
| jq '[.[] | select (.diffedPlacements != null)] | map({clusterName, diffedPlacements})'
# The command above uses JSON paths to retrieve the relevant status information
# directly and uses the jq utility to query the data.
#
# jq might not be available in your environment. You may have to install it
# separately, or omit it from the command.
The output should be as follows:
{
"clusterName": "member-2",
"diffedPlacements": [
{
"firstDiffedObservedTime": "2025-03-19T06:49:54Z",
"kind": "Namespace",
"name": "work-3",
"observationTime": "2025-03-19T06:50:25Z",
"observedDiffs": [
{
"path": "/metadata/labels/owner",
"valueInHub": "leon",
"valueInMember": "krauser"
}
],
"targetClusterObservedGeneration": 0,
"version": "v1"
}
]
}
Fleet will report the following information about a configuration difference:
group, kind, version, namespace, and name: the resource that has configuration differences.observationTime: the timestamp where the current diff detail is collected.firstDiffedObservedTime: the timestamp where the current diff is first observed.observedDiffs: the diff details, specifically:path: A JSON path (RFC 6901) that points to the diff’d field;valueInHub: the value at the JSON path as seen from the hub cluster resource template
(the desired state). If this value is absent, the field does not exist in the resource template.valueInMember: the value at the JSON path as seen from the member cluster resource
(the current state). If this value is absent, the field does not exist in the current state.
targetClusterObservedGeneration: the generation of the member cluster resource.
- As mentioned earlier, with this mode no apply op will be run at all; it is up to the user to
decide the best way to handle found configuration differences (if any).
- Diff reporting becomes successful and complete as soon as Fleet finishes checking all the resources;
whether configuration differences are found or not has no effect on the diff reporting success status.
- When a resource change has been applied on the hub cluster side, for CRPs of the ReportDiff mode,
the change will be immediately rolled out to all member clusters (when the rollout strategy is set to
RollingUpdate, the default type), as soon as they have completed diff reporting earlier.
- It is worth noting that Fleet will only report differences on resources that have corresponding manifests
on the hub cluster. If, for example, a namespace-scoped object has been created on the member cluster but
not on the hub cluster, Fleet will ignore the object, even if its owner namespace has been selected for placement.
3.14 - How to Roll Out and Roll Back Changes in Stage
How to roll out and roll back changes with staged update APIs
This how-to guide demonstrates how to use staged updates to rollout resources to member clusters in a staged manner and rollback resources to a previous version. We’ll cover both cluster-scoped and namespace-scoped approaches to serve different organizational needs.
Overview of Staged Update Approaches
Kubefleet provides two staged update approaches:
Cluster-Scoped: Use ClusterStagedUpdateRun with ClusterResourcePlacement (CRP) for fleet administrators managing infrastructure-level changes.
Namespace-Scoped: Use StagedUpdateRun with ResourcePlacement for application teams managing rollouts within their specific namespaces.
Prerequisite
This tutorial is based on a demo fleet environment with 3 member clusters:
| cluster name | labels |
|---|
| member1 | environment=canary, order=2 |
| member2 | environment=staging |
| member3 | environment=canary, order=1 |
We’ll demonstrate both cluster-scoped and namespace-scoped staged updates using different scenarios.
Cluster-Scoped Staged Updates
Setup for Cluster-Scoped Updates
To demonstrate cluster-scoped rollout and rollback behavior, we create a demo namespace and a sample configmap with very simple data on the hub cluster. The namespace with configmap will be deployed to the member clusters.
kubectl create ns test-namespace
kubectl create cm test-cm --from-literal=key=value1 -n test-namespace
Now we create a ClusterResourcePlacement to deploy the resources:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: example-placement
spec:
resourceSelectors:
- group: ""
kind: Namespace
name: test-namespace
version: v1
policy:
placementType: PickAll
strategy:
type: External
EOF
Note that spec.strategy.type is set to External to allow rollout triggered with a ClusterStagedUpdateRun.
All clusters should be scheduled since we use the PickAll policy but at the moment no resource should be deployed on the member clusters because we haven’t created a ClusterStagedUpdateRun yet. The CRP is not AVAILABLE yet.
kubectl get crp example-placement
NAME GEN SCHEDULED SCHEDULED-GEN AVAILABLE AVAILABLE-GEN AGE
example-placement 1 True 1 8s
Resource Snapshot Versions
Fleet uses resource snapshots for version control and audit (for more details, please refer to api-reference).
Important: Resource snapshots are not automatically created for placements with spec.strategy.type: External. When you create an UpdateRun without specifying resourceSnapshotIndex, the system uses the latest snapshot (creating one if it does not already exist) during UpdateRun initialization.
Since our placement uses External strategy, no resource snapshots exist yet:
kubectl get clusterresourcesnapshots -l kubernetes-fleet.io/parent-CRP=example-placement
No resources found
Snapshots will be created when we trigger staged update runs. Each UpdateRun that omits resourceSnapshotIndex uses the latest snapshot or creates one if it does not already exist, capturing the current state of the resources. This allows you to:
- Rollout current state: Omit
resourceSnapshotIndex to use the latest snapshot (creating one if needed) - Rollback to previous versions: Reference a previous snapshot index to rollback changes
Listing Available Snapshots
After running multiple UpdateRuns with the same Placement, you can list all available snapshots:
kubectl get clusterresourcesnapshots -l kubernetes-fleet.io/parent-CRP=example-placement --show-labels
NAME GEN AGE LABELS
example-placement-0-snapshot 1 30m kubernetes-fleet.io/is-latest-snapshot=false,kubernetes-fleet.io/parent-CRP=example-placement,kubernetes-fleet.io/resource-index=0
example-placement-1-snapshot 1 10m kubernetes-fleet.io/is-latest-snapshot=true,kubernetes-fleet.io/parent-CRP=example-placement,kubernetes-fleet.io/resource-index=1
Key labels to note:
kubernetes-fleet.io/resource-index: The snapshot index used when referencing in UpdateRunskubernetes-fleet.io/is-latest-snapshot: Indicates the most recent snapshotkubernetes-fleet.io/parent-CRP: The name of the parent ClusterResourcePlacement
Viewing Snapshot Contents
To see what resources are captured in a specific snapshot:
kubectl get clusterresourcesnapshots example-placement-0-snapshot -o yaml
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourceSnapshot
metadata:
labels:
kubernetes-fleet.io/is-latest-snapshot: "false"
kubernetes-fleet.io/parent-CRP: example-placement
kubernetes-fleet.io/resource-index: "0"
name: example-placement-0-snapshot
...
spec:
selectedResources:
- apiVersion: v1
kind: Namespace
metadata:
labels:
kubernetes.io/metadata.name: test-namespace
name: test-namespace
spec:
finalizers:
- kubernetes
- apiVersion: v1
data:
key: value1 # The value at this snapshot version
kind: ConfigMap
metadata:
name: test-cm
namespace: test-namespace
Referencing a Snapshot for Rollback
To rollback to a previous version, specify the resourceSnapshotIndex in your UpdateRun:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
name: rollback-run
spec:
placementName: example-placement
resourceSnapshotIndex: "0" # Reference example-placement-0-snapshot to rollback
stagedRolloutStrategyName: example-strategy
state: Run
Deploy a ClusterStagedUpdateStrategy
A ClusterStagedUpdateStrategy defines the orchestration pattern that groups clusters into stages and specifies the rollout sequence.
It selects member clusters by labels. For our demonstration, we create one with two stages:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateStrategy
metadata:
name: example-strategy
spec:
stages:
- name: staging
labelSelector:
matchLabels:
environment: staging
maxConcurrency: 30% # Update clusters sequentially in staging, 30% of 1 clusters is 0.3, we usually round down but if value is less than 1 we set maxConcurrency to 1
afterStageTasks:
- type: TimedWait
waitTime: 1m
- name: canary
labelSelector:
matchLabels:
environment: canary
sortingLabelKey: order
maxConcurrency: 2 # Update 2 canary clusters concurrently
beforeStageTasks:
- type: Approval # Require approval before starting canary
afterStageTasks:
- type: Approval # Require approval after canary completes
EOF
Deploy a ClusterStagedUpdateRun to rollout resources
A ClusterStagedUpdateRun executes the rollout of a ClusterResourcePlacement following a ClusterStagedUpdateStrategy. To trigger the staged update run for our CRP, we create a ClusterStagedUpdateRun specifying the CRP name and strategy name. Since no snapshots exist yet, we omit resourceSnapshotIndex so the system creates a new snapshot during initialization:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
name: example-run
spec:
placementName: example-placement
# resourceSnapshotIndex omitted - system uses the latest snapshot (creating one if it does not already exist)
stagedRolloutStrategyName: example-strategy
state: Initialize # Initialize but don't start execution yet
EOF
The UpdateRun starts in Initialize state, which computes the stages without executing. This allows you to review the computed stages before starting:
kubectl get csur example-run -o yaml # Review computed stages in status
Output:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
...
generation: 1
name: example-run
...
spec:
placementName: example-placement
# resourceSnapshotIndex is empty since we omitted it
stagedRolloutStrategyName: example-strategy
state: Initialize
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
deletionStageStatus:
clusters: []
stageName: kubernetes-fleet.io/deleteStage
policyObservedClusterCount: 3
policySnapshotIndexUsed: "0"
resourceSnapshotIndexUsed: "0" # System created snapshot-0 during initialization
stagedUpdateStrategySnapshot:
stages:
- afterStageTasks:
- type: TimedWait
waitTime: 1m0s
labelSelector:
matchLabels:
environment: staging
maxConcurrency: 30%
name: staging
- afterStageTasks:
- type: Approval
beforeStageTasks:
- type: Approval
labelSelector:
matchLabels:
environment: canary
maxConcurrency: 2
name: canary
sortingLabelKey: order
stagesStatus:
- afterStageTaskStatus:
- type: TimedWait
clusters:
- clusterName: kind-cluster-2
stageName: staging
- afterStageTaskStatus:
- approvalRequestName: example-run-after-canary
type: Approval
beforeStageTaskStatus:
- approvalRequestName: example-run-before-canary
type: Approval
clusters:
- clusterName: kind-cluster-3
- clusterName: kind-cluster-1
stageName: canary
Once satisfied with the plan, start the rollout by changing the state to Run:
kubectl patch csur example-run --type='merge' -p '{"spec":{"state":"Run"}}'
The staged update run is initialized and running:
kubectl get csur example-run
NAME PLACEMENT RESOURCE-SNAPSHOT-INDEX POLICY-SNAPSHOT-INDEX INITIALIZED PROGRESSING SUCCEEDED AGE
example-run example-placement 0 0 True True 62s
A more detailed look at the status:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
...
name: example-run
generation: 2 # state changed from Initialize -> Run
...
spec:
placementName: example-placement
# resourceSnapshotIndex is empty since we omitted it
stagedRolloutStrategyName: example-strategy
state: Run
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 2
reason: UpdateRunInitializedSuccessfully
status: "True" # the updateRun is initialized successfully
type: Initialized
- lastTransitionTime: ...
message: ...
observedGeneration: 2
reason: UpdateRunWaiting
status: "False" # the updateRun is waiting
type: Progressing
deletionStageStatus:
clusters: [] # no clusters need to be cleaned up
stageName: kubernetes-fleet.io/deleteStage
policyObservedClusterCount: 3 # number of clusters to be updated
policySnapshotIndexUsed: "0"
resourceSnapshotIndexUsed: "0" # System created snapshot-0 during initialization
stagedUpdateStrategySnapshot: # snapshot of the strategy
stages:
- afterStageTasks:
- type: TimedWait
waitTime: 1m0s
labelSelector:
matchLabels:
environment: staging
maxConcurrency: 1
name: staging
- afterStageTasks:
- type: Approval
beforeStageTasks:
- type: Approval
labelSelector:
matchLabels:
environment: canary
maxConcurrency: 2
name: canary
sortingLabelKey: order
stagesStatus: # detailed status for each stage
- afterStageTaskStatus:
- conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 2
reason: AfterStageTaskWaitTimeElapsed
status: "True" # the wait after-stage task has completed
type: WaitTimeElapsed
type: TimedWait
clusters:
- clusterName: member2 # stage staging contains member2 cluster only
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 2
reason: ClusterUpdatingStarted
status: "True"
type: Started
- lastTransitionTime: ...
message: ...
observedGeneration: 2
reason: ClusterUpdatingSucceeded
status: "True" # member2 is updated successfully
type: Succeeded
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 2
reason: StageUpdatingSucceeded
status: "False"
type: Progressing
- lastTransitionTime: ...
message: ...
observedGeneration: 2
reason: StageUpdatingSucceeded
status: "True" # stage staging has completed successfully
type: Succeeded
endTime: ...
stageName: staging
startTime: ...
- afterStageTaskStatus:
- approvalRequestName: example-run-after-canary
type: Approval
beforeStageTaskStatus:
- approvalRequestName: example-run-before-canary
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 2
reason: StageTaskApprovalRequestCreated
status: "True" # before stage cluster approval task has been created
type: ApprovalRequestCreated
type: Approval
clusters:
- clusterName: member3
- clusterName: member1
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 2
reason: StageUpdatingWaiting
status: "False"
type: Progressing
stageName: canary
After stage staging completes, the canary stage requires approval before it starts (due to beforeStageTasks). Check for the before-stage approval request:
kubectl get clusterapprovalrequest -A
NAME UPDATE-RUN STAGE APPROVED AGE
example-run-before-canary example-run canary 6m55s
Approve the before-stage task to allow canary stage to start:
kubectl patch clusterapprovalrequests example-run-before-canary --type='merge' \
-p '{"status":{"conditions":[{"type":"Approved","status":"True","reason":"approved","message":"approved","lastTransitionTime":"'$(date -u +"%Y-%m-%dT%H:%M:%SZ")'","observedGeneration":1}]}}' \
--subresource=status
Once approved, the canary stage begins updating clusters. With maxConcurrency: 2, it updates up to 2 clusters concurrently.
Wait for the canary stage to finish cluster updates. It will then wait for the after-stage Approval task:
kubectl get clusterapprovalrequest -A
NAME UPDATE-RUN STAGE APPROVED AGE
example-run-after-canary example-run canary 3s
example-run-before-canary example-run canary True 15m
Note: Observed generation in the Approved condition should match the generation of the approvalRequest object.
Approve the after-stage task to complete the rollout:
kubectl patch clusterapprovalrequests example-run-after-canary --type='merge' \
-p '{"status":{"conditions":[{"type":"Approved","status":"True","reason":"approved","message":"approved","lastTransitionTime":"'$(date -u +"%Y-%m-%dT%H:%M:%SZ")'","observedGeneration":1}]}}' \
--subresource=status
Alternatively, you can approve using a json patch file:
cat << EOF > approval.json
"status": {
"conditions": [
{
"lastTransitionTime": "$(date -u +%Y-%m-%dT%H:%M:%SZ)",
"message": "approved",
"observedGeneration": 1,
"reason": "approved",
"status": "True",
"type": "Approved"
}
]
}
EOF
kubectl patch clusterapprovalrequests example-run-after-canary --type='merge' --subresource=status --patch-file approval.json
Verify both approvals are accepted:
kubectl get clusterapprovalrequest -A
NAME UPDATE-RUN STAGE APPROVED AGE
example-run-after-canary example-run canary True 2m12s
example-run-before-canary example-run canary True 17m
The updateRun now is able to proceed and complete:
kubectl get csur example-run
NAME PLACEMENT RESOURCE-SNAPSHOT-INDEX POLICY-SNAPSHOT-INDEX INITIALIZED PROGRESSING SUCCEEDED AGE
example-run example-placement 0 0 True False True 20m
The CRP also shows rollout has completed and resources are available on all member clusters:
kubectl get crp example-placement
NAME GEN SCHEDULED SCHEDULED-GEN AVAILABLE AVAILABLE-GEN AGE
example-placement 1 True 1 True 1 36m
The configmap test-cm should be deployed on all 3 member clusters:
You can verify the snapshot was created:
kubectl get clusterresourcesnapshots -l kubernetes-fleet.io/parent-CRP=example-placement
NAME GEN AGE
example-placement-0-snapshot 1 5m
Rolling Out a New Version
Now let’s update the configmap and roll out the change. First, modify the configmap:
kubectl patch configmap test-cm -n test-namespace -p '{"data":{"key":"value2"}}'
Create another UpdateRun to deploy the updated resources. Again, omit resourceSnapshotIndex so the system creates a new snapshot capturing the current state:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
name: example-run-latest
spec:
placementName: example-placement
# resourceSnapshotIndex omitted - creates new snapshot with updated resources
stagedRolloutStrategyName: example-strategy
state: Run # Start immediately
EOF
The system will create the latest snapshot at initialization time. Check which snapshot was used:
kubectl get csur example-run-latest -o jsonpath='{.status.resourceSnapshotIndexUsed}'
Now we have two snapshots available for version control:
kubectl get clusterresourcesnapshots -l kubernetes-fleet.io/parent-CRP=example-placement --show-labels
NAME GEN AGE LABELS
example-placement-0-snapshot 1 25m kubernetes-fleet.io/is-latest-snapshot=false,kubernetes-fleet.io/parent-CRP=example-placement,kubernetes-fleet.io/resource-index=0
example-placement-1-snapshot 1 5m kubernetes-fleet.io/is-latest-snapshot=true,kubernetes-fleet.io/parent-CRP=example-placement,kubernetes-fleet.io/resource-index=1
Pausing and Resuming a Rollout
You can pause an in-progress rollout to investigate issues or wait for off-peak hours:
# Pause the rollout
kubectl patch csur example-run-latest --type='merge' -p '{"spec":{"state":"Stop"}}'
Verify the rollout is stopped:
kubectl get csur example-run-latest
NAME PLACEMENT RESOURCE-SNAPSHOT POLICY-SNAPSHOT INITIALIZED PROGRESSING SUCCEEDED AGE
example-run-latest example-placement 1 0 True False 8m
The rollout pauses at its current position (current cluster/stage). Resume when ready:
# Resume the rollout
kubectl patch csur example-run-latest --type='merge' -p '{"spec":{"state":"Run"}}'
The rollout continues from where it was paused.
Rollback to a Previous Version
Now suppose the workload admin wants to rollback the configmap change, reverting the value value2 back to value1.
Instead of manually updating the configmap on the hub, they can create a new ClusterStagedUpdateRun with a previous resource snapshot index. Since we now have “example-placement-0-snapshot” (value1) and “example-placement-1-snapshot” (value2), we specify resourceSnapshotIndex: "0" to rollback:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
name: example-run-rollback
spec:
placementName: example-placement
resourceSnapshotIndex: "0" # Rollback to example-placement-0-snapshot (value1)
stagedRolloutStrategyName: example-strategy
state: Run # Start rollback immediately
EOF
Following the same approval steps as deploying the first updateRun, the rollback updateRun should succeed. Complete status shown below:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
...
name: example-run-2
generation: 1
...
spec:
placementName: example-placement
resourceSnapshotIndex: "0"
stagedRolloutStrategyName: example-strategy
state: Run
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: UpdateRunSucceeded
status: "False"
type: Progressing
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: UpdateRunSucceeded # updateRun succeeded
status: "True"
type: Succeeded
deletionStageStatus:
clusters: []
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageUpdatingSucceeded
status: "False"
type: Progressing
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageUpdatingSucceeded
status: "True" # no clusters in the deletion stage, it completes directly
type: Succeeded
endTime: ...
stageName: kubernetes-fleet.io/deleteStage
startTime: ...
policyObservedClusterCount: 3
policySnapshotIndexUsed: "0"
resourceSnapshotIndexUsed: "0"
stagedUpdateStrategySnapshot:
stages:
- afterStageTasks:
- type: TimedWait
waitTime: 1m0s
labelSelector:
matchLabels:
environment: staging
maxConcurrency: 1
name: staging
- afterStageTasks:
- type: Approval
beforeStageTasks:
- type: Approval
labelSelector:
matchLabels:
environment: canary
maxConcurrency: 2
name: canary
sortingLabelKey: order
stagesStatus:
- afterStageTaskStatus:
- conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: AfterStageTaskWaitTimeElapsed
status: "True"
type: WaitTimeElapsed
type: TimedWait
clusters:
- clusterName: member2
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: ClusterUpdatingStarted
status: "True"
type: Started
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: ClusterUpdatingSucceeded
status: "True"
type: Succeeded
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageUpdatingSucceeded
status: "False"
type: Progressing
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageUpdatingSucceeded
status: "True"
type: Succeeded
endTime: ...
stageName: staging
startTime: ...
- afterStageTaskStatus:
- approvalRequestName: example-run-2-after-canary
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageTaskApprovalRequestCreated
status: "True"
type: ApprovalRequestCreated
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageTaskApprovalRequestApproved
status: "True"
type: ApprovalRequestApproved
type: Approval
beforeStageTaskStatus:
- approvalRequestName: example-run-2-before-canary
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageTaskApprovalRequestCreated
status: "True"
type: ApprovalRequestCreated
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageTaskApprovalRequestApproved
status: "True"
type: ApprovalRequestApproved
type: Approval
clusters:
- clusterName: member3
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: ClusterUpdatingStarted
status: "True"
type: Started
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: ClusterUpdatingSucceeded
status: "True"
type: Succeeded
- clusterName: member1
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: ClusterUpdatingStarted
status: "True"
type: Started
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: ClusterUpdatingSucceeded
status: "True"
type: Succeeded
conditions:
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageUpdatingSucceeded
status: "False"
type: Progressing
- lastTransitionTime: ...
message: ...
observedGeneration: 1
reason: StageUpdatingSucceeded
status: "True"
type: Succeeded
endTime: ...
stageName: canary
startTime: ...
The configmap test-cm should be updated on all 3 member clusters, with old data:
Namespace-Scoped Staged Updates
Namespace-scoped staged updates allow application teams to manage rollouts independently within their namespaces using StagedUpdateRun and StagedUpdateStrategy resources.
Setup for Namespace-Scoped Updates
Let’s demonstrate namespace-scoped staged updates by deploying an application within a specific namespace.
Create a namespace,
kubectl create ns my-app-namespace
Create a CRP that only propagates the namespace (i.e. with selectionScope set to NamespaceOnly, the namespace resource is propagated without any resources within the namespace) to all the clusters.
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: ns-only-crp
spec:
resourceSelectors:
- group: ""
kind: Namespace
name: my-app-namespace
version: v1
selectionScope: NamespaceOnly
policy:
placementType: PickAll
strategy:
type: RollingUpdate
EOF
Create application to rollout,
kubectl create deployment web-app --image=nginx:1.20 --port=80 -n my-app-namespace
kubectl expose deployment web-app --port=80 --target-port=80 -n my-app-namespace
Create a namespace-scoped ResourcePlacement to deploy the application:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ResourcePlacement
metadata:
name: web-app-placement
namespace: my-app-namespace
spec:
resourceSelectors:
- group: "apps"
kind: Deployment
name: web-app
version: v1
- group: ""
kind: Service
name: web-app
version: v1
policy:
placementType: PickAll
strategy:
type: External # enables namespace-scoped staged updates
EOF
Resource Snapshot Versions (Namespace-Scoped)
Similar to cluster-scoped placements, resource snapshots are not automatically created for namespace-scoped placements with spec.strategy.type: External. The latest snapshot is used (and created if it does not already exist) when you create an UpdateRun without specifying resourceSnapshotIndex.
Since our ResourcePlacement uses External strategy, no resource snapshots exist yet:
kubectl get resourcesnapshots -n my-app-namespace -l kubernetes-fleet.io/parent-CRP=web-app-placement
No resources found
Listing Available Snapshots (Namespace-Scoped)
After running multiple UpdateRuns with the same ResourcePlacement, you can list all available snapshots:
kubectl get resourcesnapshots -n my-app-namespace -l kubernetes-fleet.io/parent-CRP=web-app-placement --show-labels
NAME GEN AGE LABELS
web-app-placement-0-snapshot 1 30m kubernetes-fleet.io/is-latest-snapshot=false,kubernetes-fleet.io/parent-CRP=web-app-placement,kubernetes-fleet.io/resource-index=0
web-app-placement-1-snapshot 1 10m kubernetes-fleet.io/is-latest-snapshot=true,kubernetes-fleet.io/parent-CRP=web-app-placement,kubernetes-fleet.io/resource-index=1
Key labels to note:
kubernetes-fleet.io/resource-index: The snapshot index used when referencing in UpdateRunskubernetes-fleet.io/is-latest-snapshot: Indicates the most recent snapshotkubernetes-fleet.io/parent-CRP: The name of the parent ResourcePlacement
Viewing Snapshot Contents (Namespace-Scoped)
To see what resources are captured in a specific snapshot:
kubectl get resourcesnapshots web-app-placement-0-snapshot -n my-app-namespace -o yaml
apiVersion: placement.kubernetes-fleet.io/v1
kind: ResourceSnapshot
metadata:
labels:
kubernetes-fleet.io/is-latest-snapshot: "false"
kubernetes-fleet.io/parent-CRP: web-app-placement
kubernetes-fleet.io/resource-index: "0"
name: web-app-placement-0-snapshot
namespace: my-app-namespace
...
spec:
selectedResources:
- apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app
namespace: my-app-namespace
spec:
template:
spec:
containers:
- image: nginx:1.20 # The image at this snapshot version
name: nginx
...
- apiVersion: v1
kind: Service
metadata:
name: web-app
namespace: my-app-namespace
...
Referencing a Snapshot for Rollback (Namespace-Scoped)
To rollback to a previous version, specify the resourceSnapshotIndex in your StagedUpdateRun:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: StagedUpdateRun
metadata:
name: rollback-run
namespace: my-app-namespace
spec:
placementName: web-app-placement
resourceSnapshotIndex: "0" # Reference web-app-placement-0-snapshot to rollback
stagedRolloutStrategyName: app-rollout-strategy
state: Run
Deploy a StagedUpdateStrategy
Create a namespace-scoped staged update strategy:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: StagedUpdateStrategy
metadata:
name: app-rollout-strategy
namespace: my-app-namespace
spec:
stages:
- name: dev
labelSelector:
matchLabels:
environment: staging
maxConcurrency: 2 # Update 2 dev clusters concurrently
afterStageTasks:
- type: TimedWait
waitTime: 30s
- name: prod
labelSelector:
matchLabels:
environment: canary
sortingLabelKey: order
maxConcurrency: 1 # Sequential production updates
beforeStageTasks:
- type: Approval # Require approval before production
afterStageTasks:
- type: Approval # Require approval after production
EOF
Deploy a StagedUpdateRun to Rollout Resources
Create a namespace-scoped staged update run to deploy the application. Since no snapshots exist yet, we omit resourceSnapshotIndex so the system creates a new snapshot during initialization:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: StagedUpdateRun
metadata:
name: web-app-rollout-v1-20
namespace: my-app-namespace
spec:
placementName: web-app-placement
# resourceSnapshotIndex omitted - system creates snapshot during initialization
stagedRolloutStrategyName: app-rollout-strategy
state: Run # Start rollout immediately
EOF
Monitor namespace-scoped staged rollout
Check the status of the staged update run:
kubectl get sur web-app-rollout-v1-20 -n my-app-namespace
Wait for the first stage to complete. The prod before stage requires approval before starting:
kubectl get approvalrequests -n my-app-namespace
NAME UPDATE-RUN STAGE APPROVED AGE
web-app-rollout-v1-20-before-prod web-app-rollout-v1-20 prod 2s
Approve the before-stage task to start production rollout:
kubectl patch approvalrequests web-app-rollout-v1-20-before-prod -n my-app-namespace --type='merge' \
-p '{"status":{"conditions":[{"type":"Approved","status":"True","reason":"approved","message":"approved","lastTransitionTime":"'$(date -u +"%Y-%m-%dT%H:%M:%SZ")'","observedGeneration":1}]}}' \
--subresource=status
After production clusters complete updates, approve the after-stage task:
kubectl get approvalrequests -n my-app-namespace
NAME UPDATE-RUN STAGE APPROVED AGE
web-app-rollout-v1-20-after-prod web-app-rollout-v1-20 prod 18s
web-app-rollout-v1-20-before-prod web-app-rollout-v1-20 prod True 2m22s
kubectl patch approvalrequests web-app-rollout-v1-20-after-prod -n my-app-namespace --type='merge' \
-p '{"status":{"conditions":[{"type":"Approved","status":"True","reason":"approved","message":"approved","lastTransitionTime":"'$(date -u +"%Y-%m-%dT%H:%M:%SZ")'","observedGeneration":1}]}}' \
--subresource=status
Verify the rollout completion:
kubectl get sur web-app-rollout-v1-20 -n my-app-namespace
kubectl get resourceplacement web-app-placement -n my-app-namespace
Rolling Out a New Version (Namespace-Scoped)
Now let’s update the deployment to a new version and roll out the change:
kubectl set image deployment/web-app nginx=nginx:1.21 -n my-app-namespace
Create another UpdateRun to deploy the updated resources. Omit resourceSnapshotIndex so the system creates a new snapshot (web-app-placement-1-snapshot) capturing the nginx:1.21 image:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: StagedUpdateRun
metadata:
name: web-app-rollout-v1-21
namespace: my-app-namespace
spec:
placementName: web-app-placement
# resourceSnapshotIndex omitted - creates new snapshot with updated deployment
stagedRolloutStrategyName: app-rollout-strategy
state: Run
EOF
After completing the approval steps, verify the new snapshot was used:
kubectl get sur web-app-rollout-v1-21 -n my-app-namespace -o jsonpath='{.status.resourceSnapshotIndexUsed}'
Now we have two snapshots available for version control:
kubectl get resourcesnapshots -n my-app-namespace -l kubernetes-fleet.io/parent-CRP=web-app-placement --show-labels
NAME GEN AGE LABELS
web-app-placement-0-snapshot 1 30m kubernetes-fleet.io/is-latest-snapshot=false,kubernetes-fleet.io/parent-CRP=web-app-placement,kubernetes-fleet.io/resource-index=0
web-app-placement-1-snapshot 1 10m kubernetes-fleet.io/is-latest-snapshot=true,kubernetes-fleet.io/parent-CRP=web-app-placement,kubernetes-fleet.io/resource-index=1
Rollback with Namespace-Scoped Staged Updates
To rollback to the previous version (nginx:1.20), create another staged update run referencing web-app-placement-0-snapshot:
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: StagedUpdateRun
metadata:
name: web-app-rollback-v1-20
namespace: my-app-namespace
spec:
placementName: web-app-placement
resourceSnapshotIndex: "0" # Rollback to web-app-placement-0-snapshot (nginx:1.20)
stagedRolloutStrategyName: app-rollout-strategy
state: Run # Start rollback immediately
EOF
Follow the same monitoring and approval process as above to complete the rollback.
Best Practices and Tips
MaxConcurrency Guidelines
- Development/Staging: Use higher values (e.g.,
maxConcurrency: 3 or 50%) to speed up rollouts - Production: Use
maxConcurrency: 1 for sequential updates to minimize risk and allow early detection of issues - Large fleets: Use percentages (e.g.,
10%, 25%) to scale with cluster growth automatically - Small fleets: Use absolute numbers for predictable behavior
State Management
- Initialize state: Use to review computed stages before execution. Useful for validating strategy configuration
- Run state: Start execution or resume from stopped state
- Stop state: Pause rollout to investigate issues, wait for maintenance windows, or coordinate with other activities
Approval Strategies
- Before-stage approvals: Use when stage selection requires validation (e.g., ensure all production prerequisites are met)
- After-stage approvals: Use to validate rollout success before proceeding (e.g., check metrics, run tests)
- Both: Combine for critical stages requiring validation at both entry and exit points
Key Differences Summary
| Aspect | Cluster-Scoped | Namespace-Scoped |
|---|
| Strategy Resource | ClusterStagedUpdateStrategy | StagedUpdateStrategy |
| UpdateRun Resource | ClusterStagedUpdateRun | StagedUpdateRun |
| Target Placement | ClusterResourcePlacement | ResourcePlacement |
| Approval Resource | ClusterApprovalRequest (short name: careq) | ApprovalRequest (short name: areq) |
| Scope | Cluster-wide | Namespace-bound |
| Use Case | Infrastructure rollouts | Application rollouts |
| Permissions | Cluster-admin level | Namespace-level |
3.15 - Evicting Resources and Setting up Disruption Budgets
How to evict resources from a cluster and set up disruption budgets to protect against untimely evictions
This how-to guide discusses how to create ClusterResourcePlacementEviction objects and ClusterResourcePlacementDisruptionBudget objects to evict resources from member clusters and protect resources on member clusters from voluntary disruption, respectively.
Evicting Resources from Member Clusters using ClusterResourcePlacementEviction
The ClusterResourcePlacementEviction object is used to remove resources from a member cluster once the resources have already been propagated from the hub cluster.
To successfully evict resources from a cluster, the user needs to specify:
- The name of the
ClusterResourcePlacement object which propagated resources to the target cluster. - The name of the target cluster from which we need to evict resources.
In this example, we will create a ClusterResourcePlacement object with PickAll placement policy to propagate resources to an existing MemberCluster, add a taint to the member cluster
resource and then create a ClusterResourcePlacementEviction object to evict resources from the MemberCluster.
We will first create a namespace that we will propagate to the member cluster.
kubectl create ns test-ns
Then we will apply a ClusterResourcePlacement with the following spec:
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: test-ns
policy:
placementType: PickN
numberOfClusters: 1
The CRP status after applying should look something like this:
kubectl get crp test-crp
NAME GEN SCHEDULED SCHEDULED-GEN AVAILABLE AVAILABLE-GEN AGE
test-crp 2 True 2 True 2 5m49s
let’s now add a taint to the member cluster to ensure this cluster is not picked again by the scheduler once we evict resources from it.
Modify the cluster object to add a taint:
spec:
heartbeatPeriodSeconds: 60
identity:
kind: ServiceAccount
name: fleet-member-agent-cluster-1
namespace: fleet-system
taints:
- effect: NoSchedule
key: test-key
value: test-value
Now we will create a ClusterResourcePlacementEviction object to evict resources from the member cluster:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacementEviction
metadata:
name: test-eviction
spec:
placementName: test-crp
clusterName: kind-cluster-1
the eviction object should look like this, if the eviction was successful:
kubectl get crpe test-eviction
NAME VALID EXECUTED
test-eviction True True
since the eviction is successful, the resources should be removed from the cluster, let’s take a look at the CRP object status to verify:
kubectl get crp test-crp
NAME GEN SCHEDULED SCHEDULED-GEN AVAILABLE AVAILABLE-GEN AGE
test-crp 2 True 2 15m
from the object we can clearly tell that the resources were evicted since the AVAILABLE column is empty. If the user needs more information ClusterResourcePlacement object’s status can be checked.
Protecting resources from voluntary disruptions using ClusterResourcePlacementDisruptionBudget
In this example, we will create a ClusterResourcePlacement object with PickN placement policy to propagate resources to an existing MemberCluster,
then create a ClusterResourcePlacementDisruptionBudget object to protect resources on the MemberCluster from voluntary disruption and
then try to evict resources from the MemberCluster using ClusterResourcePlacementEviction.
We will first create a namespace that we will propagate to the member cluster.
kubectl create ns test-ns
Then we will apply a ClusterResourcePlacement with the following spec:
spec:
resourceSelectors:
- group: ""
kind: Namespace
version: v1
name: test-ns
policy:
placementType: PickN
numberOfClusters: 1
The CRP object after applying should look something like this:
kubectl get crp test-crp
NAME GEN SCHEDULED SCHEDULED-GEN AVAILABLE AVAILABLE-GEN AGE
test-crp 2 True 2 True 2 8s
Now we will create a ClusterResourcePlacementDisruptionBudget object to protect resources on the member cluster from voluntary disruption:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacementDisruptionBudget
metadata:
name: test-crp
spec:
minAvailable: 1
Note: An eviction object is only reconciled once, after which it reaches a terminal state, if the user desires to create/apply the same eviction object again they need to delete the existing eviction object and re-create the object for the eviction to occur again.
Now we will create a ClusterResourcePlacementEviction object to evict resources from the member cluster:
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacementEviction
metadata:
name: test-eviction
spec:
placementName: test-crp
clusterName: kind-cluster-1
Note: The eviction controller will try to get the corresponding ClusterResourcePlacementDisruptionBudget object when a ClusterResourcePlacementEviction object is reconciled to check if the specified MaxAvailable or MinAvailable allows the eviction to be executed.
let’s take a look at the eviction object to see if the eviction was executed,
kubectl get crpe test-eviction
NAME VALID EXECUTED
test-eviction True False
from the eviction object we can see the eviction was not executed.
let’s take a look at the ClusterResourcePlacementEviction object status to verify why the eviction was not executed:
status:
conditions:
- lastTransitionTime: "2025-01-21T15:52:29Z"
message: Eviction is valid
observedGeneration: 1
reason: ClusterResourcePlacementEvictionValid
status: "True"
type: Valid
- lastTransitionTime: "2025-01-21T15:52:29Z"
message: 'Eviction is blocked by specified ClusterResourcePlacementDisruptionBudget,
availablePlacements: 1, totalPlacements: 1'
observedGeneration: 1
reason: ClusterResourcePlacementEvictionNotExecuted
status: "False"
type: Executed
the eviction status clearly mentions that the eviction was blocked by the specified ClusterResourcePlacementDisruptionBudget.
3.16 - Scheduling AI Jobs with Kueue and Fleet
Learn how to schedule AI/ML workloads using Kueue and ClusterResourcePlacement/ResourcePlacement
Scheduling AI Jobs with Kueue and Placement
This guide demonstrates how to schedule AI/ML workloads across your fleet using KubeFleet’s ClusterResourcePlacement/ResourcePlacement in conjunction with Kueue for efficient job queuing and resource management.
Overview
When scheduling AI/ML jobs across multiple clusters, you need three key components working together:
- ClusterResourcePlacement: Propagates cluster-scoped resources (ClusterQueues, ResourceFlavors) and namespaces to selected clusters
- ResourcePlacement: Propagates the AI/ML job and LocalQueue to selected clusters within the namespace
- Kueue: Manages job queuing and resource quotas within each cluster
This combination ensures efficient scheduling and resource utilization for your AI workloads across your entire fleet.
Enable Kueue on Fleet
To enable Kueue in your fleet environment, you’ll need to install Kueue on your Member Clusters and the required CustomResourceDefinitions (CRDs) on your Hub Cluster.
Install Kueue on Individual Member Clusters
Before proceeding with the installation, keep in mind that you’ll need to switch to the context of the member cluster you want to install Kueue on. This is because Kueue needs to be installed and managed individually within each cluster, and you need to ensure that you’re interacting with the correct cluster when applying the necessary configurations.
# Set the Kueue version you want to install
VERSION=v0.14.4 # Replace with the latest version, or working version you like
# Switch to your member cluster context
kubectl config use-context <member-cluster-context>
# Install Kueue on the member cluster
kubectl apply --server-side -f \
https://github.com/kubernetes-sigs/kueue/releases/download/$VERSION/manifests.yaml
Note: Replace VERSION with the latest version of Kueue. For more information about Kueue versions, see Kueue releases.
To ensure Kueue is properly installed:
# On member clusters - check Kueue controller is running
kubectl get pods -n kueue-system
NAME READY STATUS RESTARTS AGE
kueue-controller-manager-59f5c6b49c-22g7r 2/2 Running 0 57s
Repeat this process for each member cluster in your fleet where you want to schedule AI/ML workloads.
Install CRDs on Hub Cluster
Next, you will need to install the necessary CRDs on the hub cluster. Installing the CRDs here allows the hub cluster to properly handle Kueue-related resources. For this guide, we will install the CRDs for ResourceFlavor, ClusterQueue, and LocalQueue.
Important: Make sure you have switched to the context of your hub cluster before proceeding with the installation.
# Switch to your hub cluster context
kubectl config use-context <hub-cluster-context>
# Set the Kueue version you want to install
VERSION=v0.9.0 # Replace with the latest version, or working version you like
# Install required Kueue CRDs on hub cluster
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/kueue/$VERSION/config/components/crd/bases/kueue.x-k8s.io_clusterqueues.yaml
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/kueue/$VERSION/config/components/crd/bases/kueue.x-k8s.io_localqueues.yaml
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/kueue/$VERSION/config/components/crd/bases/kueue.x-k8s.io_resourceflavors.yaml
# Verify CRDs are installed
kubectl get crds | grep kueue
You should see output similar to:
clusterqueues.kueue.x-k8s.io 2025-10-17T17:50:30Z
localqueues.kueue.x-k8s.io 2025-10-17T17:50:33Z
resourceflavors.kueue.x-k8s.io 2025-10-17T17:50:35Z
Step-by-Step Guide
1. Create Resource Flavor on Hub
First, create a ResourceFlavor that defines the available resource types:
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: default-flavor
spec:
# This ResourceFlavor will be used for all the resources
A ResourceFlavor is an object that represents the variations in the nodes available in your cluster by associating them with node labels and taints.
Set up a ClusterQueue for the workloads:
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: cluster-queue
spec:
cohort: compute-workload
namespaceSelector: {} # Available to all namespaces
queueingStrategy: BestEffortFIFO # Default queueing strategy
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: default-flavor
resources:
- name: cpu
nominalQuota: "32"
- name: memory
nominalQuota: "128Gi"
NOTE: The resources need to be listed in the same order as the coveredResources list.
A ClusterQueue is a cluster-scoped object that oversees a pool of resources, including CPU, memory, and GPU. It manages ResourceFlavors, sets usage limits, and controls the order in which workloads are admitted. This will handle the ResourceFlavor that was previously created.
3. Create AI job Namespace on Hub
Create the namespace where your AI jobs will be scheduled:
apiVersion: v1
kind: Namespace
metadata:
name: compute-jobs
labels:
app: compute-workload
The LocalQueue and Job require a namespace to be specified.
4. Use ClusterResourcePlacement to Propagate Cluster-Scoped Resources
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: sample-kueue
spec:
resourceSelectors:
- group: kueue.x-k8s.io
version: v1beta1
kind: ResourceFlavor
name: default-flavor
- group: kueue.x-k8s.io
version: v1beta1
kind: ClusterQueue
name: cluster-queue
- group: ""
kind: Namespace
version: v1
name: compute-jobs
selectionScope: NamespaceOnly
policy:
placementType: PickAll
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
unavailablePeriodSeconds: 60
revisionHistoryLimit: 15
The ClusterResourcePlacement (CRP) will select the cluster-scoped resources you created (such as ResourceFlavor and ClusterQueue) and the namespace only. The CRP will propagate these resources to all selected member clusters on the Fleet.
Verify ClusterResourcePlacement Completed
After creating the ClusterResourcePlacement, you need to verify that it has successfully propagated the resources to the target clusters. A successful completion is indicated by several conditions in the status:
- Check the placement status:
# Get detailed status of the ClusterResourcePlacement
kubectl describe crp sample-kueue
Name: sample-kueue
Namespace:
Labels: <none>
Annotations: <none>
API Version: placement.kubernetes-fleet.io/v1
Kind: ClusterResourcePlacement
Metadata:
Creation Timestamp: 2025-10-22T20:19:50Z
Finalizers:
kubernetes-fleet.io/crp-cleanup
kubernetes-fleet.io/scheduler-cleanup
Generation: 1
Resource Version: 3794694
UID: e242900c-3552-4289-bf8f-8be2480e63b1
Spec:
..
Status:
Conditions:
Last Transition Time: 2025-10-22T20:19:50Z
Message: found all cluster needed as specified by the scheduling policy, found 3 cluster(s)
Observed Generation: 1
Reason: SchedulingPolicyFulfilled
Status: True
Type: ClusterResourcePlacementScheduled
Last Transition Time: 2025-10-22T20:19:50Z
Message: All 3 cluster(s) start rolling out the latest resource
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: ClusterResourcePlacementRolloutStarted
Last Transition Time: 2025-10-22T20:19:50Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: ClusterResourcePlacementOverridden
Last Transition Time: 2025-10-22T20:19:50Z
Message: Works(s) are succcesfully created or updated in 3 target cluster(s)' namespaces
Observed Generation: 1
Reason: WorkSynchronized
Status: True
Type: ClusterResourcePlacementWorkSynchronized
Last Transition Time: 2025-10-22T20:19:50Z
Message: The selected resources are successfully applied to 3 cluster(s)
Observed Generation: 1
Reason: ApplySucceeded
Status: True
Type: ClusterResourcePlacementApplied
Last Transition Time: 2025-10-22T20:19:50Z
Message: The selected resources in 3 cluster(s) are available now
Observed Generation: 1
Reason: ResourceAvailable
Status: True
Type: ClusterResourcePlacementAvailable
Observed Resource Index: 0
Placement Statuses:
Cluster Name: cluster-1
Conditions:
Last Transition Time: 2025-10-22T20:19:50Z
Message: Successfully scheduled resources for placement in "cluster-1" (affinity score: 0, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2025-10-22T20:19:50Z
Message: Detected the new changes on the resources and started the rollout process
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: RolloutStarted
Last Transition Time: 2025-10-22T20:19:50Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: Overridden
Last Transition Time: 2025-10-22T20:19:50Z
Message: All of the works are synchronized to the latest
Observed Generation: 1
Reason: AllWorkSynced
Status: True
Type: WorkSynchronized
Last Transition Time: 2025-10-22T20:19:50Z
Message: All corresponding work objects are applied
Observed Generation: 1
Reason: AllWorkHaveBeenApplied
Status: True
Type: Applied
Last Transition Time: 2025-10-22T20:19:50Z
Message: The availability of work object sample-kueue-work is not trackable
Observed Generation: 1
Reason: NotAllWorkAreAvailabilityTrackable
Status: True
Type: Available
ClusterName: cluster-2
...
ClusterName: cluster-3
...
Selected Resources:
Kind: Namespace
Name: compute-jobs
Version: v1
Group: kueue.x-k8s.io
Kind: ClusterQueue
Name: cluster-queue
Version: v1beta1
Group: kueue.x-k8s.io
Kind: ResourceFlavor
Name: default-flavor
Version: v1beta1
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal PlacementRolloutStarted 13s placement-controller Started rolling out the latest resources
Normal PlacementOverriddenSucceeded 13s placement-controller Placement has been successfully overridden
Normal PlacementWorkSynchronized 13s placement-controller Work(s) have been created or updated successfully for the selected cluster(s)
Normal PlacementApplied 13s placement-controller Resources have been applied to the selected cluster(s)
Normal PlacementAvailable 13s placement-controller Resources are available on the selected cluster(s)
Normal PlacementRolloutCompleted 13s placement-controller Placement has finished the rollout process and reached the desired status
- Verify resources on target clusters:
# Switch to member cluster context
kubectl config use-context <member-cluster-context>
# Check if resources are present
kubectl get resourceflavor default-flavor
kubectl get clusterqueue cluster-queue
kubectl get ns compute-jobs
5. Create LocalQueue on Hub
Create a LocalQueue that will be propagated to member clusters:
apiVersion: kueue.x-k8s.io/v1beta1
kind: LocalQueue
metadata:
namespace: compute-jobs
name: local-queue
spec:
clusterQueue: cluster-queue # Point to the ClusterQueue
A LocalQueue is a namespaced resource that receives workloads from users within the specified namespace. This resource will point to the ClusterQueue previously created.
6. Define Your AI Job(s) on Hub
Create your compute job(s) with Kueue annotations:
apiVersion: batch/v1
kind: Job
metadata:
name: mock-workload
namespace: compute-jobs
annotations:
kueue.x-k8s.io/queue-name: local-queue
spec:
ttlSecondsAfterFinished: 60 # Job will be deleted after 60 seconds
parallelism: 3
completions: 3
suspend: true # Set to true to allow Kueue to control the Job
template:
spec:
containers:
- name: compute
image: ubuntu:22.04
command:
- "/bin/bash"
- "-c"
- |
echo "Starting mock compute job..."
echo "Loading input dataset..."
sleep 10
echo "Epoch 1/3: Processing accuracy: 65%"
sleep 10
echo "Epoch 2/3: Processing accuracy: 85%"
sleep 10
echo "Epoch 3/3: Processing accuracy: 95%"
echo "Processing completed successfully!"
resources:
requests:
cpu: "1"
memory: "2Gi"
limits:
cpu: "1"
memory: "2Gi"
restartPolicy: Never
backoffLimit: 3
---
apiVersion: batch/v1
kind: Job
metadata:
name: model-evaluation
namespace: compute-jobs
annotations:
kueue.x-k8s.io/queue-name: local-queue
spec:
ttlSecondsAfterFinished: 60
parallelism: 3
completions: 3
suspend: true # Set to true to allow Kueue to control the Job
template:
spec:
containers:
- name: evaluation
image: ubuntu:22.04
command:
- "/bin/bash"
- "-c"
- |
echo "Starting model evaluation job..."
echo "Loading test dataset..."
sleep 5
echo "Running evaluation suite..."
sleep 10
echo "Computing metrics..."
echo "Accuracy: 94.5%"
echo "F1 Score: 0.93"
echo "Evaluation completed successfully!"
resources:
requests:
cpu: "1"
memory: "1Gi"
limits:
cpu: "1"
memory: "1Gi"
restartPolicy: Never
backoffLimit: 3
This Job defines the compute workload that will be scheduled by Kueue. The kueue.x-k8s.io/queue-name annotation tells Kueue which LocalQueue should manage this job, ensuring proper resource allocation and queuing behavior.
7. Create Independent ResourcePlacements for Jobs
When submitting jobs, each one can be placed independently to allow for dynamic scheduling based on current cluster conditions. Here’s how to create separate ResourcePlacements for each job:
# First, create a ResourcePlacement for the LocalQueue
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ResourcePlacement
metadata:
name: queue-placement
namespace: compute-jobs
spec:
resourceSelectors:
- group: kueue.x-k8s.io
version: v1beta1
kind: LocalQueue
name: local-queue
policy:
placementType: PickAll # Place queue in all available clusters
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
unavailablePeriodSeconds: 60
applyStrategy:
whenToApply: IfNotDrifted
revisionHistoryLimit: 15
---
# Then, create an independent ResourcePlacement for each job
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ResourcePlacement
metadata:
name: job1-placement
namespace: compute-jobs
spec:
resourceSelectors:
- group: batch
version: v1
kind: Job
name: mock-workload
policy:
placementType: PickN
numberOfClusters: 1 # Schedule each job to a single cluster
affinity:
clusterAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 40
preference:
propertySorter:
name: resources.kubernetes-fleet.io/available-cpu
sortOrder: Descending
- weight: 30
preference:
propertySorter:
name: resources.kubernetes-fleet.io/available-memory
sortOrder: Descending
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
unavailablePeriodSeconds: 60
applyStrategy:
whenToApply: IfNotDrifted
revisionHistoryLimit: 15
---
# Example of placing another job independently
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ResourcePlacement
metadata:
name: job2-placement
namespace: compute-jobs
spec:
resourceSelectors:
- group: batch
version: v1
kind: Job
name: model-evaluation
policy:
placementType: PickN
numberOfClusters: 1
affinity:
clusterAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 40
preference:
propertySorter:
name: resources.kubernetes-fleet.io/available-cpu
sortOrder: Descending
- weight: 30
preference:
propertySorter:
name: resources.kubernetes-fleet.io/available-memory
sortOrder: Descending
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
unavailablePeriodSeconds: 60
applyStrategy:
whenToApply: IfNotDrifted
revisionHistoryLimit: 15
This approach enables dynamic job scheduling for continuous job submissions. Here’s how it works:
Initial Setup:
- The LocalQueue is placed on all clusters through its own ResourcePlacement with
placementType: PickAll - This ensures any cluster can potentially receive jobs based on their current capacity
Continuous Job Submission Pattern:
When submitting jobs continuously, each job needs its own unique identity and ResourcePlacement:
a. Job Creation:
- Generate a unique name for each job (e.g., using timestamp)
- Create the job with the Kueue annotation pointing to the LocalQueue
- Set
suspend: true to allow Kueue to manage job execution - Define resource requirements specific to the job
b. ResourcePlacement Creation:
- Create a new ResourcePlacement for each job
- Name it to match or reference the job (e.g.,
<jobname>-placement) - Set
placementType: PickN with numberOfClusters: 1 - Configure affinity rules based on current requirements:
- CPU availability
- Memory availability
- Specific node capabilities
- Geographic location
- Cost considerations
c. Independent Scheduling:
- Each job’s ResourcePlacement operates independently
- Scheduling decisions are made based on real-time cluster conditions
- New jobs can be submitted without affecting existing ones
- Failed placements don’t block other job submissions
d. Resource Consideration:
- Check cluster capacity before submission
- Consider job priority and resource requirements
- Account for existing workload distribution
- Allow time for placement and resource allocation
Monitoring Job Distribution:
# Watch job distribution across clusters
watch 'for ctx in $(kubectl config get-contexts -o name); do
echo "=== Cluster: $ctx ==="
kubectl --context $ctx get jobs -n compute-jobs
done'
This pattern ensures:
- Jobs are distributed based on real-time resource availability
- No single cluster gets overloaded
- System remains responsive as new jobs are continuously submitted
- Each job can use different resource requirements or placement policies
- Failed placements don’t block the submission pipeline
Verify ResourcePlacements Completed
After creating the ResourcePlacements, verify that your jobs and LocalQueue are properly propagated:
- Check ResourcePlacement status for the LocalQueue:
# Get detailed status of the queue ResourcePlacement
kubectl describe resourceplacement queue-placement -n compute-jobs
- Check ResourcePlacement status for individual jobs:
# Get detailed status of job placements
kubectl describe resourceplacement job1-placement -n compute-jobs
kubectl describe resourceplacement job2-placement -n compute-jobs
Example
Name: job1-placement
Namespace: compute-jobs
Labels: <none>
Annotations: <none>
API Version: placement.kubernetes-fleet.io/v1beta1
Kind: ResourcePlacement
Metadata:
Creation Timestamp: 2025-10-23T22:41:26Z
Finalizers:
kubernetes-fleet.io/crp-cleanup
kubernetes-fleet.io/scheduler-cleanup
Generation: 1
Resource Version: 4416159
UID: 91666f24-9b16-43cd-90f3-9a2e715733be
Spec:
...
Status:
Conditions:
Last Transition Time: 2025-10-23T22:41:26Z
Message: found all cluster needed as specified by the scheduling policy, found 1 cluster(s)
Observed Generation: 1
Reason: SchedulingPolicyFulfilled
Status: True
Type: ResourcePlacementScheduled
Last Transition Time: 2025-10-23T22:41:26Z
Message: All 1 cluster(s) start rolling out the latest resource
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: ResourcePlacementRolloutStarted
Last Transition Time: 2025-10-23T22:41:26Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: ResourcePlacementOverridden
Last Transition Time: 2025-10-23T22:41:26Z
Message: Works(s) are succcesfully created or updated in 1 target cluster(s)' namespaces
Observed Generation: 1
Reason: WorkSynchronized
Status: True
Type: ResourcePlacementWorkSynchronized
Last Transition Time: 2025-10-23T22:41:32Z
Message: Failed to apply resources to 1 cluster(s), please check the `failedPlacements` status
Observed Generation: 1
Reason: ApplyFailed
Status: False
Type: ResourcePlacementApplied
Observed Resource Index: 0
Placement Statuses:
Cluster Name: cluster-3
Conditions:
Last Transition Time: 2025-10-23T22:41:26Z
Message: Successfully scheduled resources for placement in "cluster-3" (affinity score: 70, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2025-10-23T22:41:26Z
Message: Detected the new changes on the resources and started the rollout process
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: RolloutStarted
Last Transition Time: 2025-10-23T22:41:26Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: Overridden
Last Transition Time: 2025-10-23T22:41:26Z
Message: All of the works are synchronized to the latest
Observed Generation: 1
Reason: AllWorkSynced
Status: True
Type: WorkSynchronized
Last Transition Time: 2025-10-23T22:41:32Z
Message: Work object training.job1-placement-work has failed to apply
Observed Generation: 1
Reason: NotAllWorkHaveBeenApplied
Status: False
Type: Applied
Drifted Placements:
First Drifted Observed Time: 2025-10-23T22:41:32Z
Group: batch
Kind: Job
Name: mock-workload
Namespace: compute-jobs
Observation Time: 2025-10-23T22:41:45Z
Observed Drifts:
Path: /spec/selector/matchLabels/batch.kubernetes.io~1controller-uid
Value In Member: f9e62977-6c5c-48aa-a82b-1421e2647395
Path: /spec/suspend
Value In Hub: true
Value In Member: false
Path: /spec/template/metadata/creationTimestamp
Value In Member: <nil>
Path: /spec/template/metadata/labels/batch.kubernetes.io~1controller-uid
Value In Member: f9e62977-6c5c-48aa-a82b-1421e2647395
Path: /spec/template/metadata/labels/controller-uid
Value In Member: f9e62977-6c5c-48aa-a82b-1421e2647395
Target Cluster Observed Generation: 2
Version: v1
Failed Placements:
Condition:
Last Transition Time: 2025-10-23T22:41:32Z
Message: Failed to apply the manifest (error: cannot apply manifest: drifts are found between the manifest and the object from the member cluster in degraded mode (full comparison is performed instead of partial comparison, as the manifest object is considered to be invalid by the member cluster API server))
Observed Generation: 2
Reason: FoundDriftsInDegradedMode
Status: False
Type: Applied
Group: batch
Kind: Job
Name: mock-workload
Namespace: compute-jobs
Version: v1
Observed Resource Index: 0
Selected Resources:
Group: batch
Kind: Job
Name: mock-workload
Namespace: compute-jobs
Version: v1
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal PlacementRolloutStarted 23s placement-controller Started rolling out the latest resources
Normal PlacementOverriddenSucceeded 23s placement-controller Placement has been successfully overridden
Normal PlacementWorkSynchronized 23s placement-controller Work(s) have been created or updated successfully for the selected cluster(s)
Normal PlacementApplied 22s placement-controller Resources have been applied to the selected cluster(s)
Normal PlacementAvailable 22s placement-controller Resources are available on the selected cluster(s)
Normal PlacementRolloutCompleted 22s placement-controller Placement has finished the rollout process and reached the desired status
NOTE: The ResourcePlacement will complete rollout but with detect drifts after initial application as kueue takes over the resources. Completition indication can be found in the events.
- Verify resources on target cluster:
# Switch to member cluster context
kubectl config use-context <member-cluster-context>
# Check if job and localqueue exist in the namespace
kubectl get jobs,localqueue -n compute-jobs
How It Works
The job scheduling process combines ClusterResourcePlacement, ResourcePlacement, and Kueue in the following orchestrated workflow:
🔄 Workflow Overview
ClusterResourcePlacement Phase:
- Propagates cluster-scoped resources (ResourceFlavor, ClusterQueue) to selected member clusters
- Ensures the namespace is created on target clusters
- Sets up the foundational Kueue infrastructure across the fleet
ResourcePlacement Phase:
- Selects appropriate clusters based on resource constraints
- Propagates the AI/ML job and LocalQueue to the selected cluster(s)
Kueue Management Phase:
- Manages job admission based on ClusterQueue quotas
- Controls job execution through suspend/unsuspend mechanism
- Handles resource tracking and quota enforcement
- Maintains job queuing and priority order
🎯 Resource Flow
Hub Cluster Member Cluster(s)
├── ResourceFlavor ──────► ResourceFlavor
├── ClusterQueue ──────► ClusterQueue
├── Namespace ──────► Namespace
├── LocalQueue ──────► LocalQueue
└── AI Job ──────► AI Job → Kueue → Pod
Best Practices
Resource Management
- Always specify both requests and limits for resources
- Set realistic resource requirements based on workload needs
- Consider additional resources needed for data processing
Queue Configuration
- Configure quotas based on actual cluster capacity
- Create separate queues for different workload types
- Use cohorts to manage related jobs efficiently
Placement Strategy
- Define clear cluster selection criteria
- Consider workload requirements when setting affinities
- Plan for high availability with backup clusters
Monitoring and Troubleshooting
📊 Monitoring Job Status
Check Placement Status
# View ResourcePlacement status
kubectl get resourceplacement <rp-name> -n <namespace> -o yaml
# View ClusterResourcePlacement status
kubectl get clusterresourceplacement <crp-name> -o yaml
Monitor Queue Status on Member Cluster
# Check LocalQueue status
kubectl get localqueue <lq-name> -n <namespace>
# Check ClusterQueue status
kubectl get clusterqueue <cq-name> -o wide
# Check Job status
kubectl get job <job-name> -n <namespace>
📚 Documentation
4 - Tutorials
Guide for integrating KubeFleet with your development and operations workflows
This guide will help you understand how KubeFleet can seamlessly integrate with your development and operations workflows. Follow the instructions provided to get the most out of KubeFleet’s features. Below is a walkthrough of all the tutorials currently available.
4.1 - Resource Migration Across Clusters
Migrating Applications to Another Cluster When a Cluster Goes Down
This tutorial demonstrates how to move applications from clusters have gone down to other operational clusters using Fleet.
Scenario
Your fleet consists of the following clusters:
- Member Cluster 1 & Member Cluster 2 (WestUS, 1 node each)
- Member Cluster 3 (EastUS2, 2 nodes)
- Member Cluster 4 & Member Cluster 5 (WestEurope, 3 nodes each)
Due to certain circumstances, Member Cluster 1 and Member Cluster 2 are down, requiring you to migrate your applications from these clusters to other operational ones.
Current Application Resources
The following resources are currently deployed in Member Cluster 1 and Member Cluster 2 by the ClusterResourcePlacement:
Service
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: test-app
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
Summary:
- This defines a Kubernetes Service named
nginx-svc in the test-app namespace. - The service is of type LoadBalancer, meaning it exposes the application to the internet.
- It targets pods with the label app: nginx and forwards traffic to port 80 on the pods.
Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: test-app
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
ports:
- containerPort: 80
Summary:
- This defines a Kubernetes Deployment named
nginx-deployment in the test-app namespace. - It creates 2 replicas of the nginx pod, each running the
nginx:1.16.1 image. - The deployment ensures that the specified number of pods (replicas) are running and available.
- The pods are labeled with
app: nginx and expose port 80.
ClusterResourcePlacement
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"placement.kubernetes-fleet.io/v1","kind":"ClusterResourcePlacement","metadata":{"annotations":{},"name":"crp-migration"},"spec":{"policy":{"affinity":{"clusterAffinity":{"requiredDuringSchedulingIgnoredDuringExecution":{"clusterSelectorTerms":[{"labelSelector":{"matchLabels":{"fleet.azure.com/location":"westus"}}}]}}},"numberOfClusters":2,"placementType":"PickN"},"resourceSelectors":[{"group":"","kind":"Namespace","name":"test-app","version":"v1"}],"revisionHistoryLimit":10,"strategy":{"type":"RollingUpdate"}}}
creationTimestamp: "2024-07-25T21:27:35Z"
finalizers:
- kubernetes-fleet.io/crp-cleanup
- kubernetes-fleet.io/scheduler-cleanup
generation: 1
name: crp-migration
resourceVersion: "22177519"
uid: 0683cfaa-df24-4b2c-8a3d-07031692da8f
spec:
policy:
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
fleet.azure.com/location: westus
numberOfClusters: 2
placementType: PickN
resourceSelectors:
- group: ""
kind: Namespace
name: test-app
version: v1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
status:
conditions:
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: found all cluster needed as specified by the scheduling policy, found
2 cluster(s)
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: All 2 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: Works(s) are succcesfully created or updated in 2 target cluster(s)'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: The selected resources are successfully applied to 2 cluster(s)
observedGeneration: 1
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: "2024-07-25T21:27:45Z"
message: The selected resources in 2 cluster(s) are available now
observedGeneration: 1
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
observedResourceIndex: "0"
placementStatuses:
- clusterName: aks-member-2
conditions:
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: 'Successfully scheduled resources for placement in "aks-member-2"
(affinity score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-07-25T21:27:45Z"
message: All corresponding work objects are available
observedGeneration: 1
reason: AllWorkAreAvailable
status: "True"
type: Available
- clusterName: aks-member-1
conditions:
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: 'Successfully scheduled resources for placement in "aks-member-1"
(affinity score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-07-25T21:27:35Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-07-25T21:27:45Z"
message: All corresponding work objects are available
observedGeneration: 1
reason: AllWorkAreAvailable
status: "True"
type: Available
selectedResources:
- kind: Namespace
name: test-app
version: v1
- group: apps
kind: Deployment
name: nginx-deployment
namespace: test-app
version: v1
- kind: Service
name: nginx-service
namespace: test-app
version: v1
Summary:
- This defines a ClusterResourcePlacement named
crp-migration. - The PickN placement policy selects 2 clusters based on the label
fleet.azure.com/location: westus. Consequently, it chooses Member Cluster 1 and Member Cluster 2, as they are located in WestUS. - It targets resources in the
test-app namespace.
Migrating Applications to a Cluster to Other Operational Clusters
When the clusters in WestUS go down, update the ClusterResourcePlacement (CRP) to migrate the applications to other clusters.
In this tutorial, we will move them to Member Cluster 4 and Member Cluster 5, which are located in WestEurope.
Update the CRP for Migration to Clusters in WestEurope
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: crp-migration
spec:
policy:
placementType: PickN
numberOfClusters: 2
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
fleet.azure.com/location: westeurope # updated label
resourceSelectors:
- group: ""
kind: Namespace
name: test-app
version: v1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
Update the crp.yaml to reflect the new region and apply it:
kubectl apply -f crp.yaml
Results
After applying the updated crp.yaml, the Fleet will schedule the application on the available clusters in WestEurope.
You can check the status of the CRP to ensure that the application has been successfully migrated and is running on the newly selected clusters:
kubectl get crp crp-migration -o yaml
You should see a status indicating that the application is now running in the clusters located in WestEurope, similar to the following:
CRP Status
...
status:
conditions:
- lastTransitionTime: "2024-07-25T21:36:02Z"
message: found all cluster needed as specified by the scheduling policy, found
2 cluster(s)
observedGeneration: 2
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: All 2 cluster(s) start rolling out the latest resource
observedGeneration: 2
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: No override rules are configured for the selected resources
observedGeneration: 2
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: Works(s) are succcesfully created or updated in 2 target cluster(s)'
namespaces
observedGeneration: 2
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: The selected resources are successfully applied to 2 cluster(s)
observedGeneration: 2
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: The selected resources in 2 cluster(s) are available now
observedGeneration: 2
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
observedResourceIndex: "0"
placementStatuses:
- clusterName: aks-member-5
conditions:
- lastTransitionTime: "2024-07-25T21:36:02Z"
message: 'Successfully scheduled resources for placement in "aks-member-5" (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 2
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 2
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: No override rules are configured for the selected resources
observedGeneration: 2
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: All of the works are synchronized to the latest
observedGeneration: 2
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: All corresponding work objects are applied
observedGeneration: 2
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: All corresponding work objects are available
observedGeneration: 2
reason: AllWorkAreAvailable
status: "True"
type: Available
- clusterName: aks-member-4
conditions:
- lastTransitionTime: "2024-07-25T21:36:02Z"
message: 'Successfully scheduled resources for placement in "aks-member-4" (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 2
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 2
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: No override rules are configured for the selected resources
observedGeneration: 2
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: All of the works are synchronized to the latest
observedGeneration: 2
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: All corresponding work objects are applied
observedGeneration: 2
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-07-25T21:36:14Z"
message: All corresponding work objects are available
observedGeneration: 2
reason: AllWorkAreAvailable
status: "True"
type: Available
selectedResources:
- kind: Namespace
name: test-app
version: v1
- group: apps
kind: Deployment
name: nginx-deployment
namespace: test-app
version: v1
- kind: Service
name: nginx-service
namespace: test-app
version: v1
Conclusion
This tutorial demonstrated how to migrate applications using Fleet when clusters in one region go down.
By updating the ClusterResourcePlacement, you can ensure that your applications are moved to available clusters in another region, maintaining availability and resilience.
4.2 - Resource Migration With Overrides
Migrating Applications to Another Cluster For Higher Availability With Overrides
This tutorial shows how to migrate applications from clusters with lower availability to those with higher availability,
while also scaling up the number of replicas, using Fleet.
Scenario
Your fleet consists of the following clusters:
- Member Cluster 1 & Member Cluster 2 (WestUS, 1 node each)
- Member Cluster 3 (EastUS2, 2 nodes)
- Member Cluster 4 & Member Cluster 5 (WestEurope, 3 nodes each)
Due to a sudden increase in traffic and resource demands in your WestUS clusters, you need to migrate your applications to clusters in EastUS2 or WestEurope that have higher availability and can better handle the increased load.
Current Application Resources
The following resources are currently deployed in the WestUS clusters:
Service
Note: Service test file located here.
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: test-app
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
Summary:
- This defines a Kubernetes Service named
nginx-svc in the test-app namespace. - The service is of type LoadBalancer, meaning it exposes the application to the internet.
- It targets pods with the label app: nginx and forwards traffic to port 80 on the pods.
Deployment
Note: Deployment test file located here.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: test-app
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
ports:
- containerPort: 80
Note: The current deployment has 2 replicas.
Summary:
- This defines a Kubernetes Deployment named
nginx-deployment in the test-app namespace. - It creates 2 replicas of the nginx pod, each running the
nginx:1.16.1 image. - The deployment ensures that the specified number of pods (replicas) are running and available.
- The pods are labeled with
app: nginx and expose port 80.
ClusterResourcePlacement
Note: CRP Availability test file located here
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"placement.kubernetes-fleet.io/v1","kind":"ClusterResourcePlacement","metadata":{"annotations":{},"name":"crp-availability"},"spec":{"policy":{"affinity":{"clusterAffinity":{"requiredDuringSchedulingIgnoredDuringExecution":{"clusterSelectorTerms":[{"labelSelector":{"matchLabels":{"fleet.azure.com/location":"westus"}}}]}}},"numberOfClusters":2,"placementType":"PickN"},"resourceSelectors":[{"group":"","kind":"Namespace","name":"test-app","version":"v1"}],"revisionHistoryLimit":10,"strategy":{"type":"RollingUpdate"}}}
creationTimestamp: "2024-07-25T23:00:53Z"
finalizers:
- kubernetes-fleet.io/crp-cleanup
- kubernetes-fleet.io/scheduler-cleanup
generation: 1
name: crp-availability
resourceVersion: "22228766"
uid: 58dbb5d1-4afa-479f-bf57-413328aa61bd
spec:
policy:
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
fleet.azure.com/location: westus
numberOfClusters: 2
placementType: PickN
resourceSelectors:
- group: ""
kind: Namespace
name: test-app
version: v1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
status:
conditions:
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: found all cluster needed as specified by the scheduling policy, found
2 cluster(s)
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: All 2 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: Works(s) are succcesfully created or updated in 2 target cluster(s)'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: The selected resources are successfully applied to 2 cluster(s)
observedGeneration: 1
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: "2024-07-25T23:01:02Z"
message: The selected resources in 2 cluster(s) are available now
observedGeneration: 1
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
observedResourceIndex: "0"
placementStatuses:
- clusterName: aks-member-2
conditions:
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: 'Successfully scheduled resources for placement in "aks-member-2"
(affinity score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-07-25T23:01:02Z"
message: All corresponding work objects are available
observedGeneration: 1
reason: AllWorkAreAvailable
status: "True"
type: Available
- clusterName: aks-member-1
conditions:
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: 'Successfully scheduled resources for placement in "aks-member-1"
(affinity score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-07-25T23:00:53Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-07-25T23:01:02Z"
message: All corresponding work objects are available
observedGeneration: 1
reason: AllWorkAreAvailable
status: "True"
type: Available
selectedResources:
- kind: Namespace
name: test-app
version: v1
- group: apps
kind: Deployment
name: nginx-deployment
namespace: test-app
version: v1
- kind: Service
name: nginx-service
namespace: test-app
version: v1
Summary:
- This defines a ClusterResourcePlacement named
crp-availability. - The placement policy PickN selects 2 clusters. The clusters are selected based on the label
fleet.azure.com/location: westus. - It targets resources in the
test-app namespace.
Identify Clusters with More Availability
To identify clusters with more availability, you can check the member cluster properties.
kubectl get memberclusters -A -o wide
The output will show the availability in each cluster, including the number of nodes, available CPU, and memory.
NAME JOINED AGE NODE-COUNT AVAILABLE-CPU AVAILABLE-MEMORY ALLOCATABLE-CPU ALLOCATABLE-MEMORY
aks-member-1 True 22d 1 30m 40Ki 1900m 4652296Ki
aks-member-2 True 22d 1 30m 40Ki 1900m 4652296Ki
aks-member-3 True 22d 2 2820m 8477196Ki 3800m 9304588Ki
aks-member-4 True 22d 3 4408m 12896012Ki 5700m 13956876Ki
aks-member-5 True 22d 3 4408m 12896024Ki 5700m 13956888Ki
Based on the available resources, you can see that Member Cluster 3 in EastUS2 and Member Cluster 4 & 5 in WestEurope have more nodes and available resources compared to the WestUS clusters.
Migrating Applications to a Different Cluster with More Availability While Scaling Up
When the clusters in WestUS are nearing capacity limits and risk becoming overloaded, update the ClusterResourcePlacement (CRP) to migrate the applications to clusters in EastUS2 or WestEurope, which have more available resources and can handle increased demand more effectively.
For this tutorial, we will move them to WestEurope.
Create Resource Override
Note: Cluster resource override test file located here
To scale up during migration, apply this override before updating crp:
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
name: ro-1
namespace: test-app
spec:
resourceSelectors:
- group: apps
kind: Deployment
version: v1
name: nginx-deployment
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
fleet.azure.com/location: westeurope
jsonPatchOverrides:
- op: replace
path: /spec/replicas
value:
4
This override updates the nginx-deployment Deployment in the test-app namespace by setting the number of replicas to “4” for clusters located in the westeurope region.
Update the CRP for Migration
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourcePlacement
metadata:
name: crp-availability
spec:
policy:
placementType: PickN
numberOfClusters: 2
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- propertySelector:
matchExpressions:
- name: kubernetes-fleet.io/node-count
operator: Ge
values:
- "3"
resourceSelectors:
- group: ""
kind: Namespace
name: test-app
version: v1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
Update the crp-availability.yaml to reflect selecting clusters with higher node-count and apply it:
kubectl apply -f crp-availability.yaml
Results
After applying the updated crp-availability.yaml, the Fleet will schedule the application on the available clusters in WestEurope as they each have 3 nodes.
You can check the status of the CRP to ensure that the application has been successfully migrated and is running in the new region:
kubectl get crp crp-availability -o yaml
You should see a status indicating that the application is now running in the WestEurope clusters, similar to the following:
CRP Status
...
status:
conditions:
- lastTransitionTime: "2024-07-25T23:10:08Z"
message: found all cluster needed as specified by the scheduling policy, found
2 cluster(s)
observedGeneration: 2
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-07-25T23:10:20Z"
message: All 2 cluster(s) start rolling out the latest resource
observedGeneration: 2
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-07-25T23:10:20Z"
message: The selected resources are successfully overridden in 2 cluster(s)
observedGeneration: 2
reason: OverriddenSucceeded
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-07-25T23:10:20Z"
message: Works(s) are succcesfully created or updated in 2 target cluster(s)'
namespaces
observedGeneration: 2
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2024-07-25T23:10:21Z"
message: The selected resources are successfully applied to 2 cluster(s)
observedGeneration: 2
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: "2024-07-25T23:10:30Z"
message: The selected resources in 2 cluster(s) are available now
observedGeneration: 2
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
observedResourceIndex: "0"
placementStatuses:
- applicableResourceOverrides:
- name: ro-1-0
namespace: test-app
clusterName: aks-member-5
conditions:
- lastTransitionTime: "2024-07-25T23:10:08Z"
message: 'Successfully scheduled resources for placement in "aks-member-5" (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 2
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-07-25T23:10:20Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 2
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-07-25T23:10:20Z"
message: Successfully applied the override rules on the resources
observedGeneration: 2
reason: OverriddenSucceeded
status: "True"
type: Overridden
- lastTransitionTime: "2024-07-25T23:10:20Z"
message: All of the works are synchronized to the latest
observedGeneration: 2
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-07-25T23:10:21Z"
message: All corresponding work objects are applied
observedGeneration: 2
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-07-25T23:10:30Z"
message: All corresponding work objects are available
observedGeneration: 2
reason: AllWorkAreAvailable
status: "True"
type: Available
- applicableResourceOverrides:
- name: ro-1-0
namespace: test-app
clusterName: aks-member-4
conditions:
- lastTransitionTime: "2024-07-25T23:10:08Z"
message: 'Successfully scheduled resources for placement in "aks-member-4" (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 2
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-07-25T23:10:08Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 2
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-07-25T23:10:08Z"
message: Successfully applied the override rules on the resources
observedGeneration: 2
reason: OverriddenSucceeded
status: "True"
type: Overridden
- lastTransitionTime: "2024-07-25T23:10:08Z"
message: All of the works are synchronized to the latest
observedGeneration: 2
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-07-25T23:10:09Z"
message: All corresponding work objects are applied
observedGeneration: 2
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-07-25T23:10:19Z"
message: All corresponding work objects are available
observedGeneration: 2
reason: AllWorkAreAvailable
status: "True"
type: Available
selectedResources:
- kind: Namespace
name: test-app
version: v1
- group: apps
kind: Deployment
name: nginx-deployment
namespace: test-app
version: v1
- kind: Service
name: nginx-service
namespace: test-app
version: v1
The status indicates that the application has been successfully migrated to the WestEurope clusters and is now running with 4 replicas, as the resource override has been applied.
To double-check, you can also verify the number of replicas in the nginx-deployment:
Change context to member cluster 4 or 5:
kubectl config use-context aks-member-4
Get the deployment:
kubectl get deployment nginx-deployment -n test-app -o wide
Conclusion
This tutorial demonstrated how to migrate applications using Fleet from clusters with lower availability to those with higher availability.
By updating the ClusterResourcePlacement and applying a ResourceOverride, you can ensure that your applications are moved to clusters with better availability while also scaling up the number of replicas to enhance performance and resilience.
4.3 - KubeFleet and ArgoCD Integration
See KubeFleet and ArgoCD working together to efficiently manage Gitops promotion
This hands-on guide of KubeFleet and ArgoCD integration shows how these powerful tools work in concert to revolutionize multi-cluster application management.
Discover how KubeFleet’s intelligent orchestration capabilities complement ArgoCD’s popular GitOps approach, enabling seamless deployments across diverse environments while maintaining consistency and control.
This tutorial illuminates practical strategies for targeted deployments, environment-specific configurations, and safe, controlled rollouts.
Follow along to transform your multi-cluster challenges into streamlined, automated workflows that enhance both developer productivity and operational reliability.
Suppose in a multi-cluster, multi-tenant organization, team A wants to deploy the resources ONLY to the clusters they own.
They want to make sure each cluster receives the correct configuration, and they want to ensure safe deployment by rolling out to their staging environment first, then to canary if staging is healthy, and lastly to the production.
Our tutorial will walk you through a hands-on experience of how to achieve this. Below image demonstrates the major components and their interactions.
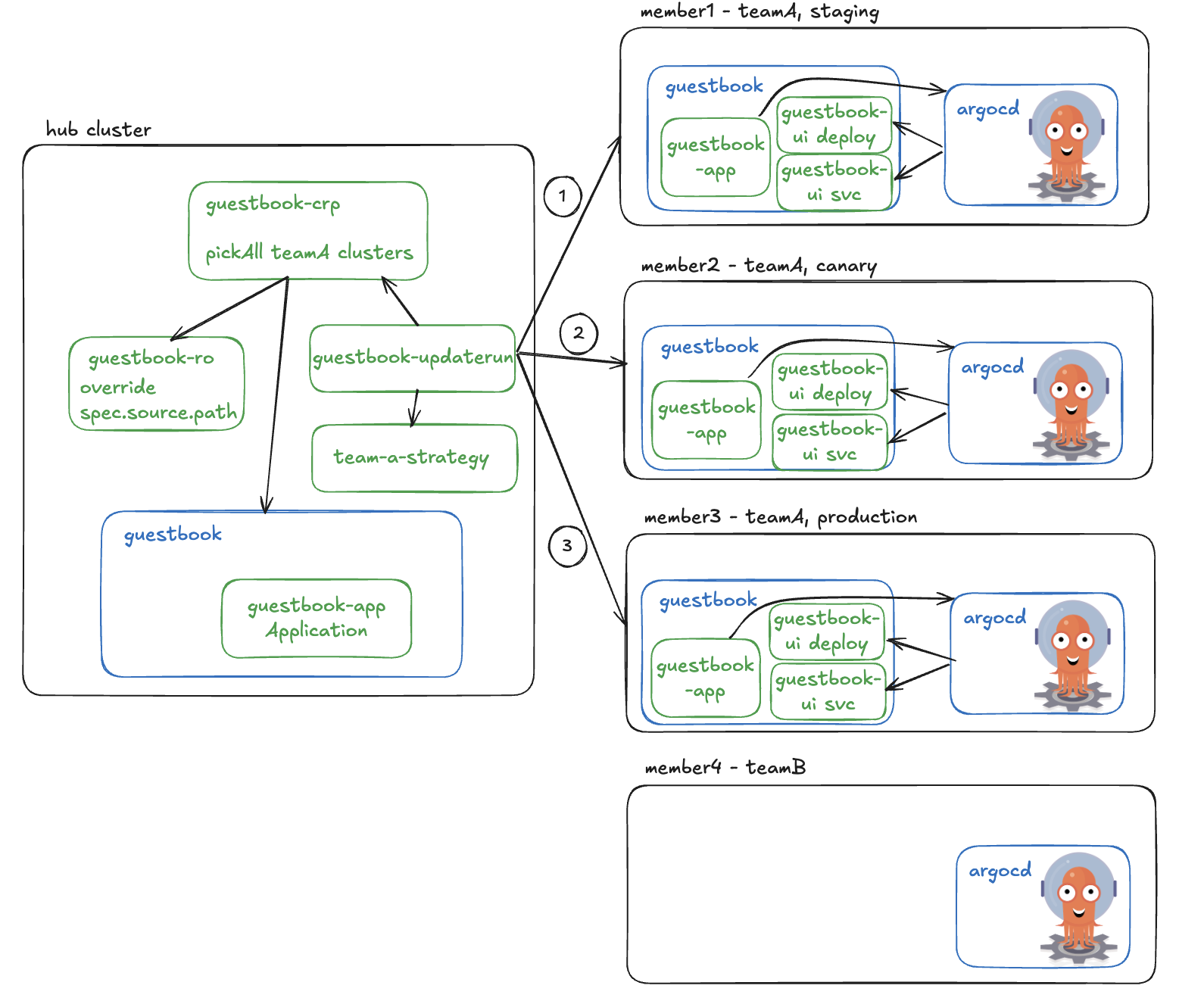
Prerequisites
KubeFleet environment
In this tutorial, we prepare a fleet environment with one hub cluster and four member clusters.
The member clusters are labeled to indicate their environment and team ownership.
From the hub cluster, we can verify the clustermembership and their labels:
kubectl config use-context hub
kubectl get memberclusters --show-labels
NAME JOINED AGE MEMBER-AGENT-LAST-SEEN NODE-COUNT AVAILABLE-CPU AVAILABLE-MEMORY LABELS
member1 True 84d 10s 3 4036m 13339148Ki environment=staging,team=A,...
member2 True 84d 14s 3 4038m 13354748Ki environment=canary,team=A,...
member3 True 144m 6s 3 3676m 12458504Ki environment=production,team=A,...
member4 True 6m7s 15s 3 4036m 13347336Ki team=B,...
From above output, we can see that:
member1 is in staging environment and owned by team A.member2 is in canary environment and owned by team A.member3 is in production environment and owned by team A.member4 is owned by team B.
Install ArgoCD
In this tutorial, we expect ArgoCD controllers to be installed on each member cluster. Only ArgoCD CRDs need to be installed on the hub cluster so that ArgoCD Applications can be created.
Option 1: Install ArgoCD on each member cluster directly (RECOMMENDED)
It’s straightforward to install ArgoCD on each member cluster. You can follow the instructions in ArgoCD Getting Started.
To install only CRDs on the hub cluster, you can run the following command:
kubectl config use-context hub
kubectl apply -k https://github.com/argoproj/argo-cd/manifests/crds?ref=stable --server-side=true
Option 2: Use KubeFleet ClusterResourcePlacement (CRP) to install ArgoCD on member clusters (Experimental)
Alternatively, you can first install all the ArgoCD manifests on the hub cluster, and then use KubeFleet ClusterResourcePlacement to populate to the member clusters.
Install the CRDs on the hub cluster:
kubectl config use-context hub
kubectl apply -k https://github.com/argoproj/argo-cd/manifests/crds?ref=stable --server-side=true
Then apply the resource manifest we prepared (argocd-install.yaml) to the hub cluster:
kubectl config use-context hub
kubectl create ns argocd && kubectl apply -f ./manifests/argocd-install.yaml -n argocd --server-side=true
We then use a ClusterResourcePlacement (refer to argocd-crp.yaml) to populate the manifests to the member clusters:
kubectl config use-context hub
kubectl apply -f ./manifests/argocd-crp.yaml
Verify the CRP becomes available:
kubectl get crp
NAME GEN SCHEDULED SCHEDULED-GEN AVAILABLE AVAILABLE-GEN AGE
crp-argocd 1 True 1 True 1 79m
Enable “Applications in any namespace” in ArgoCD
In this tutorial, we are going to deploy an ArgoCD Application in the guestbook namespace.
Enabling “Applications in any namespace” feature, application teams can manage their applications in a more flexible way without the risk of a privilege escalation. In this tutorial, we need to enable Applications to be created in the guestbook namespace.
Option 1: Enable on each member cluster manually
You can follow the instructions in ArgoCD Applications-in-any-namespace documentation to enable this feature on each member cluster manually.
It generally involves updating the argocd-cmd-params-cm configmap and restarting the argocd-application-controller statefulset and argocd-server deployment.
You will also want to create an ArgoCD AppProject in the argocd namespace for Applications to refer to. You can find the manifest at guestbook-appproject.yaml.
cat ./manifests/guestbook-appproject.yaml
apiVersion: argoproj.io/v1alpha1
kind: AppProject
metadata:
name: guestbook-project
namespace: argocd
spec:
sourceNamespaces:
- guestbook
destinations:
- namespace: '*'
server: https://kubernetes.default.svc
sourceRepos:
- '*'
kubectl config use-context member<*>
kubectl apply -f ./manifests/guestbook-appproject.yaml
Option 2: Populate ArgoCD AppProject to member clusters with CRP (Experimental)
If you tried above Option 2 to install ArgoCD from hub cluster to member clusters, you gain the flexibility by just updating the argocd-cmd-params-cm configmap, and adding the guestbook-appproject to the argocd namespace, and existing CRP will populate the resources automatically to the member clusters. Note: you probably also want to update the argocd-application-controller and argocd-server a bit to trigger pod restarts.
Deploy resources to clusters using ArgoCD Application orchestrated by KubeFleet
We have prepared one guestbook-ui deployment with corresponding service for each environment.
The deployments are same except for the replica count. This simulates different configurations for different clusters. You may find the manifests here.
guestbook
│
└───staging
│ │ guestbook-ui.yaml
|
└───canary
| │ guestbook-ui.yaml
|
└───production
│ guestbook-ui.yaml
Deploy an ArgoCD Application for gitops continuous delivery
Team A want to create an ArgoCD Application to automatically sync the manifests from git repository to the member clusters.
The Application should be created on the hub cluster and placed onto the member clusters team A owns. The Application example can be found at guestbook-app.yaml.
kubectl config use-context hub
kubectl create ns guestbook
kubectl apply of - << EOF
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: guestbook-app
namespace: guestbook
spec:
destination:
namespace: guestbook
server: https://kubernetes.default.svc
project: guestbook-project
source:
path: content/en/docs/tutorials/ArgoCD/manifests/guestbook
repoURL: https://github.com/kubefleet-dev/website.git
targetRevision: main
syncPolicy:
automated:
prune: true
selfHeal: true
retry:
backoff:
duration: 5s
factor: 2
maxDuration: 3m0s
limit: 10
syncOptions:
- PruneLast=true
- PrunePropagationPolicy=foreground
- CreateNamespace=true
- ApplyOutOfSyncOnly=true
EOF
Place ArgoCD Application to member clusters with CRP
A ClusterResourcePlacement (CRP) is used to place resources on the hub cluster to member clusters.
Team A is able to select their own member clusters by specifying cluster labels.
In spec.resourceSelectors, specifying guestbook namespace includes all resources in it including the Application just deployed.
The spec.strategy.type is set to External so that CRP is not rolled out immediately. Instead, rollout will be triggered separately in next steps.
The CRP resource can be found at guestbook-crp.yaml.
kubectl config use-context hub
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacement
metadata:
name: guestbook-crp
spec:
policy:
placementType: PickAll # select all member clusters with label team=A
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
team: A # label selectors
resourceSelectors:
- group: ""
kind: Namespace
name: guestbook # select guestbook namespace with all resources in it
version: v1
revisionHistoryLimit: 10
strategy:
type: External # will use an updateRun to trigger the rollout
EOF
Verify the CRP status and it’s clear that only member1, member2, and member3 are selected with team=A label are selected, and rollout has not started yet.
kubectl get crp guestbook-crp -o yaml
...
status:
conditions:
- lastTransitionTime: "2025-03-23T23:46:56Z"
message: found all cluster needed as specified by the scheduling policy, found
3 cluster(s)
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2025-03-23T23:46:56Z"
message: There are still 3 cluster(s) in the process of deciding whether to roll
out the latest resources or not
observedGeneration: 1
reason: RolloutStartedUnknown
status: Unknown
type: ClusterResourcePlacementRolloutStarted
observedResourceIndex: "0"
placementStatuses:
- clusterName: member1
conditions:
- lastTransitionTime: "2025-03-24T00:22:22Z"
message: 'Successfully scheduled resources for placement in "member1" (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2025-03-24T00:22:22Z"
message: In the process of deciding whether to roll out the latest resources
or not
observedGeneration: 1
reason: RolloutStartedUnknown
status: Unknown
type: RolloutStarted
- clusterName: member2
conditions:
- lastTransitionTime: "2025-03-23T23:46:56Z"
message: 'Successfully scheduled resources for placement in "member2" (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2025-03-23T23:46:56Z"
message: In the process of deciding whether to roll out the latest resources
or not
observedGeneration: 1
reason: RolloutStartedUnknown
status: Unknown
type: RolloutStarted
- clusterName: member3
conditions:
- lastTransitionTime: "2025-03-23T23:46:56Z"
message: 'Successfully scheduled resources for placement in "member3" (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2025-03-23T23:46:56Z"
message: In the process of deciding whether to roll out the latest resources
or not
observedGeneration: 1
reason: RolloutStartedUnknown
status: Unknown
type: RolloutStarted
...
Override path for different member clusters with ResourceOverride
Above Application specifies spec.source.path as content/en/docs/tutorials/ArgoCD/manifests/guestbook.
By default, every member cluster selected receives the same Application resource.
In this tutorial, member clusters from different environments should receive different manifests, as configured in different folders in the git repo.
To achieve this, a ResourceOverride is used to override the Application resource for each member cluster.
The ResourceOverride resource can be found at guestbook-ro.yaml.
kubectl config use-context hub
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1alpha1
kind: ResourceOverride
metadata:
name: guestbook-app-ro
namespace: guestbook # ro needs to be created in the same namespace as the resource it overrides
spec:
placement:
name: guestbook-crp # specify the CRP name
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchExpressions:
- key: environment
operator: Exists
jsonPatchOverrides:
- op: replace
path: /spec/source/path # spec.source.path is overridden
value: "content/en/docs/tutorials/ArgoCD/manifests/guestbook/${MEMBER-CLUSTER-LABEL-KEY-environment}"
overrideType: JSONPatch
resourceSelectors:
- group: argoproj.io
kind: Application
name: guestbook-app # name of the Application
version: v1alpha1
EOF
Trigger CRP progressive rollout with clusterStagedUpdateRun
A ClusterStagedUpdateRun (or updateRun for short) is used to trigger the rollout of the CRP in a progressive, stage-by-stage manner by following a pre-defined rollout strategy, namely ClusterStagedUpdateStrategy.
A ClusterStagedUpdateStrategy is provided at teamA-strategy.yaml.
It defines 3 stages: staging, canary, and production. Clusters are grouped by label environment into different stages.
The TimedWait after-stage task in staging stageis used to pause the rollout for 1 minute before moving to canary stage.s
The Approval after-stage task in canary stage waits for manual approval before moving to production stage.
After applying the strategy, a ClusterStagedUpdateRun can then reference it to generate the concrete test plan.
kubectl config use-context hub
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateStrategy
metadata:
name: team-a-strategy
spec:
stages: # 3 stages: staging, canary, production
- afterStageTasks:
- type: TimedWait
waitTime: 1m # wait 1 minute before moving to canary stage
labelSelector:
matchLabels:
environment: staging
name: staging
- afterStageTasks:
- type: Approval # wait for manual approval before moving to production stage
labelSelector:
matchLabels:
environment: canary
name: canary
- labelSelector:
matchLabels:
environment: production
name: production
EOF
Now it’s time to trigger the rollout. A sample ClusterStagedUpdateRun can be found at guestbook-updaterun.yaml.
It’s pretty straightforward, just specifying the CRP resource name, the strategy name, and resource version.
kubectl config use-context hub
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
name: guestbook-updaterun
spec:
placementName: guestbook-crp
resourceSnapshotIndex: "0"
stagedRolloutStrategyName: team-a-strategy
EOF
Checking the updateRun status to see the rollout progress, member1 in staging stage has been updated, and it’s pausing at the after-stage task before moving to canary stage.
kubectl config use-context hub
kubectl get crsur gestbook-updaterun -o yaml
...
stagesStatus:
- afterStageTaskStatus:
- type: TimedWait
clusters:
- clusterName: member1
conditions:
- lastTransitionTime: "2025-03-24T00:47:41Z"
message: ""
observedGeneration: 1
reason: ClusterUpdatingStarted
status: "True"
type: Started
- lastTransitionTime: "2025-03-24T00:47:56Z"
message: ""
observedGeneration: 1
reason: ClusterUpdatingSucceeded
status: "True"
type: Succeeded
resourceOverrideSnapshots:
- name: guestbook-app-ro-0
namespace: guestbook
conditions:
- lastTransitionTime: "2025-03-24T00:47:56Z"
message: ""
observedGeneration: 1
reason: StageUpdatingWaiting
status: "False"
type: Progressing
stageName: staging
startTime: "2025-03-24T00:47:41Z"
- afterStageTaskStatus:
- approvalRequestName: guestbook-updaterun-canary
type: Approval
clusters:
- clusterName: member2
resourceOverrideSnapshots:
- name: guestbook-app-ro-0
namespace: guestbook
stageName: canary
- clusters:
- clusterName: member3
resourceOverrideSnapshots:
- name: guestbook-app-ro-0
namespace: guestbook
stageName: production
...
Checking the Application status on each member cluster, and it’s synced and healthy:
kubectl config use-context member1
kubectl get Applications -n guestbook
NAMESPACE NAME SYNC STATUS HEALTH STATUS
guestbook guestbook-app Synced Healthy
At the same time, there’s no Application in member2 or member3 as they are not rolled out yet.
After 1 minute, the staging stage is completed, and member2 in canary stage is updated.
kubectl config use-context hub
kubectl get crsur guestbook-updaterun -o yaml
...
- afterStageTaskStatus:
- approvalRequestName: guestbook-updaterun-canary
conditions:
- lastTransitionTime: "2025-03-24T00:49:11Z"
message: ""
observedGeneration: 1
reason: AfterStageTaskApprovalRequestCreated
status: "True"
type: ApprovalRequestCreated
type: Approval
clusters:
- clusterName: member2
conditions:
- lastTransitionTime: "2025-03-24T00:48:56Z"
message: ""
observedGeneration: 1
reason: ClusterUpdatingStarted
status: "True"
type: Started
- lastTransitionTime: "2025-03-24T00:49:11Z"
message: ""
observedGeneration: 1
reason: ClusterUpdatingSucceeded
status: "True"
type: Succeeded
resourceOverrideSnapshots:
- name: guestbook-app-ro-0
namespace: guestbook
conditions:
- lastTransitionTime: "2025-03-24T00:49:11Z"
message: ""
observedGeneration: 1
reason: StageUpdatingWaiting
status: "False"
type: Progressing
stageName: canary
startTime: "2025-03-24T00:48:56Z"
...
canary stage requires manual approval to complete. The controller generates a ClusterApprovalRequest object for user to approve.
The name is included in the updateRun status, as shown above, approvalRequestName: guestbook-updaterun-canary.
Team A can verify everything works properly and then approve the request to proceed to production stage:
kubectl config use-context hub
kubectl get clusterapprovalrequests
NAME UPDATE-RUN STAGE APPROVED APPROVALACCEPTED AGE
guestbook-updaterun-canary guestbook-updaterun canary 21m
kubectl patch clusterapprovalrequests guestbook-updaterun-canary --type='merge' -p '{"status":{"conditions":[{"type":"Approved","status":"True","reason":"lgtm","message":"lgtm","lastTransitionTime":"'$(date -u +%Y-%m-%dT%H:%M:%SZ)'","observedGeneration":1}]}}' --subresource=status
kubectl get clusterapprovalrequests
NAME UPDATE-RUN STAGE APPROVED APPROVALACCEPTED AGE
guestbook-updaterun-canary guestbook-updaterun canary True True 22m
Not the updateRun moves on to production stage, and member3 is updated. The whole updateRun is completed:
kubectl config use-context hub
kubectl get crsur guestbook-updaterun -o yaml
...
status:
conditions:
- lastTransitionTime: "2025-03-24T00:47:41Z"
message: ClusterStagedUpdateRun initialized successfully
observedGeneration: 1
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: "2025-03-24T00:47:41Z"
message: ""
observedGeneration: 1
reason: UpdateRunStarted
status: "True"
type: Progressing
- lastTransitionTime: "2025-03-24T01:11:45Z"
message: ""
observedGeneration: 1
reason: UpdateRunSucceeded
status: "True"
type: Succeeded
...
stagesStatus:
...
- clusters:
- clusterName: member3
conditions:
- lastTransitionTime: "2025-03-24T01:11:30Z"
message: ""
observedGeneration: 1
reason: ClusterUpdatingStarted
status: "True"
type: Started
- lastTransitionTime: "2025-03-24T01:11:45Z"
message: ""
observedGeneration: 1
reason: ClusterUpdatingSucceeded
status: "True"
type: Succeeded
resourceOverrideSnapshots:
- name: guestbook-app-ro-0
namespace: guestbook
conditions:
- lastTransitionTime: "2025-03-24T01:11:45Z"
message: ""
observedGeneration: 1
reason: StageUpdatingWaiting
status: "False"
type: Progressing
- lastTransitionTime: "2025-03-24T01:11:45Z"
message: ""
observedGeneration: 1
reason: StageUpdatingSucceeded
status: "True"
type: Succeeded
endTime: "2025-03-24T01:11:45Z"
stageName: production
startTime: "2025-03-24T01:11:30Z"
...
Verify the Application on member clusters
Now we are able to see the Application is created, synced, and healthy on all member clusters except member4 as it does not belong to team A.
We can also verify that the configMaps synced from git repo are different for each member cluster:
kubectl config use-context member1
kubectl get app -n guestbook
NAMESPACE NAME SYNC STATUS HEALTH STATUS
guestbook guestbook-app Synced Healthy
kubectl get deploy,svc -n guestbook
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/guestbook-ui 1/1 1 1 80s # 1 replica in staging env
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/guestbook-ui ClusterIP 10.0.20.139 <none> 80/TCP 79s
# verify member2
kubectl config use-context member2
kubectl get app -n guestbook
NAMESPACE NAME SYNC STATUS HEALTH STATUS
guestbook guestbook-app Synced Healthy
kubectl get deploy,svc -n guestbook
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/guestbook-ui 2/2 2 2 54s # 2 replicas in canary env
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/guestbook-ui ClusterIP 10.0.20.139 <none> 80/TCP 54s
# verify member3
kubectl config use-context member3
kubectl get app -n guestbook
NAMESPACE NAME SYNC STATUS HEALTH STATUS
guestbook guestbook-app Synced Healthy
kubectl get deploy,svc -n guestbook
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/guestbook-ui 4/4 4 4 18s # 4 replicas in production env
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/guestbook-ui ClusterIP 10.0.20.139 <none> 80/TCP 17s
# verify member4
kubectl config use-context member4
kubectl get app -A
No resources found
Release a new version
When team A makes some changes and decides to release a new version, they can cut a new branch or tag in the git repo.
To rollout this new version progressively, they can simply:
- Update the
targetRevision in the Application resource to the new branch or tag on the hub cluster. - Create a new
ClusterStagedUpdateRun with the new resource snapshot index.
Suppose now we cut a new release on branch v0.0.1.
Updating the spec.source.targetRevision in the Application resource to v0.0.1 will not trigger rollout instantly.
kubectl config use-context hub
kubectl edit app guestbook-app -n guestbook
...
spec:
source:
targetRevision: v0.0.1 # <- replace with your release branch
...
Checking the crp, and it’s clear that the new Application is not available yet:
kubectl config use-context hub
kubectl get crp
NAME GEN SCHEDULED SCHEDULED-GEN AVAILABLE AVAILABLE-GEN AGE
guestbook-crp 1 True 1 130m
Check a new version of ClusterResourceSnapshot is generated:
kubectl config use-context hub
kubectl get clusterresourcesnapshots --show-labels
NAME GEN AGE LABELS
guestbook-crp-0-snapshot 1 133m kubernetes-fleet.io/is-latest-snapshot=false,kubernetes-fleet.io/parent-CRP=guestbook-crp,kubernetes-fleet.io/resource-index=0
guestbook-crp-1-snapshot 1 3m46s kubernetes-fleet.io/is-latest-snapshot=true,kubernetes-fleet.io/parent-CRP=guestbook-crp,kubernetes-fleet.io/resource-index=1
Notice that guestbook-crp-1-snapshot is latest with resource-index set to 1.
Create a new ClusterStagedUpdateRun with the new resource snapshot index:
kubectl config use-context hub
kubectl apply -f - << EOF
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterStagedUpdateRun
metadata:
name: guestbook-updaterun
spec:
placementName: guestbook-crp
resourceSnapshotIndex: "1"
stagedRolloutStrategyName: team-a-strategy
EOF
Following the same steps as before, we can see the new version is rolled out progressively to all member clusters.
Summary
KubeFleet and ArgoCD integration offers a powerful solution for multi-cluster application management, combining KubeFleet’s intelligent orchestration with ArgoCD’s popular GitOps approach. This tutorial showcased how teams can deploy applications across diverse environments with cluster-specific configurations while maintaining complete control over the rollout process. Through practical examples, we demonstrated targeted deployments using cluster labels, environment-specific configurations via overrides, and safe, controlled rollouts with staged update runs. This integration enables teams to transform multi-cluster challenges into streamlined, automated workflows that enhance both developer productivity and operational reliability.
Next steps
5 - Troubleshooting Guides
Guides for identifying and fixing common KubeFleet issues
KubeFleet documentation features a number of troubleshooting guides to help you identify and fix
KubeFleet issues you encounter. Pick one below to proceed.
5.1 - ClusterResourcePlacement TSG
Identify and fix KubeFleet issues associated with the ClusterResourcePlacement API
This TSG is meant to help you troubleshoot issues with the ClusterResourcePlacement API in Fleet.
Cluster Resource Placement
Internal Objects to keep in mind when troubleshooting CRP related errors on the hub cluster:
ClusterResourceSnapshotClusterSchedulingPolicySnapshotClusterResourceBindingWork
Please read the Fleet API reference for more details about each object.
Complete Progress of the ClusterResourcePlacement
Understanding the progression and the status of the ClusterResourcePlacement custom resource is crucial for diagnosing and identifying failures.
You can view the status of the ClusterResourcePlacement custom resource by using the following command:
kubectl describe clusterresourceplacement <name>
The complete progression of ClusterResourcePlacement is as follows:
ClusterResourcePlacementScheduled: Indicates a resource has been scheduled for placement.ClusterResourcePlacementRolloutStarted: Indicates the rollout process has begun.ClusterResourcePlacementOverridden: Indicates the resource has been overridden.ClusterResourcePlacementWorkSynchronized: Indicates the work objects have been synchronized.ClusterResourcePlacementApplied: Indicates the resource has been applied. This condition will only be populated if the
apply strategy in use is of the type ClientSideApply (default) or ServerSideApply.ClusterResourcePlacementAvailable: Indicates the resource is available. This condition will only be populated if the
apply strategy in use is of the type ClientSideApply (default) or ServerSideApply.ClusterResourcePlacementDiffreported: Indicates whether diff reporting has completed on all resources. This condition
will only be populated if the apply strategy in use is of the type ReportDiff.
How can I debug if some clusters are not selected as expected?
Check the status of the ClusterSchedulingPolicySnapshot to determine which clusters were selected along with the reason.
How can I debug if a selected cluster does not have the expected resources on it or if CRP doesn’t pick up the latest changes?
Please check the following cases,
- Check whether the
ClusterResourcePlacementRolloutStarted condition in ClusterResourcePlacement status is set to true or false. - If
false, see Scheduling Failure TSG. - If
true,- Check to see if
ClusterResourcePlacementApplied condition is set to unknown, false or true. - If
unknown, wait for the process to finish, as the resources are still being applied to the member cluster. If the state remains unknown for a while, create a issue, as this is an unusual behavior. - If
false, refer to Work-Application Failure TSG. - If
true, verify that the resource exists on the hub cluster.
We can also take a look at the placementStatuses section in ClusterResourcePlacement status for that particular cluster. In placementStatuses we would find failedPlacements section which should have the reasons as to why resources failed to apply.
How can I debug if the drift detection result or the configuration difference check result are different from my expectations?
See the Drift Detection and Configuration Difference Check Unexpected Result TSG for more information.
How can I find and verify the latest ClusterSchedulingPolicySnapshot for a ClusterResourcePlacement?
To find the latest ClusterSchedulingPolicySnapshot for a ClusterResourcePlacement resource, run the following command:
kubectl get clusterschedulingpolicysnapshot -l kubernetes-fleet.io/is-latest-snapshot=true,kubernetes-fleet.io/parent-CRP={CRPName}
NOTE: In this command, replace {CRPName} with your ClusterResourcePlacement name.
Then, compare the ClusterSchedulingPolicySnapshot with the ClusterResourcePlacement policy to make sure that they match, excluding the numberOfClusters field from the ClusterResourcePlacement spec.
If the placement type is PickN, check whether the number of clusters that’s requested in the ClusterResourcePlacement policy matches the value of the number-of-clusters label.
How can I find the latest ClusterResourceBinding resource?
The following command lists all ClusterResourceBindings instances that are associated with ClusterResourcePlacement:
kubectl get clusterresourcebinding -l kubernetes-fleet.io/parent-CRP={CRPName}
NOTE: In this command, replace {CRPName} with your ClusterResourcePlacement name.
Example
In this case we have ClusterResourcePlacement called test-crp.
- List the
ClusterResourcePlacement to get the name of the CRP,
kubectl get crp test-crp
NAME GEN SCHEDULED SCHEDULEDGEN APPLIED APPLIEDGEN AGE
test-crp 1 True 1 True 1 15s
- The following command is run to view the status of the
ClusterResourcePlacement deployment.
kubectl describe clusterresourceplacement test-crp
- Here’s an example output. From the
placementStatuses section of the test-crp status, notice that it has distributed
resources to two member clusters and, therefore, has two ClusterResourceBindings instances:
status:
conditions:
- lastTransitionTime: "2023-11-23T00:49:29Z"
...
placementStatuses:
- clusterName: kind-cluster-1
conditions:
...
type: ResourceApplied
- clusterName: kind-cluster-2
conditions:
...
reason: ApplySucceeded
status: "True"
type: ResourceApplied
- To get the
ClusterResourceBindings value, run the following command:
kubectl get clusterresourcebinding -l kubernetes-fleet.io/parent-CRP=test-crp
- The output lists all
ClusterResourceBindings instances that are associated with test-crp.
kubectl get clusterresourcebinding -l kubernetes-fleet.io/parent-CRP=test-crp
NAME WORKCREATED RESOURCESAPPLIED AGE
test-crp-kind-cluster-1-be990c3e True True 33s
test-crp-kind-cluster-2-ec4d953c True True 33s
The ClusterResourceBinding resource name uses the following format: {CRPName}-{clusterName}-{suffix}.
Find the ClusterResourceBinding for the target cluster you are looking for based on the clusterName.
How can I find the latest ClusterResourceSnapshot resource?
To find the latest ClusterResourceSnapshot resource, run the following command:
kubectl get clusterresourcesnapshot -l kubernetes-fleet.io/is-latest-snapshot=true,kubernetes-fleet.io/parent-CRP={CRPName}
NOTE: In this command, replace {CRPName} with your ClusterResourcePlacement name.
How can I find the correct work resource that’s associated with ClusterResourcePlacement?
To find the correct work resource, follow these steps:
- Identify the member cluster namespace and the
ClusterResourcePlacement name. The format for the namespace is fleet-member-{clusterName}. - To get the work resource, run the following command:
kubectl get work -n fleet-member-{clusterName} -l kubernetes-fleet.io/parent-CRP={CRPName}
NOTE: In this command, replace {clusterName} and {CRPName} with the names that you identified in the first step.
5.2 - ResourcePlacement TSG
Identify and fix KubeFleet issues associated with the ResourcePlacement API
This TSG is meant to help you troubleshoot issues with the ResourcePlacement API in Fleet.
Resource Placement
Internal Objects to keep in mind when troubleshooting RP related errors on the hub cluster:
ResourceSnapshotSchedulingPolicySnapshotResourceBindingWork
Please read the Fleet API reference for more details about each object.
Important Considerations for ResourcePlacement
Namespace Prerequisites
Important: ResourcePlacement can only place namespace-scoped resources to clusters that already have the target namespace.
Before creating a ResourcePlacement:
Ensure the target namespace exists on the member clusters, either:
- Created by a
ClusterResourcePlacement (CRP) using namespace-only mode - Pre-existing on the member clusters
If the namespace doesn’t exist on a member cluster, the ResourcePlacement will fail to apply resources to that cluster.
Coordination with ClusterResourcePlacement
When using both ResourcePlacement (RP) and ClusterResourcePlacement (CRP) together:
- CRP in namespace-only mode: Use CRP to create and manage the namespace itself across clusters
- RP for resources: Use RP to manage specific resources within that namespace
- Avoid conflicts: Ensure that CRP and RP don’t select the same resources to prevent conflicts
Resource Scope Limitations
ResourcePlacement can only select and manage namespace-scoped resources within the same namespace where the RP object resides:
- ✅ Supported: ConfigMaps, Secrets, Services, Deployments, StatefulSets, Jobs, etc. within the RP’s namespace
- ❌ Not Supported: Cluster-scoped resources (use ClusterResourcePlacement instead)
- ❌ Not Supported: Resources in other namespaces
Complete Progress of the ResourcePlacement
Understanding the progression and the status of the ResourcePlacement custom resource is crucial for diagnosing and identifying failures.
You can view the status of the ResourcePlacement custom resource by using the following command:
kubectl describe resourceplacement <name> -n <namespace>
The complete progression of ResourcePlacement is as follows:
ResourcePlacementScheduled: Indicates a resource has been scheduled for placement.ResourcePlacementRolloutStarted: Indicates the rollout process has begun.ResourcePlacementOverridden: Indicates the resource has been overridden.ResourcePlacementWorkSynchronized: Indicates the work objects have been synchronized.ResourcePlacementApplied: Indicates the resource has been applied. This condition will only be populated if the
apply strategy in use is of the type ClientSideApply (default) or ServerSideApply.ResourcePlacementAvailable: Indicates the resource is available. This condition will only be populated if the
apply strategy in use is of the type ClientSideApply (default) or ServerSideApply.ResourcePlacementDiffreported: Indicates whether diff reporting has completed on all resources. This condition
will only be populated if the apply strategy in use is of the type ReportDiff.
Note: ResourcePlacement and ClusterResourcePlacement share the same underlying architecture with a 1-to-1 mapping of condition types.
The condition types follow a naming convention where RP conditions use the ResourcePlacement prefix while CRP conditions use the
ClusterResourcePlacement prefix. For example:
ResourcePlacementScheduled ↔ ClusterResourcePlacementScheduledResourcePlacementApplied ↔ ClusterResourcePlacementAppliedResourcePlacementAvailable ↔ ClusterResourcePlacementAvailable
The troubleshooting approaches documented in the CRP TSG files are applicable to ResourcePlacement as well. The main difference is that
ResourcePlacement is namespace-scoped and works with namespace-scoped resources, while ClusterResourcePlacement is cluster-scoped.
When following CRP TSG guidance, substitute the appropriate RP condition names and commands (e.g., use
kubectl get resourceplacement -n <namespace> instead of kubectl get clusterresourceplacement).
How can I debug if some clusters are not selected as expected?
Check the status of the SchedulingPolicySnapshot to determine which clusters were selected along with the reason.
To find the latest SchedulingPolicySnapshot for a ResourcePlacement resource, run the following command:
kubectl get schedulingpolicysnapshot -n <namespace> -l kubernetes-fleet.io/is-latest-snapshot=true,kubernetes-fleet.io/parent-CRP={RPName}
NOTE: In this command, replace {RPName} with your ResourcePlacement name and <namespace> with the namespace where the ResourcePlacement exists.
Then, compare the SchedulingPolicySnapshot with the ResourcePlacement policy to make sure that they match.
How can I debug if a selected cluster does not have the expected resources on it or if RP doesn’t pick up the latest changes?
Please check the following cases,
- Check whether the
ResourcePlacementRolloutStarted condition in ResourcePlacement status is set to true or false. - If
false, the resource placement has not started rolling out yet. - If
true,- Check to see if the overall
ResourcePlacementApplied condition is set to unknown, false or true. - If
unknown, wait for the process to finish, as the resources are still being applied to the member clusters. If the state remains unknown for a while, create an issue, as this is an unusual behavior. - If
false, the resources failed to apply on one or more clusters. Check the Placement Statuses section in the status for cluster-specific details. - If
true, verify that the resource exists on the hub cluster in the same namespace as the ResourcePlacement.
To pinpoint issues on specific clusters, examine the Placement Statuses section in ResourcePlacement status. For each cluster, you can find:
- The cluster name
- Conditions specific to that cluster (e.g.,
Applied, Available) Failed Placements section which lists the resources that failed to apply along with the reasons
How can I debug if the drift detection result or the configuration difference check result are different from my expectations?
See the Drift Detection and Configuration Difference Check Unexpected Result TSG for more information.
How can I find the latest ResourceBinding resource?
The following command lists all ResourceBindings instances that are associated with ResourcePlacement:
kubectl get resourcebinding -n <namespace> -l kubernetes-fleet.io/parent-CRP={RPName}
NOTE: In this command, replace {RPName} with your ResourcePlacement name and <namespace> with the namespace where the ResourcePlacement exists.
Example
In this case we have ResourcePlacement called test-rp in namespace test-ns.
- Get the
ResourcePlacement to get a basic overview of the RP,
kubectl get rp test-rp -n test-ns
NAME GEN SCHEDULED SCHEDULEDGEN AVAILABLE AVAILABLE-GEN AGE
test-rp 1 True 1 True 1 15s
- The following command is run to view the status of the
ResourcePlacement.
kubectl describe resourceplacement test-rp -n test-ns
Here’s an example output:
Status:
Conditions:
Last Transition Time: 2025-11-13T22:25:45Z
Message: found all cluster needed as specified by the scheduling policy, found 2 cluster(s)
Observed Generation: 2
Reason: SchedulingPolicyFulfilled
Status: True
Type: ResourcePlacementScheduled
Last Transition Time: 2025-11-13T22:25:45Z
Message: All 2 cluster(s) start rolling out the latest resource
Observed Generation: 2
Reason: RolloutStarted
Status: True
Type: ResourcePlacementRolloutStarted
Last Transition Time: 2025-11-13T22:25:45Z
Message: No override rules are configured for the selected resources
Observed Generation: 2
Reason: NoOverrideSpecified
Status: True
Type: ResourcePlacementOverridden
Last Transition Time: 2025-11-13T22:25:45Z
Message: Works(s) are succcesfully created or updated in 2 target cluster(s)' namespaces
Observed Generation: 2
Reason: WorkSynchronized
Status: True
Type: ResourcePlacementWorkSynchronized
Last Transition Time: 2025-11-13T22:25:45Z
Message: The selected resources are successfully applied to 2 cluster(s)
Observed Generation: 2
Reason: ApplySucceeded
Status: True
Type: ResourcePlacementApplied
Last Transition Time: 2025-11-13T22:25:45Z
Message: The selected resources in 2 cluster(s) are available now
Observed Generation: 2
Reason: ResourceAvailable
Status: True
Type: ResourcePlacementAvailable
Observed Resource Index: 0
Placement Statuses:
Cluster Name: kind-cluster-1
Conditions:
Last Transition Time: 2025-11-13T22:25:45Z
Message: Successfully scheduled resources for placement in "kind-cluster-1": picked by scheduling policy
Observed Generation: 2
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2025-11-13T22:25:45Z
Message: Detected the new changes on the resources and started the rollout process
Observed Generation: 2
Reason: RolloutStarted
Status: True
Type: RolloutStarted
Last Transition Time: 2025-11-13T22:25:45Z
Message: No override rules are configured for the selected resources
Observed Generation: 2
Reason: NoOverrideSpecified
Status: True
Type: Overridden
Last Transition Time: 2025-11-13T22:25:45Z
Message: All of the works are synchronized to the latest
Observed Generation: 2
Reason: AllWorkSynced
Status: True
Type: WorkSynchronized
Last Transition Time: 2025-11-13T22:25:45Z
Message: All corresponding work objects are applied
Observed Generation: 2
Reason: AllWorkHaveBeenApplied
Status: True
Type: Applied
Last Transition Time: 2025-11-13T22:25:45Z
Message: All corresponding work objects are available
Observed Generation: 2
Reason: AllWorkAreAvailable
Status: True
Type: Available
Observed Resource Index: 0
Cluster Name: kind-cluster-2
Conditions:
Last Transition Time: 2025-11-13T22:25:45Z
Message: Successfully scheduled resources for placement in "kind-cluster-2": picked by scheduling policy
Observed Generation: 2
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2025-11-13T22:25:45Z
Message: Detected the new changes on the resources and started the rollout process
Observed Generation: 2
Reason: RolloutStarted
Status: True
Type: RolloutStarted
Last Transition Time: 2025-11-13T22:25:45Z
Message: No override rules are configured for the selected resources
Observed Generation: 2
Reason: NoOverrideSpecified
Status: True
Type: Overridden
Last Transition Time: 2025-11-13T22:25:45Z
Message: All of the works are synchronized to the latest
Observed Generation: 2
Reason: AllWorkSynced
Status: True
Type: WorkSynchronized
Last Transition Time: 2025-11-13T22:25:45Z
Message: All corresponding work objects are applied
Observed Generation: 2
Reason: AllWorkHaveBeenApplied
Status: True
Type: Applied
Last Transition Time: 2025-11-13T22:25:45Z
Message: All corresponding work objects are available
Observed Generation: 2
Reason: AllWorkAreAvailable
Status: True
Type: Available
Observed Resource Index: 0
Selected Resources:
Kind: ConfigMap
Name: app-config
Namespace: my-app
Version: v1
Kind: ConfigMap
Name: feature-flags
Namespace: my-app
Version: v1
From the status output, you can see:
- Overall Conditions: Show the aggregated state across all clusters (e.g.,
ResourcePlacementApplied, ResourcePlacementAvailable) - Placement Statuses: Contains per-cluster details for
kind-cluster-1 and kind-cluster-2, each with their own conditions (Scheduled, Applied, Available, etc.) - Selected Resources: Lists the ConfigMaps (
app-config and feature-flags) that were selected for placement
- To get the
ResourceBindings, run the following command:
kubectl get resourcebinding -n test-ns -l kubernetes-fleet.io/parent-CRP=test-rp
This lists all ResourceBindings instances that are associated with test-rp.
kubectl get resourcebinding -n test-ns -l kubernetes-fleet.io/parent-CRP=test-rp
NAME WORKSYNCHRONIZED RESOURCESAPPLIED AGE
test-rp-kind-cluster-1-be990c3e True True 33s
test-rp-kind-cluster-2-ec4d953c True True 33s
The ResourceBinding resource name uses the following format: {RPName}-{clusterName}-{suffix}.
Find the ResourceBinding for the target cluster you are looking for based on the clusterName.
How can I find the latest ResourceSnapshot resource?
To find the latest ResourceSnapshot resource, run the following command:
kubectl get resourcesnapshot -n <namespace> -l kubernetes-fleet.io/is-latest-snapshot=true,kubernetes-fleet.io/parent-CRP={RPName}
NOTE: In this command, replace {RPName} with your ResourcePlacement name and <namespace> with the namespace where the ResourcePlacement exists.
How can I find the correct work resource that’s associated with ResourcePlacement?
To find the correct work resource, follow these steps:
- Identify the member cluster namespace and the
ResourcePlacement name. The format for the namespace is fleet-member-{clusterName}. - To get the work resource, run the following command:
kubectl get work -n fleet-member-{clusterName} -l kubernetes-fleet.io/parent-CRP={RPName}
NOTE: In this command, replace {clusterName} and {RPName} with the names that you identified in the first step.
5.3 - Scheduling Failure TSG
Troubleshooting guide for “Scheduled” condition set to false (ClusterResourcePlacementScheduled / ResourcePlacementScheduled)
The ClusterResourcePlacementScheduled (for ClusterResourcePlacement) or ResourcePlacementScheduled (for ResourcePlacement) condition is set to false when the scheduler cannot find all the clusters needed as specified by the scheduling policy.
Note: To get more information about why the scheduling fails, you can check the scheduler logs.
Common scenarios
Instances where this condition may arise:
- When the placement policy is set to
PickFixed, but the specified cluster names do not match any joined member cluster name in the fleet, or the specified cluster is no longer connected to the fleet. - When the placement policy is set to
PickN, and N clusters are specified, but there are fewer than N clusters that have joined the fleet or satisfy the placement policy. - When the placement resource selector selects a reserved namespace.
Note: When the placement policy is set to PickAll, the ClusterResourcePlacementScheduled or ResourcePlacementScheduled condition is always set to True.
Case Study
In the following example, a ClusterResourcePlacement with a PickN placement policy is trying to propagate resources to two clusters labeled env:prod. (The same scheduling logic applies to ResourcePlacement.)
The two clusters, named kind-cluster-1 and kind-cluster-2, have joined the fleet. However, only one member cluster, kind-cluster-1, has the label env:prod.
CRP spec
spec:
policy:
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
numberOfClusters: 2
placementType: PickN
resourceSelectors:
...
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
ClusterResourcePlacement status
status:
conditions:
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: could not find all the clusters needed as specified by the scheduling
policy
observedGeneration: 1
reason: SchedulingPolicyUnfulfilled
status: "False"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: All 1 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: Works(s) are succcesfully created or updated in the 1 target clusters'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: The selected resources are successfully applied to 1 clusters
observedGeneration: 1
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: The selected resources in 1 cluster are available now
observedGeneration: 1
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
observedResourceIndex: "0"
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: All corresponding work objects are available
observedGeneration: 1
reason: AllWorkAreAvailable
status: "True"
type: Available
- conditions:
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: 'kind-cluster-2 is not selected: ClusterUnschedulable, cluster does not
match with any of the required cluster affinity terms'
observedGeneration: 1
reason: ScheduleFailed
status: "False"
type: Scheduled
selectedResources:
...
The ClusterResourcePlacementScheduled condition is set to false, the goal is to select two clusters with the label env:prod, but only one member cluster possesses the correct label as specified in clusterAffinity.
We can also take a look at the ClusterSchedulingPolicySnapshot status to figure out why the scheduler could not schedule the resource for the placement policy specified.
To learn how to get the latest ClusterSchedulingPolicySnapshot, see How can I find and verify the latest ClusterSchedulingPolicySnapshot for a ClusterResourcePlacement deployment? to learn how to get the latest ClusterSchedulingPolicySnapshot.
- For ResourcePlacement: use
SchedulingPolicySnapshot.
The corresponding ClusterSchedulingPolicySnapshot spec and status gives us even more information on why scheduling failed.
Latest ClusterSchedulingPolicySnapshot
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterSchedulingPolicySnapshot
metadata:
annotations:
kubernetes-fleet.io/CRP-generation: "1"
kubernetes-fleet.io/number-of-clusters: "2"
creationTimestamp: "2024-05-07T22:36:33Z"
generation: 1
labels:
kubernetes-fleet.io/is-latest-snapshot: "true"
kubernetes-fleet.io/parent-CRP: crp-2
kubernetes-fleet.io/policy-index: "0"
name: crp-2-0
ownerReferences:
- apiVersion: placement.kubernetes-fleet.io/v1beta1
blockOwnerDeletion: true
controller: true
kind: ClusterResourcePlacement
name: crp-2
uid: 48bc1e92-a8b9-4450-a2d5-c6905df2cbf0
resourceVersion: "10090"
uid: 2137887e-45fd-4f52-bbb7-b96f39854625
spec:
policy:
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: prod
placementType: PickN
policyHash: ZjE0Yjk4YjYyMTVjY2U3NzQ1MTZkNWRhZjRiNjQ1NzQ4NjllNTUyMzZkODBkYzkyYmRkMGU3OTI3MWEwOTkyNQ==
status:
conditions:
- lastTransitionTime: "2024-05-07T22:36:33Z"
message: could not find all the clusters needed as specified by the scheduling
policy
observedGeneration: 1
reason: SchedulingPolicyUnfulfilled
status: "False"
type: Scheduled
observedCRPGeneration: 1
targetClusters:
- clusterName: kind-cluster-1
clusterScore:
affinityScore: 0
priorityScore: 0
reason: picked by scheduling policy
selected: true
- clusterName: kind-cluster-2
reason: ClusterUnschedulable, cluster does not match with any of the required
cluster affinity terms
selected: false
Resolution
The solution here is to add the env:prod label to the member cluster resource for kind-cluster-2 as well, so that the scheduler can select the cluster to propagate resources.
General Notes
The scheduling failure investigation flow is identical for ClusterResourcePlacement and ResourcePlacement; only the snapshot object kind differs. Replace CRP-specific object kinds with their RP equivalents when working with namespace-scoped placements.
5.4 - Rollout Failure TSG
Troubleshooting guide for “RolloutStarted” condition set to false (ClusterResourcePlacementRolloutStarted / ResourcePlacementRolloutStarted)
When using placement APIs (ClusterResourcePlacement or ResourcePlacement) to propagate resources, selected resources may not begin rolling out and the ClusterResourcePlacementRolloutStarted (for ClusterResourcePlacement) or ResourcePlacementRolloutStarted (for ResourcePlacement) condition shows False.
This TSG only applies to the RollingUpdate rollout strategy, which is the default strategy if you don’t specify in the ClusterResourcePlacement.
To troubleshoot the update run strategy as you specify External in the ClusterResourcePlacement, please refer to the Staged Update Run Troubleshooting Guide.
Note: To get more information about why the rollout doesn’t start, you can check the rollout controller to get more information on why the rollout did not start.
Common scenarios
Instances where this condition may arise:
- The rollout strategy is blocked because the
RollingUpdate configuration is too strict.
Troubleshooting Steps
- In the
ClusterResourcePlacement or ResourcePlacement status section, check the placementStatuses to identify clusters with the RolloutStarted status set to False. - Locate the corresponding
ClusterResourceBinding or ResourceBinding for the identified cluster. For more information, see How can I find the latest ClusterResourceBinding resource? or How can I find the latest ResourceBinding resource?.
This resource should indicate the status of the Work whether it was created or updated. - Verify the values of
maxUnavailable and maxSurge to ensure they align with your expectations.
Case Study
In the following example, the ClusterResourcePlacement is trying to propagate a namespace to three member clusters.
However, during the initial creation of the ClusterResourcePlacement, the namespace didn’t exist on the hub cluster,
and the fleet currently comprises two member clusters named kind-cluster-1 and kind-cluster-2.
ClusterResourcePlacement spec
spec:
policy:
numberOfClusters: 3
placementType: PickN
resourceSelectors:
- group: ""
kind: Namespace
name: test-ns
version: v1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
ClusterResourcePlacement status
status:
conditions:
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: could not find all the clusters needed as specified by the scheduling
policy
observedGeneration: 1
reason: SchedulingPolicyUnfulfilled
status: "False"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All 2 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: Works(s) are succcesfully created or updated in the 2 target clusters'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: The selected resources are successfully applied to 2 clusters
observedGeneration: 1
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: The selected resources in 2 cluster are available now
observedGeneration: 1
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
observedResourceIndex: "0"
placementStatuses:
- clusterName: kind-cluster-2
conditions:
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: 'Successfully scheduled resources for placement in kind-cluster-2 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All corresponding work objects are available
observedGeneration: 1
reason: AllWorkAreAvailable
status: "True"
type: Available
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All corresponding work objects are available
observedGeneration: 1
reason: AllWorkAreAvailable
status: "True"
type: Available
The previous output indicates that the resource test-ns namespace never exists on the hub cluster and shows the following ClusterResourcePlacement condition statuses:
ClusterResourcePlacementScheduled is set to False, as the specified policy aims to pick three clusters, but the scheduler can only accommodate placement in two currently available and joined clusters.ClusterResourcePlacementRolloutStarted is set to True, as the rollout process has commenced with 2 clusters being selected.ClusterResourcePlacementOverridden is set to True, as no override rules are configured for the selected resources.ClusterResourcePlacementWorkSynchronized is set to True.ClusterResourcePlacementApplied is set to True.ClusterResourcePlacementAvailable is set to True.
To ensure seamless propagation of the namespace across the relevant clusters, proceed to create the test-ns namespace on the hub cluster.
ClusterResourcePlacement status after namespace test-ns is created on the hub cluster
status:
conditions:
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: could not find all the clusters needed as specified by the scheduling
policy
observedGeneration: 1
reason: SchedulingPolicyUnfulfilled
status: "False"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-05-07T23:13:51Z"
message: The rollout is being blocked by the rollout strategy in 2 cluster(s)
observedGeneration: 1
reason: RolloutNotStartedYet
status: "False"
type: ClusterResourcePlacementRolloutStarted
observedResourceIndex: "1"
placementStatuses:
- clusterName: kind-cluster-2
conditions:
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: 'Successfully scheduled resources for placement in kind-cluster-2 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-07T23:13:51Z"
message: The rollout is being blocked by the rollout strategy
observedGeneration: 1
reason: RolloutNotStartedYet
status: "False"
type: RolloutStarted
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-07T23:13:51Z"
message: The rollout is being blocked by the rollout strategy
observedGeneration: 1
reason: RolloutNotStartedYet
status: "False"
type: RolloutStarted
selectedResources:
- kind: Namespace
name: test-ns
version: v1
Upon examination, the ClusterResourcePlacementScheduled condition status is shown as False.
The ClusterResourcePlacementRolloutStarted status is also shown as False with the message The rollout is being blocked by the rollout strategy in 2 cluster(s).
Let’s check the latest ClusterResourceSnapshot.
Check the latest ClusterResourceSnapshot by running the command in How can I find the latest ClusterResourceSnapshot resource?.
Latest ClusterResourceSnapshot
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourceSnapshot
metadata:
annotations:
kubernetes-fleet.io/number-of-enveloped-object: "0"
kubernetes-fleet.io/number-of-resource-snapshots: "1"
kubernetes-fleet.io/resource-hash: 72344be6e268bc7af29d75b7f0aad588d341c228801aab50d6f9f5fc33dd9c7c
creationTimestamp: "2024-05-07T23:13:51Z"
generation: 1
labels:
kubernetes-fleet.io/is-latest-snapshot: "true"
kubernetes-fleet.io/parent-CRP: crp-3
kubernetes-fleet.io/resource-index: "1"
name: crp-3-1-snapshot
ownerReferences:
- apiVersion: placement.kubernetes-fleet.io/v1beta1
blockOwnerDeletion: true
controller: true
kind: ClusterResourcePlacement
name: crp-3
uid: b4f31b9a-971a-480d-93ac-93f093ee661f
resourceVersion: "14434"
uid: 85ee0e81-92c9-4362-932b-b0bf57d78e3f
spec:
selectedResources:
- apiVersion: v1
kind: Namespace
metadata:
labels:
kubernetes.io/metadata.name: test-ns
name: test-ns
spec:
finalizers:
- kubernetes
Upon inspecting ClusterResourceSnapshot spec, the selectedResources section now shows the namespace test-ns.
Let’s check the ClusterResourceBinding for kind-cluster-1 to see if it was updated after the namespace test-ns was created.
Check the ClusterResourceBinding for kind-cluster-1 by running the command in How can I find the latest ClusterResourceBinding resource?.
ClusterResourceBinding for kind-cluster-1
apiVersion: placement.kubernetes-fleet.io/v1
kind: ClusterResourceBinding
metadata:
creationTimestamp: "2024-05-07T23:08:53Z"
finalizers:
- kubernetes-fleet.io/work-cleanup
generation: 2
labels:
kubernetes-fleet.io/parent-CRP: crp-3
name: crp-3-kind-cluster-1-7114c253
resourceVersion: "14438"
uid: 0db4e480-8599-4b40-a1cc-f33bcb24b1a7
spec:
applyStrategy:
type: ClientSideApply
clusterDecision:
clusterName: kind-cluster-1
clusterScore:
affinityScore: 0
priorityScore: 0
reason: picked by scheduling policy
selected: true
resourceSnapshotName: crp-3-0-snapshot
schedulingPolicySnapshotName: crp-3-0
state: Bound
targetCluster: kind-cluster-1
status:
conditions:
- lastTransitionTime: "2024-05-07T23:13:51Z"
message: The resources cannot be updated to the latest because of the rollout
strategy
observedGeneration: 2
reason: RolloutNotStartedYet
status: "False"
type: RolloutStarted
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: No override rules are configured for the selected resources
observedGeneration: 2
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All of the works are synchronized to the latest
observedGeneration: 2
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All corresponding work objects are applied
observedGeneration: 2
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-05-07T23:08:53Z"
message: All corresponding work objects are available
observedGeneration: 2
reason: AllWorkAreAvailable
status: "True"
type: Available
Upon inspection, it is observed that the ClusterResourceBinding remains unchanged. Notably, in the spec, the resourceSnapshotName still references the old ClusterResourceSnapshot name.
This issue arises due to the absence of explicit rollingUpdate input from the user. Consequently, the default values are applied:
- The
maxUnavailable value is configured to 25% x 3 (desired number), rounded to 1 - The
maxSurge value is configured to 25% x 3 (desired number), rounded to 1
Why ClusterResourceBinding isn’t updated?
Initially, when the ClusterResourcePlacement was created, two ClusterResourceBindings were generated.
However, since the rollout didn’t apply to the initial phase, the ClusterResourcePlacementRolloutStarted condition was set to True.
Upon creating the test-ns namespace on the hub cluster, the rollout controller attempted to update the two existing ClusterResourceBindings.
However, maxUnavailable was set to 1 due to the lack of member clusters, which caused the RollingUpdate configuration to be too strict.
NOTE: During the update, if one of the bindings fails to apply, it will also violate the RollingUpdate configuration, which causes maxUnavailable to be set to 1.
Resolution
In this situation, to address this issue, consider manually setting maxUnavailable to a value greater than 1 to relax the RollingUpdate configuration.
Alternatively, you can join a third member cluster.
General Notes
The rollout failure investigation flow is identical for ClusterResourcePlacement and ResourcePlacement; only the snapshot object kind differs. Replace CRP-specific object kinds with their RP equivalents when working with namespace-scoped placements.
5.5 - Override Failure TSG
Troubleshooting guide for “Overridden” condition set to false (ClusterResourcePlacementOverridden / ResourcePlacementOverridden)
The ClusterResourcePlacementOverridden (CRP) or ResourcePlacementOverridden (RP) condition is False when an override operation fails.
Note: To get more information, look into the logs for the overrider controller (includes
controller for ClusterResourceOverride and
ResourceOverride).
Common scenarios
Instances where this condition may arise:
- The
ClusterResourceOverride or ResourceOverride is created with an invalid field path for the resource.
Case Study
In the following example, an attempt is made to override the cluster role secret-reader that is being propagated by the ClusterResourcePlacement to the selected clusters.
However, the ClusterResourceOverride is created with an invalid path for the field within resource.
ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
creationTimestamp: "2024-05-14T15:36:48Z"
name: secret-reader
resourceVersion: "81334"
uid: 108e6312-3416-49be-aa3d-a665c5df58b4
rules:
- apiGroups:
- ""
resources:
- secrets
verbs:
- get
- watch
- list
The ClusterRole secret-reader that is being propagated to the member clusters by the ClusterResourcePlacement.
ClusterResourceOverride spec
spec:
clusterResourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
name: secret-reader
version: v1
policy:
overrideRules:
- clusterSelector:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: canary
jsonPatchOverrides:
- op: add
path: /metadata/labels/new-label
value: new-value
The ClusterResourceOverride is created to override the ClusterRole secret-reader by adding a new label (new-label)
that has the value new-value for the clusters with the label env: canary.
ClusterResourcePlacement Spec
spec:
resourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
name: secret-reader
version: v1
policy:
placementType: PickN
numberOfClusters: 1
affinity:
clusterAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
clusterSelectorTerms:
- labelSelector:
matchLabels:
env: canary
strategy:
type: RollingUpdate
applyStrategy:
allowCoOwnership: true
ClusterResourcePlacement Status
status:
conditions:
- lastTransitionTime: "2024-05-14T16:16:18Z"
message: found all cluster needed as specified by the scheduling policy, found
1 cluster(s)
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-05-14T16:16:18Z"
message: All 1 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-05-14T16:16:18Z"
message: Failed to override resources in 1 cluster(s)
observedGeneration: 1
reason: OverriddenFailed
status: "False"
type: ClusterResourcePlacementOverridden
observedResourceIndex: "0"
placementStatuses:
- applicableClusterResourceOverrides:
- cro-1-0
clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-05-14T16:16:18Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-14T16:16:18Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-05-14T16:16:18Z"
message: 'Failed to apply the override rules on the resources: add operation
does not apply: doc is missing path: "/metadata/labels/new-label": missing
value'
observedGeneration: 1
reason: OverriddenFailed
status: "False"
type: Overridden
selectedResources:
- group: rbac.authorization.k8s.io
kind: ClusterRole
name: secret-reader
version: v1
The CRP attempted to override a propagated resource utilizing an applicable ClusterResourceOverrideSnapshot.
However, as the ClusterResourcePlacementOverridden condition remains false, looking at the placement status for the cluster
where the condition ClusterResourcePlacementOverridden (for ClusterResourcePlacement) or ResourcePlacementOverridden (for ResourcePlacement) failed will offer insights into the exact cause of the failure.
In this situation, the message indicates that the override failed because the path /metadata/labels/new-label and its corresponding value are missing.
Based on the previous example of the cluster role secret-reader, you can see that the path /metadata/labels/ doesn’t exist. This means that labels doesn’t exist.
Therefore, a new label can’t be added.
Resolution
To successfully override the cluster role secret-reader, correct the path and value in ClusterResourceOverride, as shown in the following code:
jsonPatchOverrides:
- op: add
path: /metadata/labels
value:
newlabel: new-value
This will successfully add the new label newlabel with the value new-value to the ClusterRole secret-reader, as we are creating the labels field and adding a new value newlabel: new-value to it.
General Notes
For ResourcePlacement the override flow is identical except that all the resources reside in the same namespace; use ResourceOverride instead of ClusterResourceOverride and expect ResourcePlacementOverridden in conditions.
5.6 - Work Synchronization Failure TSG
Troubleshooting guide for “WorkSynchronized” condition set to false (ClusterResourcePlacementWorkSynchronized / ResourcePlacementWorkSynchronized)
The ClusterResourcePlacementWorkSynchronized (CRP) or ResourcePlacementWorkSynchronized (RP) condition is False when the placement has been recently updated but the associated Work objects have not yet been synchronized with the latest selected resources.
Note: In addition, it may be helpful to look into the logs for the work generator controller to get more information on why the work synchronization failed.
Common Scenarios
Instances where this condition may arise:
- The controller encounters an error while trying to generate the corresponding
work object. - The enveloped object is not well formatted.
Case Study
The CRP is attempting to propagate a resource to a selected cluster, but the work object has not been updated to reflect the latest changes due to the selected cluster has been terminated.
ClusterResourcePlacement Spec
spec:
resourceSelectors:
- group: rbac.authorization.k8s.io
kind: ClusterRole
name: secret-reader
version: v1
policy:
placementType: PickN
numberOfClusters: 1
strategy:
type: RollingUpdate
ClusterResourcePlacement Status
spec:
policy:
numberOfClusters: 1
placementType: PickN
resourceSelectors:
- group: ""
kind: Namespace
name: test-ns
version: v1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
status:
conditions:
- lastTransitionTime: "2024-05-14T18:05:04Z"
message: found all cluster needed as specified by the scheduling policy, found
1 cluster(s)
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-05-14T18:05:05Z"
message: All 1 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-05-14T18:05:05Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-05-14T18:05:05Z"
message: There are 1 cluster(s) which have not finished creating or updating work(s)
yet
observedGeneration: 1
reason: WorkNotSynchronizedYet
status: "False"
type: ClusterResourcePlacementWorkSynchronized
observedResourceIndex: "0"
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-05-14T18:05:04Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-14T18:05:05Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-05-14T18:05:05Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-05-14T18:05:05Z"
message: 'Failed to synchronize the work to the latest: works.placement.kubernetes-fleet.io
"crp1-work" is forbidden: unable to create new content in namespace fleet-member-kind-cluster-1
because it is being terminated'
observedGeneration: 1
reason: SyncWorkFailed
status: "False"
type: WorkSynchronized
selectedResources:
- kind: Namespace
name: test-ns
version: v1
In the ClusterResourcePlacement status, the ClusterResourcePlacementWorkSynchronized condition status shows as False.
The message for it indicates that the work object crp1-work is prohibited from generating new content within the namespace fleet-member-kind-cluster-1 because it’s currently terminating.
Resolution
To address the issue at hand, there are several potential solutions:
- Modify the
ClusterResourcePlacement with a newly selected cluster. - Delete the
ClusterResourcePlacement to remove work through garbage collection. - Rejoin the member cluster. The namespace can only be regenerated after rejoining the cluster.
In other situations, you might opt to wait for the work to finish propagating.
General Notes
For ResourcePlacement the investigation is identical — inspect .status.placementStatuses[*].conditions for WorkSynchronized and check the associated Work in the fleet-member-{clusterName} namespace.
5.7 - Work-Application Failure TSG
Troubleshooting guide for “Applied” condition set to false
The ClusterResourcePlacementApplied (for ClusterResourcePlacement) or ResourcePlacementApplied (for ResourcePlacement) condition is set to false when the deployment fails to apply.
Note: To get more information about why the resources are not applied, you can check the work applier logs.
Common scenarios
Instances where this condition may arise:
- The resource already exists on the cluster and isn’t managed by the fleet controller.
- Another placement (ClusterResourcePlacement or ResourcePlacement) is already managing the resource for the selected cluster by using a different apply strategy.
- The placement doesn’t apply the manifest because of syntax errors or invalid resource configurations. This might also occur if a resource is propagated through an envelope object.
Investigation steps
- Check
placementStatuses: In the placement status section, inspect the placementStatuses to identify which clusters have the ClusterResourcePlacementApplied (for ClusterResourcePlacement) or ResourcePlacementApplied (for ResourcePlacement) condition set to false and note down their clusterName. - Locate the
Work Object in Hub Cluster: Use the identified clusterName to locate the Work object associated with the member cluster. - Check
Work object status: Inspect the status of the Work object to understand the specific issues preventing successful resource application.
Case Study: ClusterResourcePlacement
In the following example, a ClusterResourcePlacement is trying to propagate a namespace that contains a deployment to two member clusters. However, the namespace already exists on one member cluster, specifically kind-cluster-1.
ClusterResourcePlacement spec
policy:
clusterNames:
- kind-cluster-1
- kind-cluster-2
placementType: PickFixed
resourceSelectors:
- group: ""
kind: Namespace
name: test-ns
version: v1
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
ClusterResourcePlacement status
status:
conditions:
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: could not find all the clusters needed as specified by the scheduling
policy
observedGeneration: 1
reason: SchedulingPolicyUnfulfilled
status: "False"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: All 2 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: Works(s) are succcesfully created or updated in the 2 target clusters'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: Failed to apply resources to 1 clusters, please check the `failedPlacements`
status
observedGeneration: 1
reason: ApplyFailed
status: "False"
type: ClusterResourcePlacementApplied
observedResourceIndex: "0"
placementStatuses:
- clusterName: kind-cluster-2
conditions:
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: 'Successfully scheduled resources for placement in kind-cluster-2 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-05-07T23:32:49Z"
message: The availability of work object crp-4-work is not trackable
observedGeneration: 1
reason: WorkNotTrackable
status: "True"
type: Available
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: Work object crp-4-work is not applied
observedGeneration: 1
reason: NotAllWorkHaveBeenApplied
status: "False"
type: Applied
failedPlacements:
- condition:
lastTransitionTime: "2024-05-07T23:32:40Z"
message: 'Failed to apply manifest: failed to process the request due to a
client error: resource exists and is not managed by the fleet controller
and co-ownernship is disallowed'
reason: ManifestsAlreadyOwnedByOthers
status: "False"
type: Applied
kind: Namespace
name: test-ns
version: v1
selectedResources:
- kind: Namespace
name: test-ns
version: v1
- group: apps
kind: Deployment
name: test-nginx
namespace: test-ns
version: v1
In the ClusterResourcePlacement status, within the failedPlacements section for kind-cluster-1, we get a clear message
as to why the resource failed to apply on the member cluster. In the preceding conditions section,
the ClusterResourcePlacementApplied condition for kind-cluster-1 is flagged as false and shows the NotAllWorkHaveBeenApplied reason.
This indicates that the Work object intended for the member cluster kind-cluster-1 has not been applied.
To inspect the Work object for more details, follow the steps in the Investigation steps section above.
Work status of kind-cluster-1
status:
conditions:
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: 'Apply manifest {Ordinal:0 Group: Version:v1 Kind:Namespace Resource:namespaces
Namespace: Name:test-ns} failed'
observedGeneration: 1
reason: WorkAppliedFailed
status: "False"
type: Applied
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: ""
observedGeneration: 1
reason: WorkAppliedFailed
status: Unknown
type: Available
manifestConditions:
- conditions:
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: 'Failed to apply manifest: failed to process the request due to a client
error: resource exists and is not managed by the fleet controller and co-ownernship
is disallowed'
reason: ManifestsAlreadyOwnedByOthers
status: "False"
type: Applied
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: Manifest is not applied yet
reason: ManifestApplyFailed
status: Unknown
type: Available
identifier:
kind: Namespace
name: test-ns
ordinal: 0
resource: namespaces
version: v1
- conditions:
- lastTransitionTime: "2024-05-07T23:32:40Z"
message: Manifest is already up to date
observedGeneration: 1
reason: ManifestAlreadyUpToDate
status: "True"
type: Applied
- lastTransitionTime: "2024-05-07T23:32:51Z"
message: Manifest is trackable and available now
observedGeneration: 1
reason: ManifestAvailable
status: "True"
type: Available
identifier:
group: apps
kind: Deployment
name: test-nginx
namespace: test-ns
ordinal: 1
resource: deployments
version: v1
From looking at the Work status, specifically the manifestConditions section, you can see that the namespace could not be applied but the deployment within the namespace got propagated from the hub to the member cluster.
Resolution
In this situation, a potential solution is to set the AllowCoOwnership to true in the ApplyStrategy policy. However, it’s important to notice that this decision should be made by the user because the resources might not be shared.
General Troubleshooting Notes
The troubleshooting process and Work object inspection are identical for both ClusterResourcePlacement and ResourcePlacement:
- Both use the same underlying Work API to apply resources to member clusters
- The Work object status and manifestConditions have the same structure regardless of whether they were created by a ClusterResourcePlacement or ResourcePlacement
- The main difference is the scope: ClusterResourcePlacement is cluster-scoped and can select both cluster-scoped and namespace-scoped resources, while ResourcePlacement is namespace-scoped and can only select namespace-scoped resources within its own namespace
For ResourcePlacement-specific considerations:
- Ensure the target namespace exists on member clusters before the ResourcePlacement tries to apply resources to it
- ResourcePlacement can only select resources within the same namespace where the ResourcePlacement object itself resides
5.8 - Availability Failure TSG
Troubleshooting guide for “Available” condition set to false
The ClusterResourcePlacementAvailable (for ClusterResourcePlacement) or ResourcePlacementAvailable (for ResourcePlacement) condition is false when some of the resources are not available yet. Detailed failures are placed in the failedPlacements section of the placement status.
Note: To get more information about why resources are unavailable check work applier logs.
Common scenarios
Instances where this condition may arise:
- The member cluster doesn’t have enough resource availability.
- The deployment contains an invalid image name.
- Required resources (such as persistent volumes, config maps, or secrets) are missing.
- Resource quotas or limit ranges are preventing the resource from becoming available.
Case Study: ClusterResourcePlacement
The example output below demonstrates a scenario where a ClusterResourcePlacement is unable to propagate a deployment to a member cluster due to the deployment having a bad image name.
ClusterResourcePlacement spec
spec:
resourceSelectors:
- group: ""
kind: Namespace
name: test-ns
version: v1
policy:
placementType: PickN
numberOfClusters: 1
strategy:
type: RollingUpdate
ClusterResourcePlacement status
status:
conditions:
- lastTransitionTime: "2024-05-14T18:52:30Z"
message: found all cluster needed as specified by the scheduling policy, found
1 cluster(s)
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: All 1 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: Works(s) are succcesfully created or updated in 1 target cluster(s)'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: The selected resources are successfully applied to 1 cluster(s)
observedGeneration: 1
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: The selected resources in 1 cluster(s) are still not available yet
observedGeneration: 1
reason: ResourceNotAvailableYet
status: "False"
type: ClusterResourcePlacementAvailable
observedResourceIndex: "0"
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2024-05-14T18:52:30Z"
message: 'Successfully scheduled resources for placement in kind-cluster-1 (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: Work object crp1-work is not available
observedGeneration: 1
reason: NotAllWorkAreAvailable
status: "False"
type: Available
failedPlacements:
- condition:
lastTransitionTime: "2024-05-14T18:52:31Z"
message: Manifest is trackable but not available yet
observedGeneration: 1
reason: ManifestNotAvailableYet
status: "False"
type: Available
group: apps
kind: Deployment
name: my-deployment
namespace: test-ns
version: v1
selectedResources:
- kind: Namespace
name: test-ns
version: v1
- group: apps
kind: Deployment
name: my-deployment
namespace: test-ns
version: v1
In the ClusterResourcePlacement status, within the failedPlacements section for kind-cluster-1, we get a clear message
as to why the resource is not available on the member cluster. In the preceding conditions section,
the ClusterResourcePlacementAvailable condition for kind-cluster-1 is flagged as false and shows NotAllWorkAreAvailable reason.
This signifies that the Work object intended for the member cluster kind-cluster-1 is not yet available.
For more information on finding the correct Work resource:
Work status of kind-cluster-1
status:
conditions:
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: Work is applied successfully
observedGeneration: 1
reason: WorkAppliedCompleted
status: "True"
type: Applied
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: Manifest {Ordinal:1 Group:apps Version:v1 Kind:Deployment Resource:deployments
Namespace:test-ns Name:my-deployment} is not available yet
observedGeneration: 1
reason: WorkNotAvailableYet
status: "False"
type: Available
manifestConditions:
- conditions:
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: Manifest is already up to date
reason: ManifestAlreadyUpToDate
status: "True"
type: Applied
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: Manifest is trackable and available now
reason: ManifestAvailable
status: "True"
type: Available
identifier:
kind: Namespace
name: test-ns
ordinal: 0
resource: namespaces
version: v1
- conditions:
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: Manifest is already up to date
observedGeneration: 1
reason: ManifestAlreadyUpToDate
status: "True"
type: Applied
- lastTransitionTime: "2024-05-14T18:52:31Z"
message: Manifest is trackable but not available yet
observedGeneration: 1
reason: ManifestNotAvailableYet
status: "False"
type: Available
identifier:
group: apps
kind: Deployment
name: my-deployment
namespace: test-ns
ordinal: 1
resource: deployments
version: v1
Check the Available status for kind-cluster-1. You can see that the my-deployment deployment isn’t yet available on the member cluster.
This suggests that an issue might be affecting the deployment manifest.
Resolution
In this situation, a potential solution is to check the deployment in the member cluster because the message indicates that the root cause of the issue is a bad image name.
After this image name is identified, you can correct the deployment manifest and update it.
After you fix and update the resource manifest, the placement object (ClusterResourcePlacement or ResourcePlacement) automatically propagates the corrected resource to the member cluster.
For all other situations, make sure that the propagated resource is configured correctly.
Additionally, verify that the selected cluster has sufficient available capacity to accommodate the new resources.
General Troubleshooting Notes
The troubleshooting process and Work object inspection are identical for both ClusterResourcePlacement and ResourcePlacement:
- Both use the same underlying Work API to apply resources to member clusters
- The Work object status and manifestConditions have the same structure regardless of whether they were created by a ClusterResourcePlacement or ResourcePlacement
- The
Available condition in the Work status indicates whether the applied resources have become available on the member cluster - The main difference is the scope: ClusterResourcePlacement is cluster-scoped and can select both cluster-scoped and namespace-scoped resources, while ResourcePlacement is namespace-scoped and can only select namespace-scoped resources within its own namespace
5.9 - CRP Drift Detection and Configuration Difference Check Unexpected Result TSG
Troubleshoot situations where CRP drift detection and configuration difference check features are returning unexpected results
This document helps you troubleshoot unexpected drift and configuration difference
detection results when using the KubeFleet CRP API.
Note
If you are looking for troubleshooting steps on diff reporting failures, i.e., when
the ClusterResourcePlacementDiffReported or ResourcePlacementDiffReported condition on your placement object is set to
False, see the Diff Reporting Failure TSG
instead.
Note
This document focuses on unexpected drift and configuration difference detection
results. If you have encountered drift and configuration difference detection
failures (e.g., no detection results at all with the ClusterResourcePlacementApplied
condition being set to False with a detection related error), see the
Work-Application Failure TSG instead.
Common scenarios
A drift occurs when a non-KubeFleet agent modifies a KubeFleet-managed resource (i.e.,
a resource that has been applied by KubeFleet). Drift details are reported in the CRP status
on a per-cluster basis (.status.placementStatuses[*].driftedPlacements field).
Drift detection is always on when your CRP uses a ClientSideApply (default) or
ServerSideApply typed apply strategy, however, note the following limitations:
- When you set the
comparisonOption setting (.spec.strategy.applyStrategy.comparisonOption field)
to partialComparison, KubeFleet will only detect drifts in managed fields, i.e., fields
that have been explicitly specified on the hub cluster side. A non-KubeFleet agent can then
add a field (e.g., a label or an annotation) to the resource without KubeFleet complaining about it.
To check for such changes (field additions), use the fullComparison option for the comparisonOption field. - Depending on your cluster setup, there might exist Kubernetes webhooks/controllers (built-in or from a
third party) that will process KubeFleet-managed resources and add/modify fields as they see fit.
The API server on the member cluster side might also add/modify fields (e.g., enforcing default values)
on resources. If your comparison option allows, KubeFleet will report these as drifts. For
any unexpected drift reportings, verify first if you have installed a source that triggers the changes.
- When you set the
whenToApply setting (.spec.strategy.applyStrategy.whenToApply field)
to Always and the comparisonOption setting (.spec.strategy.applyStrategy.comparisonOption field)
to partialComparison, no drifts will ever be found, as apply ops from KubeFleet will
overwrite any drift in managed fields, and drifts in unmanaged fields are always ignored. - Drift detection does not apply to resources that are not yet managed by KubeFleet. If a resource has
not been created on the hub cluster or has not been selected by the CRP API, there will not be any drift
reportings about it, even if the resource live within a KubeFleet managed namespace. Similarly, if KubeFleet
has been blocked from taking over a pre-existing resource due to your takeover setting
(
.spec.strategy.applyStrategy.whenToTakeOver field), no drift detection will run on the resource. - Resource deletion is not considered as a drift; if a KubeFleet-managed resource has been deleted
by a non-KubeFleet agent, KubeFleet will attempt to re-create it as soon as it finds out about the
deletion.
- Drift detection will not block resource rollouts. If you have just updated the resources on
the hub cluster side and triggered a rollout, drifts on the member cluster side might have been
overwritten.
- When a rollout is in progress, drifts will not be reported on the CRP status for a member cluster if
the cluster has not received the latest round of updates.
KubeFleet will check for configuration differences under the following two conditions:
- When KubeFleet encounters a pre-existing resource, and the
whenToTakeOver setting
(.spec.strategy.applyStrategy.whenToTakeOver field) is set to IfNoDiff. - When the CRP uses an apply strategy of the
ReportDiff type.
Configuration difference details are reported in the CRP status
on a per-cluster basis (.status.placementStatuses[*].diffedPlacements field). Note that the
following limitations apply:
- When you set the
comparisonOption setting (.spec.strategy.applyStrategy.comparisonOption field)
to partialComparison, KubeFleet will only check for configuration differences in managed fields,
i.e., fields that have been explicitly specified on the hub cluster side. Unmanaged fields, such
as additional labels and annotations, will not be considered as configuration differences.
To check for such changes (field additions), use the fullComparison option for the comparisonOption field. - Depending on your cluster setup, there might exist Kubernetes webhooks/controllers (built-in or from a
third party) that will process resources and add/modify fields as they see fit.
The API server on the member cluster side might also add/modify fields (e.g., enforcing default values)
on resources. If your comparison option allows, KubeFleet will report these as configuration differences.
For any unexpected configuration difference reportings, verify first if you have installed a source that
triggers the changes.
- KubeFleet checks for configuration differences regardless of resource ownerships; resources not
managed by KubeFleet will also be checked.
- The absence of a resource will be considered as a configuration difference.
- Configuration differences will not block resource rollouts. If you have just updated the resources on
the hub cluster side and triggered a rollout, configuration difference check will be re-run based on the
newer versions of resources.
- When a rollout is in progress, configuration differences will not be reported on the CRP status
for a member cluster if the cluster has not received the latest round of updates.
Note also that drift detection and configuration difference check in KubeFleet run periodically.
The reportings in the CRP status might not be up-to-date.
Investigation steps
If you find an unexpected drift detection or configuration difference check result on a member cluster,
follow the steps below for investigation:
- Double-check the apply strategy of your CRP; confirm that your settings allows proper drift detection
and/or configuration difference check reportings.
- Verify that rollout has completed on all member clusters; see the CRP Rollout Failure TSG
for more information.
- Log onto your member cluster and retrieve the resources with unexpected reportings.
- Check if its generation (
.metadata.generation field) matches with the observedInMemberClusterGeneration value
in the drift detection and/or configuration difference check reportings. A mismatch might signal that the
reportings are not yet up-to-date; they should get refreshed soon. - The
kubectl.kubernetes.io/last-applied-configuration annotation and/or the .metadata.managedFields field might
have some relevant information on which agents have attempted to update/patch the resource. KubeFleet changes
are executed under the name work-api-agent; if you see other manager names, check if it comes from a known source
(e.g., Kubernetes controller) in your cluster.
File an issue to the KubeFleet team if you believe that
the unexpected reportings come from a bug in KubeFleet.
5.10 - Diff Reporting Failure TSG
Troubleshoot failures in the diff reporting process
This document helps you troubleshoot diff reporting failures when using KubeFleet placement APIs (ClusterResourcePlacement or ResourcePlacement),
specifically when you find that the ClusterResourcePlacementDiffReported (for ClusterResourcePlacement) or ResourcePlacementDiffReported (for ResourcePlacement) status condition has been
set to False in the placement status.
Note
If you are looking for troubleshooting steps on unexpected drift detection and/or configuration
difference detection results, see the Drift Detection and Configuration Difference Detection Failure TSG
instead.
Note
The ClusterResourcePlacementDiffReported or ResourcePlacementDiffReported status condition will only be set if the placement has
an apply strategy of the ReportDiff type. If your placement uses ClientSideApply (default) or
ServerSideApply typed apply strategies, it is perfectly normal if the diff reported
status condition is absent in the placement status.
Common scenarios
The ClusterResourcePlacementDiffReported or ResourcePlacementDiffReported status condition will be set to False if KubeFleet cannot complete
the configuration difference checking process for one or more of the selected resources.
Depending on your placement configuration, KubeFleet might use one of the three approaches for configuration
difference checking:
- If the resource cannot be found on a member cluster, KubeFleet will simply report a full object
difference.
- If you ask KubeFleet to perform partial comparisons, i.e., the
comparisonOption field in the
placement apply strategy (.spec.strategy.applyStrategy.comparisonOption field) is set to partialComparison,
KubeFleet will perform a dry-run apply op (server-side apply with conflict overriding enabled) and
compare the returned apply result against the current state of the resource on the member cluster
side for configuration differences. - If you ask KubeFleet to perform full comparisons, i.e., the
comparisonOption field in the
placement apply strategy (.spec.strategy.applyStrategy.comparisonOption field) is set to fullComparison,
KubeFleet will directly compare the given manifest (the resource created on the hub cluster side) against
the current state of the resource on the member cluster side for configuration differences.
Failures might arise if:
- The dry-run apply op does not complete successfully; or
- An unexpected error occurs during the comparison process, such as a JSON path parsing/evaluation error.
Investigation steps
If you encounter such a failure, follow the steps below for investigation:
Identify the specific resources that have failed in the diff reporting process first. In the placement status,
find out the individual member clusters that have diff reporting failures: inspect the
.status.placementStatuses field of the placement object; each entry corresponds to a member cluster, and
for each entry, check if it has a status condition, ClusterResourcePlacementDiffReported (for ClusterResourcePlacement) or ResourcePlacementDiffReported (for ResourcePlacement), in
the .status.placementStatuses[*].conditions field, which has been set to False. Write down the name
of the member cluster.
For each cluster name that has been written down, list all the work objects that have been created
for the cluster in correspondence with the placement object:
# For ClusterResourcePlacement:
# Replace [YOUR-CLUSTER-NAME] and [YOUR-CRP-NAME] with values of your own.
kubectl get work -n fleet-member-[YOUR-CLUSTER-NAME] -l kubernetes-fleet.io/parent-CRP=[YOUR-CRP-NAME]
# For ResourcePlacement:
# Replace [YOUR-CLUSTER-NAME] and [YOUR-RP-NAME] with values of your own.
kubectl get work -n fleet-member-[YOUR-CLUSTER-NAME] -l kubernetes-fleet.io/parent-CRP=[YOUR-RP-NAME]
For each found work object, inspect its status. The .status.manifestConditions field features an array of which
each item explains about the processing result of a resource on the given member cluster. Find out all items with
a ClusterResourcePlacementDiffReported or ResourcePlacementDiffReported condition in the .status.manifestConditions[*].conditions field that has been set to False.
The .status.manifestConditions[*].identifier field tells the GVK, namespace, and name of the failing resource.
Read the message field of the ClusterResourcePlacementDiffReported or ResourcePlacementDiffReported condition (.status.manifestConditions[*].conditions[*].message);
KubeFleet will include the details about the diff reporting failures in the field.
If you are familiar with the cause of the error (for example, dry-run apply ops fails due to API server traffic control
measures), fixing the cause (tweaking traffic control limits) should resolve the failure. KubeFleet will periodically
retry diff reporting in face of failures. Otherwise, file an issue to the KubeFleet team.
5.11 - Staged Update Run TSG
Identify and fix KubeFleet issues associated with both ClusterStagedUpdateRun and StagedUpdateRun APIs
This guide provides troubleshooting steps for common issues related to both cluster-scoped and namespace-scoped Staged Update Runs.
Note: To get more information about failures, you can check the updateRun controller logs.
Things to keep in mind when using updateRun
If updateRun is created with Initialized/Stop state updateRun won’t start execution. In both cases updateRun will be initialized.
State set to Initialize,
spec:
placementName: example-placement
resourceSnapshotIndex: "0"
stagedRolloutStrategyName: example-strategy
state: Initialize
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: "2026-01-09T01:21:18Z"
message: The UpdateRun initialized successfully
observedGeneration: 1
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
State set to Stop,
spec:
placementName: example-placement
resourceSnapshotIndex: "0"
stagedRolloutStrategyName: example-strategy
state: Stop
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: "2026-01-09T01:22:55Z"
message: The UpdateRun initialized successfully
observedGeneration: 1
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: "2026-01-09T01:22:55Z"
message: The update run has been stopped
observedGeneration: 1
reason: UpdateRunStopped
status: "False"
type: Progressing
Cluster-Scoped Troubleshooting
CRP status without Staged Update Run
When a ClusterResourcePlacement is created with spec.strategy.type set to External, the rollout does not start immediately.
A sample status of such ClusterResourcePlacement is as follows:
$ kubectl describe crp example-placement
...
Status:
Conditions:
Last Transition Time: 2026-01-08T00:19:58Z
Message: found all cluster needed as specified by the scheduling policy, found 2 cluster(s)
Observed Generation: 1
Reason: SchedulingPolicyFulfilled
Status: True
Type: ClusterResourcePlacementScheduled
Last Transition Time: 2026-01-08T00:19:58Z
Message: Rollout is controlled by an external controller and no resource snapshot name is observed across clusters, probably rollout has not started yet
Observed Generation: 1
Reason: RolloutControlledByExternalController
Status: Unknown
Type: ClusterResourcePlacementRolloutStarted
Placement Statuses:
Cluster Name: member1
Conditions:
Last Transition Time: 2026-01-08T00:19:58Z
Message: Successfully scheduled resources for placement in "member1" (affinity score: 0, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2026-01-08T00:19:58Z
Message: In the process of deciding whether to roll out some version of the resources or not
Observed Generation: 1
Reason: RolloutStartedUnknown
Status: Unknown
Type: RolloutStarted
Cluster Name: member2
Conditions:
Last Transition Time: 2026-01-08T00:19:58Z
Message: Successfully scheduled resources for placement in "member2" (affinity score: 0, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2026-01-08T00:19:58Z
Message: In the process of deciding whether to roll out some version of the resources or not
Observed Generation: 1
Reason: RolloutStartedUnknown
Status: Unknown
Type: RolloutStarted
Events: <none>
ClusterResourcePlacementScheduled condition indicates the CRP has been fully scheduled, while ClusterResourcePlacementRolloutStarted condition shows that the rollout has not started.
In the Placement Statuses section, it displays the detailed status of each cluster. Both selected clusters are in the Scheduled state, but the RolloutStarted condition is still Unknown because the rollout has not kicked off yet.
Investigate ClusterStagedUpdateRun initialization failure
An updateRun initialization failure can be easily detected by getting the resource:
$ kubectl get csur example-run
NAME PLACEMENT RESOURCE-SNAPSHOT-INDEX POLICY-SNAPSHOT-INDEX INITIALIZED PROGRESSING SUCCEEDED AGE
example-run example-placement 1 0 False 4s
The INITIALIZED field is False, indicating the initialization failed.
Describe the updateRun to get more details:
$ kubectl describe csur example-run
...
Applied Strategy:
Comparison Option: PartialComparison
Type: ClientSideApply
When To Apply: Always
When To Take Over: Always
Conditions:
Last Transition Time: 2026-01-08T00:35:09Z
Message: cannot continue the updateRun: failed to validate the updateRun: failed to process the request due to a client error: no resourceSnapshots with index `1` found for placement `/example-placement`
Observed Generation: 1
Reason: UpdateRunInitializedFailed
Status: False
Type: Initialized
Deletion Stage Status:
Clusters:
Stage Name: kubernetes-fleet.io/deleteStage
Policy Observed Cluster Count: 2
Policy Snapshot Index Used: 0
...
The condition clearly indicates the initialization failed. The condition message gives more details about the failure.
In this case, a non-existing resource snapshot index 1 was used for the updateRun.
Investigate ClusterStagedUpdateRun execution failure
An updateRun execution failure can be easily detected by getting the resource:
$ kubectl get csur example-run
NAME PLACEMENT RESOURCE-SNAPSHOT-INDEX POLICY-SNAPSHOT-INDEX INITIALIZED SUCCEEDED AGE
example-run example-placement 0 0 True False 24m
The SUCCEEDED field is False, indicating the execution failure.
An updateRun execution failure can be caused by mainly 2 scenarios:
- When the updateRun controller is triggered to reconcile an in-progress updateRun, it starts by doing a bunch of validations
including retrieving the CRP and checking its rollout strategy, gathering all the bindings and regenerating the execution plan.
If any failure happens during validation, the updateRun execution fails with the corresponding validation error.
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: "2026-01-08T00:40:53Z"
message: The UpdateRun initialized successfully
observedGeneration: 2
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: "2026-01-08T00:41:34Z"
message: The stages are aborted due to a non-recoverable error
observedGeneration: 2
reason: UpdateRunFailed
status: "False"
type: Progressing
- lastTransitionTime: "2026-01-08T00:41:34Z"
message: 'cannot continue the updateRun: failed to validate the updateRun: failed
to process the request due to a client error: parent placement not found'
observedGeneration: 2
reason: UpdateRunFailed
status: "False"
type: Succeeded
- The updateRun controller triggers update to a member cluster by updating the corresponding binding spec and setting its
status to
RolloutStarted. It then waits for default 15 seconds and check whether the resources have been successfully applied
by checking the binding again. In case that there are multiple concurrent updateRuns, and during the 15-second wait, some other
updateRun preempts and updates the binding with new configuration, current updateRun detects and fails with clear error message.status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: "2026-01-08T00:57:38Z"
message: The UpdateRun initialized successfully
observedGeneration: 1
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: "2026-01-08T00:57:53Z"
message: The stages are aborted due to a non-recoverable error
observedGeneration: 1
reason: UpdateRunFailed
status: "False"
type: Progressing
- lastTransitionTime: "2026-01-08T00:57:53Z"
message: 'cannot continue the updateRun: failed to process the request due to
a client error: the binding of the updating cluster `member2` in the
stage `staging` is not up-to-date with the desired status, please check the
status of binding `example-placement-member2-e1a567da` and see if there
is a concurrent updateRun referencing the same placement and
updating the same cluster'
observedGeneration: 1
reason: UpdateRunFailed
status: "False"
type: Succeeded
Succeeded condition is set to False with reason UpdateRunFailed. In the message, we show member2 cluster in staging stage gets preempted, and the user is prompted to check example-placement-member2-e1a567da binding to verfiy if there is a concurrent updateRun referencing the same clusterResourcePlacement and updating the same clusterkubectl get clusterresourcebindings
NAME WORKSYNCHRONIZED RESOURCESAPPLIED AGE
example-placement-member1-9a1ee3a0 20m
example-placement-member2-e1a567da True True 20m
example-placement-member2-e1a567da, we can check the binding:kubectl get clusterresourcebinding example-placement-member2-e1a567da -o yaml
...
spec:
applyStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
clusterDecision:
clusterName: member2
clusterScore:
affinityScore: 0
priorityScore: 0
reason: 'Successfully scheduled resources for placement in "member2" (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
selected: true
resourceSnapshotName: example-placement-1-snapshot
schedulingPolicySnapshotName: example-placement-0
state: Bound
targetCluster: member2
status:
conditions:
- lastTransitionTime: "2026-01-08T00:57:39Z"
message: 'Detected the new changes on the resources and started the rollout process,
resourceSnapshotIndex: 1, updateRun: example-run-1'
observedGeneration: 3
reason: RolloutStarted
status: "True"
type: RolloutStarted
...
RolloutStarted condition shows, it’s updated by another updateRun example-run-1.
The updateRun abortion due to execution failures is not recoverable at the moment. If failure happens due to validation error,
one can fix the issue and create a new updateRun. If preemption happens, in most cases the user is releasing a new resource
version, and they can just let the new updateRun run to complete.
Investigate ClusterStagedUpdateRun rollout stuck
A ClusterStagedUpdateRun can get stuck when resource placement fails on some clusters. Getting the updateRun will show the cluster name and stage that is in stuck state:
$ kubectl get csur example-run -o yaml
...
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: "2026-01-12T22:42:52Z"
message: The UpdateRun initialized successfully
observedGeneration: 2
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: "2026-01-12T22:49:51Z"
message: The updateRun is stuck waiting for member2 cluster(s) in stage staging to finish
updating, please check placement status for potential errors
observedGeneration: 2
reason: UpdateRunStuck
status: "False"
type: Progressing
...
stagesStatus:
- clusters:
- clusterName: member2
conditions:
- lastTransitionTime: "2026-01-12T22:44:08Z"
message: Cluster update started
observedGeneration: 2
reason: ClusterUpdatingStarted
status: "True"
type: Started
conditions:
- lastTransitionTime: "2026-01-12T22:44:08Z"
message: Clusters in the stage started updating
observedGeneration: 2
reason: StageUpdatingStarted
status: "True"
type: Progressing
stageName: staging # stage name mentioned in message.
startTime: "2026-01-12T22:44:08Z"
- clusters:
- clusterName: member1
stageName: canary
...
The message shows that the updateRun is stuck waiting for member2 cluster in stage staging to finish releasing.
From the stagesStatus we also can see member2 is the cluster in stage staging. The updateRun controller rolls
resources to a member cluster by updating its corresponding binding. It then checks periodically whether the
update has completed or not. If the binding is still not available after current default 5 minutes, updateRun
controller decides the rollout has stuck and reports the condition.
This usually indicates something wrong happened on the cluster or the resources have some issue. To further investigate, you can check the ClusterResourcePlacement status:
$ kubectl describe crp example-placement
...
Placement Statuses:
...
Cluster Name: member2
Conditions:
Last Transition Time: 2026-01-12T22:37:57Z
Message: Successfully scheduled resources for placement in "member2" (affinity score: 0, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2026-01-12T22:44:08Z
Message: Detected the new changes on the resources and started the rollout process, resourceSnapshotIndex: 1, updateRun: example-run
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: RolloutStarted
Last Transition Time: 2026-01-12T22:44:08Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: Overridden
Last Transition Time: 2026-01-12T22:44:08Z
Message: All of the works are synchronized to the latest
Observed Generation: 1
Reason: AllWorkSynced
Status: True
Type: WorkSynchronized
Last Transition Time: 2026-01-12T22:44:08Z
Message: All corresponding work objects are applied
Observed Generation: 1
Reason: AllWorkHaveBeenApplied
Status: True
Type: Applied
Last Transition Time: 2026-01-12T22:44:08Z
Message: Work object example-placement-work is not yet available
Observed Generation: 1
Reason: NotAllWorkAreAvailable
Status: False
Type: Available
Failed Placements:
Condition:
Last Transition Time: 2026-01-12T22:44:08Z
Message: Manifest is not yet available; Fleet will check again later
Observed Generation: 1
Reason: ManifestNotAvailableYet
Status: False
Type: Available
Group: apps
Kind: Deployment
Name: nginx-deployment
Namespace: test-namespace
Version: v1
...
The Available condition is False and we show reason as NotAllWorkAreAvailable. And in the “failed placements” section, it shows
the nginx-deployment deployment is not available. Check from member2 cluster and we can see
there’s image pull failure:
kubectl config use-context member2
kubectl get deployment -n test-namespace
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/3 3 0 9m54s
kubectl get pods -n test-namespace
NAME READY STATUS RESTARTS AGE
nginx-deployment-5d9874b8b9-gnmm2 0/1 InvalidImageName 0 10m
nginx-deployment-5d9874b8b9-p9zsx 0/1 InvalidImageName 0 10m
nginx-deployment-5d9874b8b9-wxmd7 0/1 InvalidImageName 0 10m
Note: A similar scenario can occur when updateRun’s state is set to Stop since we allow ongoing resource placement on a cluster to continue even when State is Stop.
For more debugging instructions, you can refer to ClusterResourcePlacement TSG.
After resolving the issue, you can create always create a new updateRun to restart the rollout. Stuck updateRuns can be deleted.
ClusterApprovalRequest Troubleshooting
A ClusterStagedUpdateRun is not progressing after approval from user,
Getting the ClusterStagedUpdateRun should give us some insight,
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: "2026-01-09T01:49:06Z"
message: The UpdateRun initialized successfully
observedGeneration: 1
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: "2026-01-09T01:55:36Z"
message: The updateRun is waiting for after-stage tasks in stage staging to complete
observedGeneration: 1
reason: UpdateRunWaiting
status: "False"
type: Progressing
Looks like updateRun is still waiting for approval from user. Lets get the ClusterApprovalRequest to verify,
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterApprovalRequest
metadata:
creationTimestamp: "2026-01-09T01:49:36Z"
generation: 1
labels:
kubernetes-fleet.io/isLatestUpdateRunApproval: "true"
kubernetes-fleet.io/targetUpdateRun: example-run
kubernetes-fleet.io/targetUpdatingStage: staging
kubernetes-fleet.io/taskType: afterStage
name: example-run-after-staging
resourceVersion: "20752"
uid: 9eae4ea0-3c4c-4182-a1d6-b7f1761caa6a
spec:
parentStageRollout: example-run
targetStage: staging
status:
conditions:
- lastTransitionTime: "2026-01-09T01:53:53Z"
message: approved
observedGeneration: 0
reason: approved
status: "True"
type: Approved
We can notice that user has approved the request but we don’t see the ApprovalAccepted Condition set on the object. Taking a closer look we can clearly see that the observedGeneration for the Approved condition doesn’t match the object’s generation. This applies to both before and after stage tasks.
Please refer to Deploy a ClusterStagedUpdateRun to rollout latest change to approve the ClusterApprovalRequest correctly.
Namespace-Scoped Troubleshooting
Namespace-scoped StagedUpdateRun troubleshooting is a mirror image of cluster-scoped ClusterStagedUpdateRun troubleshooting. The concepts, failure patterns, and diagnostic approaches are exactly the same - only the resource names, scopes, and kubectl commands differ.
Both follow identical troubleshooting patterns:
- Initialization failures: Missing resource snapshots, invalid configurations
- Execution failures: Validation errors, concurrent updateRun conflicts
- Rollout stuck scenarios: Resource placement failures, cluster connectivity issues
- Status investigation: Using
kubectl get, kubectl describe, and checking placement status - Recovery approaches: Creating new updateRuns, cleaning up stuck resources
The key differences are:
- Resource scope: Namespace-scoped vs cluster-scoped resources
- Commands: Use
sur (StagedUpdateRun) instead of csur (ClusterStagedUpdateRun) - Target resources:
ResourcePlacement instead of ClusterResourcePlacement - Bindings:
resourcebindings instead of clusterresourcebindings - Approvals:
approvalrequests instead of clusterapprovalrequests
ResourcePlacement status without Staged Update Run
When a namespace-scoped ResourcePlacement is created with spec.strategy.type set to External, the rollout does not start immediately.
A sample status of such ResourcePlacement is as follows:
$ kubectl describe rp web-app-placement -n my-app-namespace
...
Status:
Conditions:
Last Transition Time: 2026-01-08T20:24:59Z
Message: found all cluster needed as specified by the scheduling policy, found 2 cluster(s)
Observed Generation: 1
Reason: SchedulingPolicyFulfilled
Status: True
Type: ResourcePlacementScheduled
Last Transition Time: 2026-01-08T20:24:59Z
Message: Rollout is controlled by an external controller and no resource snapshot name is observed across clusters, probably rollout has not started yet
Observed Generation: 1
Reason: RolloutControlledByExternalController
Status: Unknown
Type: ResourcePlacementRolloutStarted
Placement Statuses:
Cluster Name: member1
Conditions:
Last Transition Time: 2026-01-08T20:24:59Z
Message: Successfully scheduled resources for placement in "member1" (affinity score: 0, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2026-01-08T20:24:59Z
Message: In the process of deciding whether to roll out some version of the resources or not
Observed Generation: 1
Reason: RolloutStartedUnknown
Status: Unknown
Type: RolloutStarted
...
Events: <none>
SchedulingPolicyFulfilled condition indicates the ResourcePlacement has been fully scheduled, while ResourcePlacementRolloutStarted condition shows that the rollout is unknown.
Investigate StagedUpdateRun initialization failure
A namespace-scoped updateRun initialization failure can be easily detected by getting the resource:
$ kubectl get sur web-app-rollout -n my-app-namespace
NAME PLACEMENT RESOURCE-SNAPSHOT-INDEX POLICY-SNAPSHOT-INDEX INITIALIZED SUCCEEDED AGE
web-app-rollout web-app-placement 1 0 False 2s
The INITIALIZED field is False, indicating the initialization failed.
Describe the updateRun to get more details:
$ kubectl describe sur web-app-rollout -n my-app-namespace
...
Status:
Applied Strategy:
Comparison Option: PartialComparison
Type: ClientSideApply
When To Apply: Always
When To Take Over: Always
Conditions:
Last Transition Time: 2026-01-08T20:29:56Z
Message: cannot continue the updateRun: failed to validate the updateRun: failed to process the request due to a client error: no resourceSnapshots with index `1` found for placement `my-app-namespace/web-app-placement`
Observed Generation: 1
Reason: UpdateRunInitializedFailed
Status: False
Type: Initialized
Deletion Stage Status:
Clusters:
Stage Name: kubernetes-fleet.io/deleteStage
Policy Observed Cluster Count: 2
Policy Snapshot Index Used: 0
...
The condition clearly indicates the initialization failed. The condition message gives more details about the failure.
In this case, a non-existing resource snapshot index 1 was used for the updateRun.
Investigate StagedUpdateRun execution failure
A namespace-scoped updateRun execution failure can be easily detected by getting the resource:
$ kubectl get sur web-app-rollout -n my-app-namespace
NAME PLACEMENT RESOURCE-SNAPSHOT-INDEX POLICY-SNAPSHOT-INDEX INITIALIZED SUCCEEDED AGE
web-app-rollout web-app-placement 0 0 True False 24m
The SUCCEEDED field is False, indicating the execution failure.
The execution failure scenarios are similar to cluster-scoped updateRuns:
Validation errors during reconciliation: The updateRun controller validates the ResourcePlacement, gathers bindings, and regenerates the execution plan. If any failure occurs, the updateRun execution fails:
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: "2026-01-08T20:53:11Z"
message: The UpdateRun initialized successfully
observedGeneration: 2
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: "2026-01-08T20:54:12Z"
message: The stages are aborted due to a non-recoverable error
observedGeneration: 2
reason: UpdateRunFailed
status: "False"
type: Progressing
- lastTransitionTime: "2026-01-08T20:54:12Z"
message: 'cannot continue the updateRun: failed to validate the updateRun: failed
to process the request due to a client error: parent placement not found'
observedGeneration: 2
reason: UpdateRunFailed
status: "False"
type: Succeeded
Concurrent updateRun preemption: When multiple updateRuns target the same ResourcePlacement, they may conflict:
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: "2026-01-08T21:18:35Z"
message: The UpdateRun initialized successfully
observedGeneration: 1
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: "2026-01-08T21:18:50Z"
message: The stages are aborted due to a non-recoverable error
observedGeneration: 1
reason: UpdateRunFailed
status: "False"
type: Progressing
- lastTransitionTime: "2026-01-08T21:18:50Z"
message: 'cannot continue the updateRun: failed to process the request due to
a client error: the binding of the updating cluster `member2` in the
stage `dev` is not up-to-date with the desired status, please check the status
of binding `my-app-namespace/web-app-placement-member2-43991b15` and
see if there is a concurrent updateRun referencing the same placement
and updating the same cluster'
observedGeneration: 1
reason: UpdateRunFailed
status: "False"
type: Succeeded
To investigate concurrent updateRuns, check the namespace-scoped resource bindings:
$ kubectl get resourcebindings -n my-app-namespace
NAME WORKSYNCHRONIZED RESOURCESAPPLIED AGE
web-app-placement-member1-2afc7d7f 51m
web-app-placement-member2-43991b15 True True 51m
Investigate StagedUpdateRun rollout stuck
A StagedUpdateRun can get stuck when resource placement fails on some clusters:
$ kubectl get sur web-app-rollout -n my-app-namespace -o yaml
...
status:
appliedStrategy:
comparisonOption: PartialComparison
type: ClientSideApply
whenToApply: Always
whenToTakeOver: Always
conditions:
- lastTransitionTime: "2026-01-08T22:39:51Z"
message: The UpdateRun initialized successfully
observedGeneration: 1
reason: UpdateRunInitializedSuccessfully
status: "True"
type: Initialized
- lastTransitionTime: "2026-01-08T22:45:34Z"
message: The updateRun is stuck waiting for member2 cluster(s) in stage dev to finish
updating, please check placement status for potential errors
observedGeneration: 1
reason: UpdateRunStuck
status: "False"
type: Progressing
...
To investigate further, check the ResourcePlacement status:
$ kubectl describe rp web-app-placement -n my-app-namespace
...
Placement Statuses:
...
Cluster Name: member2
Conditions:
Last Transition Time: 2026-01-08T22:34:44Z
Message: Successfully scheduled resources for placement in "member2" (affinity score: 0, topology spread score: 0): picked by scheduling policy
Observed Generation: 1
Reason: Scheduled
Status: True
Type: Scheduled
Last Transition Time: 2026-01-08T22:35:56Z
Message: Detected the new changes on the resources and started the rollout process, resourceSnapshotIndex: 1, updateRun: web-app-rollout-v1-21
Observed Generation: 1
Reason: RolloutStarted
Status: True
Type: RolloutStarted
Last Transition Time: 2026-01-08T22:39:51Z
Message: No override rules are configured for the selected resources
Observed Generation: 1
Reason: NoOverrideSpecified
Status: True
Type: Overridden
Last Transition Time: 2026-01-08T22:39:51Z
Message: All of the works are synchronized to the latest
Observed Generation: 1
Reason: AllWorkSynced
Status: True
Type: WorkSynchronized
Last Transition Time: 2026-01-08T22:39:51Z
Message: All corresponding work objects are applied
Observed Generation: 1
Reason: AllWorkHaveBeenApplied
Status: True
Type: Applied
Last Transition Time: 2026-01-08T22:39:51Z
Message: Work object my-app-namespace.web-app-placement-work is not yet available
Observed Generation: 1
Reason: NotAllWorkAreAvailable
Status: False
Type: Available
Failed Placements:
Condition:
Last Transition Time: 2026-01-08T22:39:51Z
Message: Manifest is not yet available; Fleet will check again later
Observed Generation: 2
Reason: ManifestNotAvailableYet
Status: False
Type: Available
Group: apps
Kind: Deployment
Name: web-app
Namespace: my-app-namespace
Version: v1
...
Check the target cluster to diagnose the specific issue:
kubectl config use-context member2
kubectl get deploy web-app -n my-app-namespace
NAME READY UP-TO-DATE AVAILABLE AGE
web-app 0/1 1 1 9m51s
kubectl get pods -n my-app-namespace
NAME READY STATUS RESTARTS AGE
web-app-578cf755cd-rz2f4 0/1 InvalidImageName 0 9m51s
Note: A similar scenario can occur when updateRun’s state is set to Stop since we allow ongoing resource placement on a cluster to continue even when State is Stop.
Namespace-Scoped Approval Troubleshooting
For namespace-scoped staged updates with approval gates, check for ApprovalRequest objects:
# List approval requests in the namespace
$ kubectl get approvalrequests -n my-app-namespace
NAME UPDATE-RUN STAGE APPROVED AGE
web-app-rollout-before-dev web-app-rollout dev True 92s
Lets get the before stage approval request object,
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ApprovalRequest
metadata:
creationTimestamp: "2026-01-09T02:31:57Z"
generation: 1
labels:
kubernetes-fleet.io/isLatestUpdateRunApproval: "true"
kubernetes-fleet.io/targetUpdateRun: web-app-rollout
kubernetes-fleet.io/targetUpdatingStage: dev
kubernetes-fleet.io/taskType: beforeStage
name: web-app-rollout-before-dev
namespace: my-app-namespace
resourceVersion: "25386"
uid: 6442e1ef-b694-4d59-8691-a3f5200c29ad
spec:
parentStageRollout: web-app-rollout
targetStage: dev
status:
conditions:
- lastTransitionTime: "2026-01-09T02:33:15Z"
message: approved
observedGeneration: 0
reason: approved
status: "True"
type: Approved
The generation and observedGeneration don’t match in this scenario.
Please refer to Monitor namespace-scoped staged rollout to approve the ApprovalRequest correctly.
After resolving issues, create a new updateRun to restart the rollout. Stuck updateRuns can be deleted safely.
5.12 - ClusterResourcePlacementEviction TSG
Identify and fix KubeFleet issues associated with the ClusterResourcePlacementEviction API
This guide provides troubleshooting steps for issues related to placement eviction.
An eviction object when created is ideally only reconciled once and reaches a terminal state. List of terminal states
for eviction are:
- Eviction is Invalid
- Eviction is Valid, Eviction failed to Execute
- Eviction is Valid, Eviction executed successfully
Note: If an eviction object doesn’t reach a terminal state i.e. neither valid condition nor executed condition is
set it is likely due to a failure in the reconciliation process where the controller is unable to reach the api server.
The first step in troubleshooting is to check the status of the eviction object to understand if the eviction reached
a terminal state or not.
Invalid eviction
Missing/Deleting CRP object
Example status with missing CRP object:
status:
conditions:
- lastTransitionTime: "2025-04-17T22:16:59Z"
message: Failed to find ClusterResourcePlacement targeted by eviction
observedGeneration: 1
reason: ClusterResourcePlacementEvictionInvalid
status: "False"
type: Valid
Example status with deleting CRP object:
status:
conditions:
- lastTransitionTime: "2025-04-21T19:53:42Z"
message: Found deleting ClusterResourcePlacement targeted by eviction
observedGeneration: 1
reason: ClusterResourcePlacementEvictionInvalid
status: "False"
type: Valid
In both cases the Eviction object reached a terminal state, its status has Valid condition set to False.
The user should verify if the ClusterResourcePlacement object is missing or if it is being deleted and recreate the
ClusterResourcePlacement object if needed and retry eviction.
Missing CRB object
Example status with missing CRB object:
status:
conditions:
- lastTransitionTime: "2025-04-17T22:21:51Z"
message: Failed to find scheduler decision for placement in cluster targeted by
eviction
observedGeneration: 1
reason: ClusterResourcePlacementEvictionInvalid
status: "False"
type: Valid
Note: The user can find the corresponding ClusterResourceBinding object by listing all ClusterResourceBinding
objects for the ClusterResourcePlacement object
kubectl get rb -l kubernetes-fleet.io/parent-CRP=<CRPName>
The ClusterResourceBinding object name is formatted as <CRPName>-<ClusterName>-randomsuffix
In this case the Eviction object reached a terminal state, its status has Valid condition set to False, because the
ClusterResourceBinding object or Placement for target cluster is not found. The user should verify to see if the
ClusterResourcePlacement object is propagating resources to the target cluster,
- If yes, the next step is to check if the
ClusterResourceBinding object is present for the target cluster or why it
was not created and try to create an eviction object once ClusterResourceBinding is created. - If no, the cluster is not picked by the scheduler and hence no need to retry eviction.
Multiple CRB is present
Example status with multiple CRB objects:
status:
conditions:
- lastTransitionTime: "2025-04-17T23:48:08Z"
message: Found more than one scheduler decision for placement in cluster targeted
by eviction
observedGeneration: 1
reason: ClusterResourcePlacementEvictionInvalid
status: "False"
type: Valid
In this case the Eviction object reached a terminal state, its status has Valid condition set to False, because
there is more than one ClusterResourceBinding object or Placement present for the ClusterResourcePlacement object
targeting the member cluster. This is a rare scenario, it’s an in-between state where bindings are being-recreated due
to the member cluster being selected again, and it will normally resolve quickly.
PickFixed CRP is targeted by CRP Eviction
Example status for ClusterResourcePlacementEviction object targeting a PickFixed ClusterResourcePlacement object:
status:
conditions:
- lastTransitionTime: "2025-04-21T23:19:06Z"
message: Found ClusterResourcePlacement with PickFixed placement type targeted
by eviction
observedGeneration: 1
reason: ClusterResourcePlacementEvictionInvalid
status: "False"
type: Valid
In this case the Eviction object reached a terminal state, its status has Valid condition set to False, because
the ClusterResourcePlacement object is of type PickFixed. Users cannot use ClusterResourcePlacementEviction
objects to evict resources propagated by ClusterResourcePlacement objects of type PickFixed. The user can instead
remove the member cluster name from the clusterNames field in the policy of the ClusterResourcePlacement object.
Failed to execute eviction
Eviction blocked because placement is missing
status:
conditions:
- lastTransitionTime: "2025-04-23T23:54:03Z"
message: Eviction is valid
observedGeneration: 1
reason: ClusterResourcePlacementEvictionValid
status: "True"
type: Valid
- lastTransitionTime: "2025-04-23T23:54:03Z"
message: Eviction is blocked, placement has not propagated resources to target
cluster yet
observedGeneration: 1
reason: ClusterResourcePlacementEvictionNotExecuted
status: "False"
type: Executed
In this case the Eviction object reached a terminal state, its status has Executed condition set to False, because
for the targeted ClusterResourcePlacement the corresponding ClusterResourceBinding object’s spec is set to
Scheduled meaning the rollout of resources is not started yet.
Note: The user can find the corresponding ClusterResourceBinding object by listing all ClusterResourceBinding
objects for the ClusterResourcePlacement object
kubectl get rb -l kubernetes-fleet.io/parent-CRP=<CRPName>
The ClusterResourceBinding object name is formatted as <CRPName>-<ClusterName>-randomsuffix.
spec:
applyStrategy:
type: ClientSideApply
clusterDecision:
clusterName: kind-cluster-3
clusterScore:
affinityScore: 0
priorityScore: 0
reason: 'Successfully scheduled resources for placement in "kind-cluster-3" (affinity
score: 0, topology spread score: 0): picked by scheduling policy'
selected: true
resourceSnapshotName: ""
schedulingPolicySnapshotName: test-crp-1
state: Scheduled
targetCluster: kind-cluster-3
Here the user can wait for the ClusterResourceBinding object to be updated to Bound state which means that
resources have been propagated to the target cluster and then retry eviction. In some cases this can take a while or not
happen at all, in that case the user should verify if rollout is stuck for ClusterResourcePlacement object.
Eviction blocked by Invalid CRPDB
Example status for ClusterResourcePlacementEviction object with invalid ClusterResourcePlacementDisruptionBudget,
status:
conditions:
- lastTransitionTime: "2025-04-21T23:39:42Z"
message: Eviction is valid
observedGeneration: 1
reason: ClusterResourcePlacementEvictionValid
status: "True"
type: Valid
- lastTransitionTime: "2025-04-21T23:39:42Z"
message: Eviction is blocked by misconfigured ClusterResourcePlacementDisruptionBudget,
either MaxUnavailable is specified or MinAvailable is specified as a percentage
for PickAll ClusterResourcePlacement
observedGeneration: 1
reason: ClusterResourcePlacementEvictionNotExecuted
status: "False"
type: Executed
In this cae the Eviction object reached a terminal state, its status has Executed condition set to False, because
the ClusterResourcePlacementDisruptionBudget object is invalid. For ClusterResourcePlacement objects of type
PickAll, when specifying a ClusterResourcePlacementDisruptionBudget the minAvailable field should be set to an
absolute number and not a percentage and the maxUnavailable field should not be set since the total number of
placements is non-deterministic.
Eviction blocked by specified CRPDB
Example status for ClusterResourcePlacementEviction object blocked by a ClusterResourcePlacementDisruptionBudget
object,
status:
conditions:
- lastTransitionTime: "2025-04-24T18:54:30Z"
message: Eviction is valid
observedGeneration: 1
reason: ClusterResourcePlacementEvictionValid
status: "True"
type: Valid
- lastTransitionTime: "2025-04-24T18:54:30Z"
message: 'Eviction is blocked by specified ClusterResourcePlacementDisruptionBudget,
availablePlacements: 2, totalPlacements: 2'
observedGeneration: 1
reason: ClusterResourcePlacementEvictionNotExecuted
status: "False"
type: Executed
In this cae the Eviction object reached a terminal state, its status has Executed condition set to False, because
the ClusterResourcePlacementDisruptionBudget object is blocking the eviction. The message from Executed condition
reads available placements is 2 and total placements is 2, which means that the ClusterResourcePlacementDisruptionBudget
is protecting all placements propagated by the ClusterResourcePlacement object.
Taking a look at the ClusterResourcePlacementDisruptionBudget object,
apiVersion: placement.kubernetes-fleet.io/v1beta1
kind: ClusterResourcePlacementDisruptionBudget
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"placement.kubernetes-fleet.io/v1beta1","kind":"ClusterResourcePlacementDisruptionBudget","metadata":{"annotations":{},"name":"pick-all-crp"},"spec":{"minAvailable":2}}
creationTimestamp: "2025-04-24T18:47:22Z"
generation: 1
name: pick-all-crp
resourceVersion: "1749"
uid: 7d3a0ac5-0225-4fb6-b5e9-fc28d58cefdc
spec:
minAvailable: 2
We can see that the minAvailable is set to 2, which means that at least 2 placements should be available for the
ClusterResourcePlacement object.
Let’s take a look at the ClusterResourcePlacement object’s status to verify the list of available placements,
status:
conditions:
- lastTransitionTime: "2025-04-24T18:46:38Z"
message: found all cluster needed as specified by the scheduling policy, found
2 cluster(s)
observedGeneration: 1
reason: SchedulingPolicyFulfilled
status: "True"
type: ClusterResourcePlacementScheduled
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: All 2 cluster(s) start rolling out the latest resource
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: ClusterResourcePlacementRolloutStarted
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: ClusterResourcePlacementOverridden
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: Works(s) are succcesfully created or updated in 2 target cluster(s)'
namespaces
observedGeneration: 1
reason: WorkSynchronized
status: "True"
type: ClusterResourcePlacementWorkSynchronized
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: The selected resources are successfully applied to 2 cluster(s)
observedGeneration: 1
reason: ApplySucceeded
status: "True"
type: ClusterResourcePlacementApplied
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: The selected resources in 2 cluster(s) are available now
observedGeneration: 1
reason: ResourceAvailable
status: "True"
type: ClusterResourcePlacementAvailable
observedResourceIndex: "0"
placementStatuses:
- clusterName: kind-cluster-1
conditions:
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: 'Successfully scheduled resources for placement in "kind-cluster-1"
(affinity score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2025-04-24T18:50:19Z"
message: All corresponding work objects are available
observedGeneration: 1
reason: AllWorkAreAvailable
status: "True"
type: Available
- clusterName: kind-cluster-2
conditions:
- lastTransitionTime: "2025-04-24T18:46:38Z"
message: 'Successfully scheduled resources for placement in "kind-cluster-2"
(affinity score: 0, topology spread score: 0): picked by scheduling policy'
observedGeneration: 1
reason: Scheduled
status: "True"
type: Scheduled
- lastTransitionTime: "2025-04-24T18:46:38Z"
message: Detected the new changes on the resources and started the rollout process
observedGeneration: 1
reason: RolloutStarted
status: "True"
type: RolloutStarted
- lastTransitionTime: "2025-04-24T18:46:38Z"
message: No override rules are configured for the selected resources
observedGeneration: 1
reason: NoOverrideSpecified
status: "True"
type: Overridden
- lastTransitionTime: "2025-04-24T18:46:38Z"
message: All of the works are synchronized to the latest
observedGeneration: 1
reason: AllWorkSynced
status: "True"
type: WorkSynchronized
- lastTransitionTime: "2025-04-24T18:46:38Z"
message: All corresponding work objects are applied
observedGeneration: 1
reason: AllWorkHaveBeenApplied
status: "True"
type: Applied
- lastTransitionTime: "2025-04-24T18:46:38Z"
message: All corresponding work objects are available
observedGeneration: 1
reason: AllWorkAreAvailable
status: "True"
type: Available
selectedResources:
- kind: Namespace
name: test-ns
version: v1
from the status we can see that the ClusterResourcePlacement object has 2 placements available, where resources have
been successfully applied and are available in kind-cluster-1 and kind-cluster-2. The users can check the individual
member clusters to verify the resources are available but the users are recommended to check theClusterResourcePlacement
object status to verify placement availability since the status is aggregated and updated by the controller.
Here the user can either remove the ClusterResourcePlacementDisruptionBudget object or update the minAvailable to
1 to allow ClusterResourcePlacementEviction object to execute successfully. In general the user should carefully
check the availability of placements and act accordingly when changing the ClusterResourcePlacementDisruptionBudget
object.
6 - Frequently Asked Questions
Frequently Asked Questions about KubeFleet
What are the KubeFleet-owned resources on the hub and member clusters? Can these KubeFleet-owned resources be modified by the user?
KubeFleet reserves all namespaces with the prefix fleet-, such as fleet-system and fleet-member-YOUR-CLUSTER-NAME where
YOUR-CLUSTER-NAME are names of member clusters that have joined the fleet. Additionally, KubeFleet will skip resources
under namespaces with the prefix kube-.
KubeFleet-owned internal resources on the hub cluster side include:
| Resource |
|---|
InternalMemberCluster |
Work |
ClusterResourceSnapshot |
ClusterSchedulingPolicySnapshot |
ClusterResourceBinding |
ResourceOverrideSnapshots |
ClusterResourceOverrideSnapshots |
ResourceSnapshot |
SchedulingPolicySnapshot |
ResourceBinding |
And the public APIs exposed by KubeFleet are:
| Resource |
|---|
ClusterResourcePlacement |
ClusterResourceEnvelope |
ResourceEnvelope |
ClusterStagedUpdateRun |
ClusterStagedUpdateRunStrategy |
ClusterApprovalRequests |
ClusterResourceOverrides |
ResourceOverrides |
ClusterResourcePlacementDisruptionBudgets |
ClusterResourcePlacementEvictions |
ResourcePlacement |
The following resources are the KubeFleet-owned internal resources on the member cluster side:
See the KubeFleet source code for the definitions of these APIs.
Depending on your setup, your environment might feature a few KubeFleet provided webhooks that help safeguard
the KubeFleet internal resources and the KubeFleet reserved namespaces.
Which kinds of resources can be propagated from the hub cluster to the member clusters? How can I control the list?
When you use the ClusterResourcePlacement or ResourcePlacement API to select resources for placement, KubeFleet will automatically ignore
certain Kubernetes resource groups and/or GVKs. The resources exempted from placement include:
- Pods and Nodes
- All resources in the
events.k8s.io resource group. - All resources in the
coordination.k8s.io resource group. - All resources in the
metrics.k8s.io resource group. - All KubeFleet internal resources.
Refer to the KubeFleet source code for more
information. In addition, KubeFleet will refuse to place the default namespace on the hub cluster to member clusters.
If you would like to enforce additional restrictions, set up the skipped-propagating-apis and/or the skipped-propagating-namespaces flag on the KubeFleet hub agent, which blocks a specific resource type or a specific
namespace for placement respectively.
You may also specify the allowed-propagating-apis flag on the KubeFleet hub agent to explicitly dictate
a number of resource types that can be placed via KubeFleet; all resource types not on the whitelist will not be
selected by KubeFleet for placement. Note that this flag is mutually exclusive with the skipped-propagating-apis flag.
What happens to existing resources in member clusters when their configuration is in conflict from their hub cluster counterparts?
By default, when KubeFleet encounters a pre-existing resource on the member cluster side, it will attempt to assume
ownership of the resource and overwrite its configuration with values from the hub cluster. You may use apply strategies
to fine-tune this behavior: for example, you may choose to let KubeFleet ignore all pre-existing resources, or let
KubeFleet check if the configuration is consistent between the hub cluster end and the member cluster end before KubeFleet
applies a manifest. For more information, see the KubeFleet documentation on takeover policies.
What happens if I modify a resource on the hub cluster that has been placed to member clusters? What happens if I modify a resource on the member cluster that is managed by KubeFleet?
If you write a resource on the hub cluster end, KubeFleet will synchronize your changes to all selected member clusters automatically.
Specifically, when you update a resource, your changes will be applied to all member clusters; should you choose to delete a
resource, it will be removed from all member clusters as well.
By default, KubeFleet will attempt to overwrite changes made on the member cluster side if the modified fields are managed by KubeFleet. If you choose to delete a KubeFleet-managed resource, KubeFleet will re-create it shortly. You can fine-tune this
behavior via KubeFleet apply strategies: KubeFleet can help you detect such changes (often known as configuration drifts),
preserve them as necessary, or overwrite them to keep the resources in sync. For more information, see the KubeFleet documentation
on drift detection capabilities.
7 - API Reference
Reference for KubeFleet APIs
Packages
7.1 - cluster.kubernetes-fleet.io/v1
API Reference
Packages
cluster.kubernetes-fleet.io/v1
Resource Types
AgentStatus
AgentStatus defines the observed status of the member agent of the given type.
Appears in:
| Field | Description | Default | Validation |
|---|
type AgentType | Type of the member agent. | | Required: {}
|
conditions Condition array | Conditions is an array of current observed conditions for the member agent. | | Optional: {}
|
lastReceivedHeartbeat Time | Last time we received a heartbeat from the member agent. | | Optional: {}
|
AgentType
Underlying type: string
AgentType defines a type of agent/binary running in a member cluster.
Appears in:
| Field | Description |
|---|
MemberAgent | MemberAgent (core) handles member cluster joining/leaving as well as k8s object placement from hub to member clusters.
|
MultiClusterServiceAgent | MultiClusterServiceAgent (networking) is responsible for exposing multi-cluster services via L4 load
balancer.
|
ServiceExportImportAgent | ServiceExportImportAgent (networking) is responsible for export or import services across multi-clusters.
|
ClusterState
Underlying type: string
Appears in:
| Field | Description |
|---|
Join | |
Leave | |
InternalMemberCluster
InternalMemberCluster is used by hub agent to notify the member agents about the member cluster state changes, and is used by the member agents to report their status.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | cluster.kubernetes-fleet.io/v1 | | |
kind string | InternalMemberCluster | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec InternalMemberClusterSpec | The desired state of InternalMemberCluster. | | Required: {}
|
status InternalMemberClusterStatus | The observed status of InternalMemberCluster. | | Optional: {}
|
InternalMemberClusterList
InternalMemberClusterList contains a list of InternalMemberCluster.
| Field | Description | Default | Validation |
|---|
apiVersion string | cluster.kubernetes-fleet.io/v1 | | |
kind string | InternalMemberClusterList | | |
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
items InternalMemberCluster array | | | |
InternalMemberClusterSpec
InternalMemberClusterSpec defines the desired state of InternalMemberCluster. Set by the hub agent.
Appears in:
| Field | Description | Default | Validation |
|---|
state ClusterState | The desired state of the member cluster. Possible values: Join, Leave. | | Required: {}
|
heartbeatPeriodSeconds integer | How often (in seconds) for the member cluster to send a heartbeat to the hub cluster. Default: 60 seconds. Min: 1 second. Max: 10 minutes. | 60 | Maximum: 600
Minimum: 1
Optional: {}
|
InternalMemberClusterStatus
InternalMemberClusterStatus defines the observed state of InternalMemberCluster.
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions is an array of current observed conditions for the member cluster. | | Optional: {}
|
properties object (keys:PropertyName, values:PropertyValue) | Properties is an array of properties observed for the member cluster.
This field is beta-level; it is for the property-based scheduling feature and is only
populated when a property provider is enabled in the deployment. | | Optional: {}
|
resourceUsage ResourceUsage | The current observed resource usage of the member cluster. It is populated by the member agent. | | Optional: {}
|
agentStatus AgentStatus array | AgentStatus is an array of current observed status, each corresponding to one member agent running in the member cluster. | | Optional: {}
|
MemberCluster
MemberCluster is a resource created in the hub cluster to represent a member cluster within a fleet.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | cluster.kubernetes-fleet.io/v1 | | |
kind string | MemberCluster | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec MemberClusterSpec | The desired state of MemberCluster. | | Required: {}
|
status MemberClusterStatus | The observed status of MemberCluster. | | Optional: {}
|
MemberClusterList
MemberClusterList contains a list of MemberCluster.
| Field | Description | Default | Validation |
|---|
apiVersion string | cluster.kubernetes-fleet.io/v1 | | |
kind string | MemberClusterList | | |
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
items MemberCluster array | | | |
MemberClusterSpec
MemberClusterSpec defines the desired state of MemberCluster.
Appears in:
| Field | Description | Default | Validation |
|---|
identity Subject | The identity used by the member cluster to access the hub cluster.
The hub agents deployed on the hub cluster will automatically grant the minimal required permissions to this identity for the member agents deployed on the member cluster to access the hub cluster. | | Required: {}
|
heartbeatPeriodSeconds integer | How often (in seconds) for the member cluster to send a heartbeat to the hub cluster. Default: 60 seconds. Min: 1 second. Max: 10 minutes. | 60 | Maximum: 600
Minimum: 1
Optional: {}
|
taints Taint array | If specified, the MemberCluster’s taints.
This field is beta-level and is for the taints and tolerations feature. | | MaxItems: 100
Optional: {}
|
MemberClusterStatus
MemberClusterStatus defines the observed status of MemberCluster.
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions is an array of current observed conditions for the member cluster. | | Optional: {}
|
properties object (keys:PropertyName, values:PropertyValue) | Properties is an array of properties observed for the member cluster.
This field is beta-level; it is for the property-based scheduling feature and is only
populated when a property provider is enabled in the deployment. | | Optional: {}
|
resourceUsage ResourceUsage | The current observed resource usage of the member cluster. It is copied from the corresponding InternalMemberCluster object. | | Optional: {}
|
agentStatus AgentStatus array | AgentStatus is an array of current observed status, each corresponding to one member agent running in the member cluster. | | Optional: {}
|
PropertyName
Underlying type: string
PropertyName is the name of a cluster property.
A valid name should be a string of one or more segments, separated by slashes (/) if applicable.
Each segment must be 63 characters or less, start and end with an alphanumeric character,
and can include dashes (-), underscores (_), dots (.), and alphanumerics in between.
Optionally, the property name can have a prefix, which must be a DNS subdomain up to 253 characters,
followed by a slash (/).
Examples include:
- “avg-resource-pressure”
- “kubernetes-fleet.io/node-count”
- “kubernetes.azure.com/vm-sizes/Standard_D2s_v3/count”
Appears in:
PropertyValue
PropertyValue is the value of a cluster property.
Appears in:
ResourceUsage
ResourceUsage contains the observed resource usage of a member cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
capacity ResourceList | Capacity represents the total resource capacity of all the nodes on a member cluster.
A node’s total capacity is the amount of resource installed on the node. | | Optional: {}
|
allocatable ResourceList | Allocatable represents the total allocatable resources of all the nodes on a member cluster.
A node’s allocatable capacity is the amount of resource that can actually be used
for user workloads, i.e.,
allocatable capacity = total capacity - capacities reserved for the OS, kubelet, etc.
For more information, see
https://kubernetes.io/docs/tasks/administer-cluster/reserve-compute-resources/. | | Optional: {}
|
available ResourceList | Available represents the total available resources of all the nodes on a member cluster.
A node’s available capacity is the amount of resource that has not been used yet, i.e.,
available capacity = allocatable capacity - capacity that has been requested by workloads.
This field is beta-level; it is for the property-based scheduling feature and is only
populated when a property provider is enabled in the deployment. | | Optional: {}
|
observationTime Time | When the resource usage is observed. | | Optional: {}
|
Taint
Taint attached to MemberCluster has the “effect” on
any ClusterResourcePlacement that does not tolerate the Taint.
Appears in:
| Field | Description | Default | Validation |
|---|
key string | The taint key to be applied to a MemberCluster. | | Required: {}
|
value string | The taint value corresponding to the taint key. | | Optional: {}
|
effect TaintEffect | The effect of the taint on ClusterResourcePlacements that do not tolerate the taint.
Only NoSchedule is supported. | | Enum: [NoSchedule]
Required: {}
|
7.2 - cluster.kubernetes-fleet.io/v1beta1
API Reference
Packages
cluster.kubernetes-fleet.io/v1beta1
Resource Types
AgentStatus
AgentStatus defines the observed status of the member agent of the given type.
Appears in:
| Field | Description | Default | Validation |
|---|
type AgentType | Type of the member agent. | | Required: {}
|
conditions Condition array | Conditions is an array of current observed conditions for the member agent. | | Optional: {}
|
lastReceivedHeartbeat Time | Last time we received a heartbeat from the member agent. | | Optional: {}
|
AgentType
Underlying type: string
AgentType defines a type of agent/binary running in a member cluster.
Appears in:
| Field | Description |
|---|
MemberAgent | MemberAgent (core) handles member cluster joining/leaving as well as k8s object placement from hub to member clusters.
|
MultiClusterServiceAgent | MultiClusterServiceAgent (networking) is responsible for exposing multi-cluster services via L4 load
balancer.
|
ServiceExportImportAgent | ServiceExportImportAgent (networking) is responsible for export or import services across multi-clusters.
|
ClusterState
Underlying type: string
Appears in:
| Field | Description |
|---|
Join | |
Leave | |
DeleteOptions
Appears in:
| Field | Description | Default | Validation |
|---|
validationMode DeleteValidationMode | Mode of validation. Can be “Skip”, or “Strict”. Default is Strict. | Strict | Enum: [Skip Strict]
Optional: {}
|
DeleteValidationMode
Underlying type: string
DeleteValidationMode identifies the type of validation when deleting a MemberCluster.
Appears in:
InternalMemberCluster
InternalMemberCluster is used by hub agent to notify the member agents about the member cluster state changes, and is used by the member agents to report their status.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | cluster.kubernetes-fleet.io/v1beta1 | | |
kind string | InternalMemberCluster | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec InternalMemberClusterSpec | The desired state of InternalMemberCluster. | | Required: {}
|
status InternalMemberClusterStatus | The observed status of InternalMemberCluster. | | Optional: {}
|
InternalMemberClusterList
InternalMemberClusterList contains a list of InternalMemberCluster.
| Field | Description | Default | Validation |
|---|
apiVersion string | cluster.kubernetes-fleet.io/v1beta1 | | |
kind string | InternalMemberClusterList | | |
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
items InternalMemberCluster array | | | |
InternalMemberClusterSpec
InternalMemberClusterSpec defines the desired state of InternalMemberCluster. Set by the hub agent.
Appears in:
| Field | Description | Default | Validation |
|---|
state ClusterState | The desired state of the member cluster. Possible values: Join, Leave. | | Required: {}
|
heartbeatPeriodSeconds integer | How often (in seconds) for the member cluster to send a heartbeat to the hub cluster. Default: 60 seconds. Min: 1 second. Max: 10 minutes. | 60 | Maximum: 600
Minimum: 1
Optional: {}
|
InternalMemberClusterStatus
InternalMemberClusterStatus defines the observed state of InternalMemberCluster.
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions is an array of current observed conditions for the member cluster. | | Optional: {}
|
properties object (keys:PropertyName, values:PropertyValue) | Properties is an array of properties observed for the member cluster.
This field is beta-level; it is for the property-based scheduling feature and is only
populated when a property provider is enabled in the deployment. | | Optional: {}
|
resourceUsage ResourceUsage | The current observed resource usage of the member cluster. It is populated by the member agent. | | Optional: {}
|
namespaces object (keys:string, values:string) | Namespaces is a map of namespace names to their associated work names for namespaces
that are managed by Fleet (i.e., have AppliedWork owner references when created).
The key is the namespace name and the value is the work name from the AppliedWork owner reference.
If the namespace does not have an AppliedWork owner reference, the value will be an empty string.
This field is populated by the property provider when namespace collection is enabled. | | Optional: {}
|
agentStatus AgentStatus array | AgentStatus is an array of current observed status, each corresponding to one member agent running in the member cluster. | | Optional: {}
|
MemberCluster
MemberCluster is a resource created in the hub cluster to represent a member cluster within a fleet.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | cluster.kubernetes-fleet.io/v1beta1 | | |
kind string | MemberCluster | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec MemberClusterSpec | The desired state of MemberCluster. | | Required: {}
|
status MemberClusterStatus | The observed status of MemberCluster. | | Optional: {}
|
MemberClusterList
MemberClusterList contains a list of MemberCluster.
| Field | Description | Default | Validation |
|---|
apiVersion string | cluster.kubernetes-fleet.io/v1beta1 | | |
kind string | MemberClusterList | | |
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
items MemberCluster array | | | |
MemberClusterSpec
MemberClusterSpec defines the desired state of MemberCluster.
Appears in:
| Field | Description | Default | Validation |
|---|
identity Subject | The identity used by the member cluster to access the hub cluster.
The hub agents deployed on the hub cluster will automatically grant the minimal required permissions to this identity for the member agents deployed on the member cluster to access the hub cluster. | | Required: {}
|
heartbeatPeriodSeconds integer | How often (in seconds) for the member cluster to send a heartbeat to the hub cluster. Default: 60 seconds. Min: 1 second. Max: 10 minutes. | 60 | Maximum: 600
Minimum: 1
Optional: {}
|
taints Taint array | If specified, the MemberCluster’s taints.
This field is beta-level and is for the taints and tolerations feature. | | MaxItems: 100
Optional: {}
|
deleteOptions DeleteOptions | DeleteOptions for deleting the MemberCluster. | | Optional: {}
|
MemberClusterStatus
MemberClusterStatus defines the observed status of MemberCluster.
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions is an array of current observed conditions for the member cluster. | | Optional: {}
|
properties object (keys:PropertyName, values:PropertyValue) | Properties is an array of properties observed for the member cluster.
This field is beta-level; it is for the property-based scheduling feature and is only
populated when a property provider is enabled in the deployment. | | Optional: {}
|
resourceUsage ResourceUsage | The current observed resource usage of the member cluster. It is copied from the corresponding InternalMemberCluster object. | | Optional: {}
|
namespaces object (keys:string, values:string) | Namespaces is a map of namespace names to their associated work names for namespaces
that are managed by Fleet (i.e., have AppliedWork owner references when created).
The key is the namespace name and the value is the work name from the AppliedWork owner reference.
If the namespace does not have an AppliedWork owner reference, the value will be an empty string.
This field is copied from the corresponding InternalMemberCluster object. | | Optional: {}
|
agentStatus AgentStatus array | AgentStatus is an array of current observed status, each corresponding to one member agent running in the member cluster. | | Optional: {}
|
PropertyName
Underlying type: string
PropertyName is the name of a cluster property; it should be a Kubernetes label name.
Appears in:
PropertyValue
PropertyValue is the value of a cluster property.
Appears in:
ResourceUsage
ResourceUsage contains the observed resource usage of a member cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
capacity ResourceList | Capacity represents the total resource capacity of all the nodes on a member cluster.
A node’s total capacity is the amount of resource installed on the node. | | Optional: {}
|
allocatable ResourceList | Allocatable represents the total allocatable resources of all the nodes on a member cluster.
A node’s allocatable capacity is the amount of resource that can actually be used
for user workloads, i.e.,
allocatable capacity = total capacity - capacities reserved for the OS, kubelet, etc.
For more information, see
https://kubernetes.io/docs/tasks/administer-cluster/reserve-compute-resources/. | | Optional: {}
|
available ResourceList | Available represents the total available resources of all the nodes on a member cluster.
A node’s available capacity is the amount of resource that has not been used yet, i.e.,
available capacity = allocatable capacity - capacity that has been requested by workloads.
This field is beta-level; it is for the property-based scheduling feature and is only
populated when a property provider is enabled in the deployment. | | Optional: {}
|
observationTime Time | When the resource usage is observed. | | Optional: {}
|
Taint
Taint attached to MemberCluster has the “effect” on
any ClusterResourcePlacement that does not tolerate the Taint.
Appears in:
| Field | Description | Default | Validation |
|---|
key string | The taint key to be applied to a MemberCluster. | | Required: {}
|
value string | The taint value corresponding to the taint key. | | Optional: {}
|
effect TaintEffect | The effect of the taint on ClusterResourcePlacements that do not tolerate the taint.
Only NoSchedule is supported. | | Enum: [NoSchedule]
Required: {}
|
7.3 - placement.kubernetes-fleet.io/v1
API Reference
Packages
placement.kubernetes-fleet.io/v1
Resource Types
Affinity
Affinity is a group of cluster affinity scheduling rules. More to be added.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterAffinity ClusterAffinity | ClusterAffinity contains cluster affinity scheduling rules for the selected resources. | | Optional: {}
|
AppliedResourceMeta represents the group, version, resource, name and namespace of a resource.
Since these resources have been created, they must have valid group, version, resource, namespace, and name.
Appears in:
| Field | Description | Default | Validation |
|---|
ordinal integer | Ordinal represents an index in manifests list, so the condition can still be linked
to a manifest even though manifest cannot be parsed successfully. | | |
group string | Group is the group of the resource. | | |
version string | Version is the version of the resource. | | |
kind string | Kind is the kind of the resource. | | |
resource string | Resource is the resource type of the resource | | |
namespace string | Namespace is the namespace of the resource, the resource is cluster scoped if the value
is empty | | |
name string | Name is the name of the resource | | |
uid UID | UID is set on successful deletion of the Kubernetes resource by controller. The
resource might be still visible on the managed cluster after this field is set.
It is not directly settable by a client. | | Optional: {}
|
AppliedWork
AppliedWork represents an applied work on managed cluster that is placed
on a managed cluster. An appliedwork links to a work on a hub recording resources
deployed in the managed cluster.
When the agent is removed from managed cluster, cluster-admin on managed cluster
can delete appliedwork to remove resources deployed by the agent.
The name of the appliedwork must be the same as {work name}
The namespace of the appliedwork should be the same as the resource applied on
the managed cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | AppliedWork | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec AppliedWorkSpec | Spec represents the desired configuration of AppliedWork. | | Required: {}
Required: {}
|
status AppliedWorkStatus | Status represents the current status of AppliedWork. | | Optional: {}
|
AppliedWorkList
AppliedWorkList contains a list of AppliedWork.
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | AppliedWorkList | | |
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | | Optional: {}
|
items AppliedWork array | List of works. | | |
AppliedWorkSpec
AppliedWorkSpec represents the desired configuration of AppliedWork.
Appears in:
| Field | Description | Default | Validation |
|---|
workName string | WorkName represents the name of the related work on the hub. | | Required: {}
Required: {}
|
workNamespace string | WorkNamespace represents the namespace of the related work on the hub. | | Required: {}
Required: {}
|
AppliedWorkStatus
AppliedWorkStatus represents the current status of AppliedWork.
Appears in:
| Field | Description | Default | Validation |
|---|
appliedResources AppliedResourceMeta array | AppliedResources represents a list of resources defined within the Work that are applied.
Only resources with valid GroupVersionResource, namespace, and name are suitable.
An item in this slice is deleted when there is no mapped manifest in Work.Spec or by finalizer.
The resource relating to the item will also be removed from managed cluster.
The deleted resource may still be present until the finalizers for that resource are finished.
However, the resource will not be undeleted, so it can be removed from this list and eventual consistency is preserved. | | Optional: {}
|
ApplyStrategy
ApplyStrategy describes how to resolve the conflict if the resource to be placed already exists in the target cluster
and whether it’s allowed to be co-owned by other non-fleet appliers.
Note: If multiple CRPs try to place the same resource with different apply strategy, the later ones will fail with the
reason ApplyConflictBetweenPlacements.
Appears in:
| Field | Description | Default | Validation |
|---|
comparisonOption ComparisonOptionType | ComparisonOption controls how Fleet compares the desired state of a resource, as kept in
a hub cluster manifest, with the current state of the resource (if applicable) in the
member cluster.
Available options are:
* PartialComparison: with this option, Fleet will compare only fields that are managed by
Fleet, i.e., the fields that are specified explicitly in the hub cluster manifest.
Unmanaged fields are ignored. This is the default option.
* FullComparison: with this option, Fleet will compare all fields of the resource,
even if the fields are absent from the hub cluster manifest.
Consider using the PartialComparison option if you would like to:
* use the default values for certain fields; or
* let another agent, e.g., HPAs, VPAs, etc., on the member cluster side manage some fields; or
* allow ad-hoc or cluster-specific settings on the member cluster side.
To use the FullComparison option, it is recommended that you:
* specify all fields as appropriate in the hub cluster, even if you are OK with using default
values;
* make sure that no fields are managed by agents other than Fleet on the member cluster
side, such as HPAs, VPAs, or other controllers.
See the Fleet documentation for further explanations and usage examples. | PartialComparison | Enum: [PartialComparison FullComparison]
Optional: {}
|
whenToApply WhenToApplyType | WhenToApply controls when Fleet would apply the manifests on the hub cluster to the member
clusters.
Available options are:
* Always: with this option, Fleet will periodically apply hub cluster manifests
on the member cluster side; this will effectively overwrite any change in the fields
managed by Fleet (i.e., specified in the hub cluster manifest). This is the default
option.
Note that this option would revert any ad-hoc changes made on the member cluster side in the
managed fields; if you would like to make temporary edits on the member cluster side
in the managed fields, switch to IfNotDrifted option. Note that changes in unmanaged
fields will be left alone; if you use the FullDiff compare option, such changes will
be reported as drifts.
* IfNotDrifted: with this option, Fleet will stop applying hub cluster manifests on
clusters that have drifted from the desired state; apply ops would still continue on
the rest of the clusters. Drifts are calculated using the ComparisonOption,
as explained in the corresponding field.
Use this option if you would like Fleet to detect drifts in your multi-cluster setup.
A drift occurs when an agent makes an ad-hoc change on the member cluster side that
makes affected resources deviate from its desired state as kept in the hub cluster;
and this option grants you an opportunity to view the drift details and take actions
accordingly. The drift details will be reported in the CRP status.
To fix a drift, you may:
* revert the changes manually on the member cluster side
* update the hub cluster manifest; this will trigger Fleet to apply the latest revision
of the manifests, which will overwrite the drifted fields
(if they are managed by Fleet)
* switch to the Always option; this will trigger Fleet to apply the current revision
of the manifests, which will overwrite the drifted fields (if they are managed by Fleet).
* if applicable and necessary, delete the drifted resources on the member cluster side; Fleet
will attempt to re-create them using the hub cluster manifests | Always | Enum: [Always IfNotDrifted]
Optional: {}
|
type ApplyStrategyType | Type is the apply strategy to use; it determines how Fleet applies manifests from the
hub cluster to a member cluster.
Available options are:
* ClientSideApply: Fleet uses three-way merge to apply manifests, similar to how kubectl
performs a client-side apply. This is the default option.
Note that this strategy requires that Fleet keep the last applied configuration in the
annotation of an applied resource. If the object gets so large that apply ops can no longer
be executed, Fleet will switch to server-side apply.
Use ComparisonOption and WhenToApply settings to control when an apply op can be executed.
* ServerSideApply: Fleet uses server-side apply to apply manifests; Fleet itself will
become the field manager for specified fields in the manifests. Specify
ServerSideApplyConfig as appropriate if you would like Fleet to take over field
ownership upon conflicts. This is the recommended option for most scenarios; it might
help reduce object size and safely resolve conflicts between field values. For more
information, please refer to the Kubernetes documentation
(https://kubernetes.io/docs/reference/using-api/server-side-apply/#comparison-with-client-side-apply).
Use ComparisonOption and WhenToApply settings to control when an apply op can be executed.
* ReportDiff: Fleet will compare the desired state of a resource as kept in the hub cluster
with its current state (if applicable) on the member cluster side, and report any
differences. No actual apply ops would be executed, and resources will be left alone as they
are on the member clusters.
If configuration differences are found on a resource, Fleet will consider this as an apply
error, which might block rollout depending on the specified rollout strategy.
Use ComparisonOption setting to control how the difference is calculated.
ClientSideApply and ServerSideApply apply strategies only work when Fleet can assume
ownership of a resource (e.g., the resource is created by Fleet, or Fleet has taken over
the resource). See the comments on the WhenToTakeOver field for more information.
ReportDiff apply strategy, however, will function regardless of Fleet’s ownership
status. One may set up a CRP with the ReportDiff strategy and the Never takeover option,
and this will turn Fleet into a detection tool that reports only configuration differences
but do not touch any resources on the member cluster side.
For a comparison between the different strategies and usage examples, refer to the
Fleet documentation. | ClientSideApply | Enum: [ClientSideApply ServerSideApply ReportDiff]
Optional: {}
|
allowCoOwnership boolean | AllowCoOwnership controls whether co-ownership between Fleet and other agents are allowed
on a Fleet-managed resource. If set to false, Fleet will refuse to apply manifests to
a resource that has been owned by one or more non-Fleet agents.
Note that Fleet does not support the case where one resource is being placed multiple
times by different CRPs on the same member cluster. An apply error will be returned if
Fleet finds that a resource has been owned by another placement attempt by Fleet, even
with the AllowCoOwnership setting set to true. | | |
serverSideApplyConfig ServerSideApplyConfig | ServerSideApplyConfig defines the configuration for server side apply. It is honored only when type is ServerSideApply. | | Optional: {}
|
whenToTakeOver WhenToTakeOverType | WhenToTakeOver determines the action to take when Fleet applies resources to a member
cluster for the first time and finds out that the resource already exists in the cluster.
This setting is most relevant in cases where you would like Fleet to manage pre-existing
resources on a member cluster.
Available options include:
* Always: with this action, Fleet will apply the hub cluster manifests to the member
clusters even if the affected resources already exist. This is the default action.
Note that this might lead to fields being overwritten on the member clusters, if they
are specified in the hub cluster manifests.
* IfNoDiff: with this action, Fleet will apply the hub cluster manifests to the member
clusters if (and only if) pre-existing resources look the same as the hub cluster manifests.
This is a safer option as pre-existing resources that are inconsistent with the hub cluster
manifests will not be overwritten; Fleet will ignore them until the inconsistencies
are resolved properly: any change you make to the hub cluster manifests would not be
applied, and if you delete the manifests or even the ClusterResourcePlacement itself
from the hub cluster, these pre-existing resources would not be taken away.
Fleet will check for inconsistencies in accordance with the ComparisonOption setting. See also
the comments on the ComparisonOption field for more information.
If a diff has been found in a field that is managed by Fleet (i.e., the field
*is specified ** in the hub cluster manifest), consider one of the following actions:
* set the field in the member cluster to be of the same value as that in the hub cluster
manifest.
* update the hub cluster manifest so that its field value matches with that in the member
cluster.
* switch to the Always action, which will allow Fleet to overwrite the field with the
value in the hub cluster manifest.
If a diff has been found in a field that is not managed by Fleet (i.e., the field
is not specified in the hub cluster manifest), consider one of the following actions:
* remove the field from the member cluster.
* update the hub cluster manifest so that the field is included in the hub cluster manifest.
If appropriate, you may also delete the object from the member cluster; Fleet will recreate
it using the hub cluster manifest.
Never: with this action, Fleet will not apply a hub cluster manifest to the member
clusters if there is a corresponding pre-existing resource. However, if a manifest
has never been applied yet; or it has a corresponding resource which Fleet has assumed
ownership, apply op will still be executed.
This is the safest option; one will have to remove the pre-existing resources (so that
Fleet can re-create them) or switch to a different
WhenToTakeOver option before Fleet starts processing the corresponding hub cluster
manifests.
If you prefer Fleet stop processing all manifests, use this option along with the
ReportDiff apply strategy type. This setup would instruct Fleet to touch nothing
on the member cluster side but still report configuration differences between the
hub cluster and member clusters. Fleet will not give up ownership
that it has already assumed though. | Always | Enum: [Always IfNoDiff Never]
Optional: {}
|
ApplyStrategyType
Underlying type: string
ApplyStrategyType describes the type of the strategy used to apply the resource to the target cluster.
Appears in:
| Field | Description |
|---|
ClientSideApply | ApplyStrategyTypeClientSideApply will use three-way merge patch similar to how kubectl apply does by storing
last applied state in the last-applied-configuration annotation.
When the last-applied-configuration annotation size is greater than 256kB, it falls back to the server-side apply.
|
ServerSideApply | ApplyStrategyTypeServerSideApply will use server-side apply to resolve conflicts between the resource to be placed
and the existing resource in the target cluster.
Details: https://kubernetes.io/docs/reference/using-api/server-side-apply
|
ReportDiff | ApplyStrategyTypeReportDiff will report differences between the desired state of a
resource as kept in the hub cluster and its current state (if applicable) on the member
cluster side. No actual apply ops would be executed.
|
ApprovalRequest
ApprovalRequest defines a request for user approval for staged update run.
The request object MUST have the following labels:
TargetUpdateRun: Points to the staged update run that this approval request is for.TargetStage: The name of the stage that this approval request is for.IsLatestUpdateRunApproval: Indicates whether this approval request is the latest one related to this update run.TaskType: Indicates whether this approval request is for the before or after stage task.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ApprovalRequest | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ApprovalRequestSpec | The desired state of ApprovalRequest. | | Required: {}
|
status ApprovalRequestStatus | The observed state of ApprovalRequest. | | Optional: {}
|
ApprovalRequestSpec
ApprovalRequestSpec defines the desired state of the update run approval request.
The entire spec is immutable.
Appears in:
| Field | Description | Default | Validation |
|---|
parentStageRollout string | The name of the staged update run that this approval request is for. | | Required: {}
|
targetStage string | The name of the update stage that this approval request is for. | | Required: {}
|
ApprovalRequestStatus
ApprovalRequestStatus defines the observed state of the ClusterApprovalRequest.
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions is an array of current observed conditions for the specific type of post-update task.
Known conditions are “Approved” and “ApprovalAccepted”. | | Optional: {}
|
BindingState
Underlying type: string
BindingState is the state of the binding.
Appears in:
| Field | Description |
|---|
Scheduled | BindingStateScheduled means the binding is scheduled but need to be bound to the target cluster.
|
Bound | BindingStateBound means the binding is bound to the target cluster.
|
Unscheduled | BindingStateUnscheduled means the binding is not scheduled on to the target cluster anymore.
This is a state that rollout controller cares about.
The work generator still treat this as bound until rollout controller deletes the binding.
|
ClusterAffinity
ClusterAffinity contains cluster affinity scheduling rules for the selected resources.
Appears in:
| Field | Description | Default | Validation |
|---|
requiredDuringSchedulingIgnoredDuringExecution ClusterSelector | If the affinity requirements specified by this field are not met at
scheduling time, the resource will not be scheduled onto the cluster.
If the affinity requirements specified by this field cease to be met
at some point after the placement (e.g. due to an update), the system
may or may not try to eventually remove the resource from the cluster. | | Optional: {}
|
preferredDuringSchedulingIgnoredDuringExecution PreferredClusterSelector array | The scheduler computes a score for each cluster at schedule time by iterating
through the elements of this field and adding “weight” to the sum if the cluster
matches the corresponding matchExpression. The scheduler then chooses the first
N clusters with the highest sum to satisfy the placement.
This field is ignored if the placement type is “PickAll”.
If the cluster score changes at some point after the placement (e.g. due to an update),
the system may or may not try to eventually move the resource from a cluster with a lower score
to a cluster with higher score. | | Optional: {}
|
ClusterApprovalRequest
ClusterApprovalRequest defines a request for user approval for cluster staged update run.
The request object MUST have the following labels:
TargetUpdateRun: Points to the cluster staged update run that this approval request is for.TargetStage: The name of the stage that this approval request is for.IsLatestUpdateRunApproval: Indicates whether this approval request is the latest one related to this update run.TaskType: Indicates whether this approval request is for the before or after stage task.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ClusterApprovalRequest | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ApprovalRequestSpec | The desired state of ClusterApprovalRequest. | | Required: {}
|
status ApprovalRequestStatus | The observed state of ClusterApprovalRequest. | | Optional: {}
|
ClusterDecision
ClusterDecision represents a decision from a placement
An empty ClusterDecision indicates it is not scheduled yet.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterName string | ClusterName is the name of the ManagedCluster. If it is not empty, its value should be unique cross all
placement decisions for the Placement. | | Required: {}
Required: {}
|
selected boolean | Selected indicates if this cluster is selected by the scheduler. | | Required: {}
|
clusterScore ClusterScore | ClusterScore represents the score of the cluster calculated by the scheduler. | | Optional: {}
|
reason string | Reason represents the reason why the cluster is selected or not. | | Required: {}
|
ClusterResourceBinding
ClusterResourceBinding represents a scheduling decision that binds a group of resources to a cluster.
It MUST have a label named CRPTrackingLabel that points to the cluster resource policy that creates it.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ClusterResourceBinding | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceBindingSpec | The desired state of ClusterResourceBinding. | | Required: {}
|
status ResourceBindingStatus | The observed status of ClusterResourceBinding. | | Optional: {}
|
ClusterResourceOverride
ClusterResourceOverride defines a group of override policies about how to override the selected cluster scope resources
to target clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ClusterResourceOverride | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ClusterResourceOverrideSpec | The desired state of ClusterResourceOverrideSpec. | | Required: {}
|
ClusterResourceOverrideSnapshot
ClusterResourceOverrideSnapshot is used to store a snapshot of ClusterResourceOverride.
Its spec is immutable.
We assign an ever-increasing index for snapshots.
The naming convention of a ClusterResourceOverrideSnapshot is {ClusterResourceOverride}-{resourceIndex}.
resourceIndex will begin with 0.
Each snapshot MUST have the following labels:
OverrideTrackingLabel which points to its owner ClusterResourceOverride.IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ClusterResourceOverrideSnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ClusterResourceOverrideSnapshotSpec | The desired state of ClusterResourceOverrideSnapshotSpec. | | Required: {}
|
ClusterResourceOverrideSnapshotSpec
ClusterResourceOverrideSnapshotSpec defines the desired state of ClusterResourceOverride.
Appears in:
| Field | Description | Default | Validation |
|---|
overrideSpec ClusterResourceOverrideSpec | OverrideSpec stores the spec of ClusterResourceOverride. | | |
overrideHash integer array | OverrideHash is the sha-256 hash value of the OverrideSpec field. | | Required: {}
|
ClusterResourceOverrideSpec
ClusterResourceOverrideSpec defines the desired state of the Override.
The ClusterResourceOverride create or update will fail when the resource has been selected by the existing ClusterResourceOverride.
If the resource is selected by both ClusterResourceOverride and ResourceOverride, ResourceOverride will win when resolving
conflicts.
Appears in:
| Field | Description | Default | Validation |
|---|
placement PlacementRef | Placement defines whether the override is applied to a specific placement or not.
If set, the override will trigger the placement rollout immediately when the rollout strategy type is RollingUpdate.
Otherwise, it will be applied to the next rollout.
The recommended way is to set the placement so that the override can be rolled out immediately. | | Optional: {}
|
clusterResourceSelectors ClusterResourceSelector array | ClusterResourceSelectors is an array of selectors used to select cluster scoped resources. The selectors are ORed.
If a namespace is selected, ALL the resources under the namespace are selected automatically.
LabelSelector is not supported.
You can have 1-20 selectors.
We only support Name selector for now. | | MaxItems: 20
MinItems: 1
Required: {}
Required: {}
|
policy OverridePolicy | Policy defines how to override the selected resources on the target clusters. | | Required: {}
|
ClusterResourcePlacement
ClusterResourcePlacement is used to select cluster scoped resources, including built-in resources and custom resources,
and placement them onto selected member clusters in a fleet.
If a namespace is selected, ALL the resources under the namespace are placed to the target clusters.
Note that you can’t select the following resources:
- reserved namespaces including: default, kube-* (reserved for Kubernetes system namespaces),
fleet-* (reserved for fleet system namespaces).
- reserved fleet resource types including: MemberCluster, InternalMemberCluster, ClusterResourcePlacement,
ClusterSchedulingPolicySnapshot, ClusterResourceSnapshot, ClusterResourceBinding, etc.
ClusterSchedulingPolicySnapshot and ClusterResourceSnapshot objects are created when there are changes in the
system to keep the history of the changes affecting a ClusterResourcePlacement.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ClusterResourcePlacement | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ClusterResourcePlacementSpec | The desired state of ClusterResourcePlacement. | | Required: {}
|
status ClusterResourcePlacementStatus | The observed status of ClusterResourcePlacement. | | Optional: {}
|
ClusterResourcePlacementSpec
ClusterResourcePlacementSpec defines the desired state of ClusterResourcePlacement.
Appears in:
| Field | Description | Default | Validation |
|---|
resourceSelectors ClusterResourceSelector array | ResourceSelectors is an array of selectors used to select cluster scoped resources. The selectors are ORed.
You can have 1-100 selectors. | | MaxItems: 100
MinItems: 1
Required: {}
|
policy PlacementPolicy | Policy defines how to select member clusters to place the selected resources.
If unspecified, all the joined member clusters are selected. | | Optional: {}
|
strategy RolloutStrategy | The rollout strategy to use to replace existing placement with new ones. | | Optional: {}
|
revisionHistoryLimit integer | The number of old ClusterSchedulingPolicySnapshot or ClusterResourceSnapshot resources to retain to allow rollback.
This is a pointer to distinguish between explicit zero and not specified.
Defaults to 10. | 10 | Maximum: 1000
Minimum: 1
Optional: {}
|
ClusterResourcePlacementStatus
ClusterResourcePlacementStatus defines the observed state of the ClusterResourcePlacement object.
Appears in:
| Field | Description | Default | Validation |
|---|
selectedResources ResourceIdentifier array | SelectedResources contains a list of resources selected by ResourceSelectors. | | Optional: {}
|
observedResourceIndex string | Resource index logically represents the generation of the selected resources.
We take a new snapshot of the selected resources whenever the selection or their content change.
Each snapshot has a different resource index.
One resource snapshot can contain multiple clusterResourceSnapshots CRs in order to store large amount of resources.
To get clusterResourceSnapshot of a given resource index, use the following command:
kubectl get ClusterResourceSnapshot --selector=kubernetes-fleet.io/resource-index=$ObservedResourceIndex
ObservedResourceIndex is the resource index that the conditions in the ClusterResourcePlacementStatus observe.
For example, a condition of ClusterResourcePlacementWorkSynchronized type
is observing the synchronization status of the resource snapshot with the resource index $ObservedResourceIndex. | | Optional: {}
|
placementStatuses ResourcePlacementStatus array | PlacementStatuses contains a list of placement status on the clusters that are selected by PlacementPolicy.
Each selected cluster according to the latest resource placement is guaranteed to have a corresponding placementStatuses.
In the pickN case, there are N placement statuses where N = NumberOfClusters; Or in the pickFixed case, there are
N placement statuses where N = ClusterNames.
In these cases, some of them may not have assigned clusters when we cannot fill the required number of clusters. | | Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for ClusterResourcePlacement. | | Optional: {}
|
ClusterResourceSelector
ClusterResourceSelector is used to select cluster scoped resources as the target resources to be placed.
If a namespace is selected, ALL the resources under the namespace are selected automatically.
All the fields are ANDed. In other words, a resource must match all the fields to be selected.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group name of the cluster-scoped resource.
Use an empty string to select resources under the core API group (e.g., namespaces). | | Required: {}
|
version string | Version of the cluster-scoped resource. | | Required: {}
|
kind string | Kind of the cluster-scoped resource.
Note: When Kind is namespace, ALL the resources under the selected namespaces are selected. | | Required: {}
|
name string | Name of the cluster-scoped resource. | | Optional: {}
|
labelSelector LabelSelector | A label query over all the cluster-scoped resources. Resources matching the query are selected.
Note that namespace-scoped resources can’t be selected even if they match the query. | | Optional: {}
|
ClusterResourceSnapshot
ClusterResourceSnapshot is used to store a snapshot of selected resources by a resource placement policy.
Its spec is immutable.
We may need to produce more than one resourceSnapshot for all the resources a ResourcePlacement selected to get around the 1MB size limit of k8s objects.
We assign an ever-increasing index for each such group of resourceSnapshots.
The naming convention of a clusterResourceSnapshot is {CRPName}-{resourceIndex}-{subindex}
where the name of the first snapshot of a group has no subindex part so its name is {CRPName}-{resourceIndex}-snapshot.
resourceIndex will begin with 0.
Each snapshot MUST have the following labels:
CRPTrackingLabel which points to its owner CRP.ResourceIndexLabel which is the index of the snapshot group.
The first snapshot of the index group MAY have the following labels:
IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
All the snapshots within the same index group must have the same ResourceIndexLabel.
The first snapshot of the index group MUST have the following annotations:
NumberOfResourceSnapshotsAnnotation to store the total number of resource snapshots in the index group.ResourceGroupHashAnnotation whose value is the sha-256 hash of all the snapshots belong to the same snapshot index.
Each snapshot (excluding the first snapshot) MUST have the following annotations:
SubindexOfResourceSnapshotAnnotation to store the subindex of resource snapshot in the group.
Snapshot may have the following annotations to indicate the time of next resourceSnapshot candidate detected by the controller:
NextResourceSnapshotCandidateDetectionTimeAnnotation to store the time of next resourceSnapshot candidate detected by the controller.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ClusterResourceSnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceSnapshotSpec | The desired state of ResourceSnapshot. | | Required: {}
|
status ResourceSnapshotStatus | The observed status of ResourceSnapshot. | | Optional: {}
|
ClusterSchedulingPolicySnapshot
ClusterSchedulingPolicySnapshot is used to store a snapshot of cluster placement policy.
Its spec is immutable.
The naming convention of a ClusterSchedulingPolicySnapshot is {CRPName}-{PolicySnapshotIndex}.
PolicySnapshotIndex will begin with 0.
Each snapshot must have the following labels:
CRPTrackingLabel which points to its owner CRP.PolicyIndexLabel which is the index of the policy snapshot.IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ClusterSchedulingPolicySnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec SchedulingPolicySnapshotSpec | The desired state of SchedulingPolicySnapshot. | | Required: {}
|
status SchedulingPolicySnapshotStatus | The observed status of SchedulingPolicySnapshot. | | Optional: {}
|
ClusterScore
ClusterScore represents the score of the cluster calculated by the scheduler.
Appears in:
| Field | Description | Default | Validation |
|---|
affinityScore integer | AffinityScore represents the affinity score of the cluster calculated by the last
scheduling decision based on the preferred affinity selector.
An affinity score may not present if the cluster does not meet the required affinity. | | Optional: {}
|
priorityScore integer | TopologySpreadScore represents the priority score of the cluster calculated by the last
scheduling decision based on the topology spread applied to the cluster.
A priority score may not present if the cluster does not meet the topology spread. | | Optional: {}
|
ClusterSelector
Appears in:
| Field | Description | Default | Validation |
|---|
clusterSelectorTerms ClusterSelectorTerm array | ClusterSelectorTerms is a list of cluster selector terms. The terms are ORed. | | MaxItems: 10
Required: {}
|
ClusterSelectorTerm
Underlying type: struct{LabelSelector *k8s.io/apimachinery/pkg/apis/meta/v1.LabelSelector “json:"labelSelector,omitempty"”; PropertySelector *PropertySelector “json:"propertySelector,omitempty"”; PropertySorter *PropertySorter “json:"propertySorter,omitempty"”}
Appears in:
ClusterStagedUpdateRun
ClusterStagedUpdateRun represents a stage by stage update process that applies ClusterResourcePlacement
selected resources to specified clusters.
Resources from unselected clusters are removed after all stages in the update strategy are completed.
Each ClusterStagedUpdateRun object corresponds to a single release of a specific resource version.
The release is abandoned if the ClusterStagedUpdateRun object is deleted or the scheduling decision changes.
The name of the ClusterStagedUpdateRun must conform to RFC 1123.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ClusterStagedUpdateRun | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec UpdateRunSpec | The desired state of ClusterStagedUpdateRun. | | Required: {}
|
status UpdateRunStatus | The observed status of ClusterStagedUpdateRun. | | Optional: {}
|
ClusterStagedUpdateStrategy
ClusterStagedUpdateStrategy defines a reusable strategy that specifies the stages and the sequence
in which the selected cluster resources will be updated on the member clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ClusterStagedUpdateStrategy | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec UpdateStrategySpec | The desired state of ClusterStagedUpdateStrategy. | | Required: {}
|
ClusterUpdatingStatus
ClusterUpdatingStatus defines the status of the update run on a cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterName string | The name of the cluster. | | Required: {}
|
resourceOverrideSnapshots NamespacedName array | ResourceOverrideSnapshots is a list of ResourceOverride snapshots associated with the cluster.
The list is computed at the beginning of the update run and not updated during the update run.
The list is empty if there are no resource overrides associated with the cluster. | | Optional: {}
|
clusterResourceOverrideSnapshots string array | ClusterResourceOverrides contains a list of applicable ClusterResourceOverride snapshot names
associated with the cluster.
The list is computed at the beginning of the update run and not updated during the update run.
The list is empty if there are no cluster overrides associated with the cluster. | | Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for clusters. Empty if the cluster has not started updating.
Known conditions are “Started”, “Succeeded”. | | Optional: {}
|
ComparisonOptionType
Underlying type: string
ComparisonOptionType describes the compare option that Fleet uses to detect drifts and/or
calculate differences.
Appears in:
| Field | Description |
|---|
PartialComparison | ComparisonOptionTypePartialComparison will compare only fields that are managed by Fleet, i.e.,
fields that are specified explicitly in the hub cluster manifest. Unmanaged fields
are ignored.
|
FullComparison | ComparisonOptionTypeFullDiff will compare all fields of the resource, even if the fields
are absent from the hub cluster manifest.
|
DiffDetails
DiffDetails describes the observed configuration differences.
Appears in:
| Field | Description | Default | Validation |
|---|
observationTime Time | ObservationTime is the timestamp when the configuration difference was last detected. | | Format: date-time
Required: {}
Type: string
|
observedInMemberClusterGeneration integer | ObservedInMemberClusterGeneration is the generation of the applied manifest on the member
cluster side.
This might be nil if the resource has not been created yet in the member cluster. | | Optional: {}
|
firstDiffedObservedTime Time | FirstDiffedObservedTime is the timestamp when the configuration difference
was first detected. | | Format: date-time
Required: {}
Type: string
|
observedDiffs PatchDetail array | ObservedDiffs describes each field with configuration difference as found from the
member cluster side.
Fleet might truncate the details as appropriate to control object size.
Each entry specifies how the live state (the state on the member cluster side) compares
against the desired state (the state kept in the hub cluster manifest). | | Optional: {}
|
DiffedResourcePlacement
DiffedResourcePlacement contains the details of a resource with configuration differences.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group is the group name of the selected resource. | | Optional: {}
|
version string | Version is the version of the selected resource. | | Required: {}
|
kind string | Kind represents the Kind of the selected resources. | | Required: {}
|
name string | Name of the target resource. | | Required: {}
|
namespace string | Namespace is the namespace of the resource. Empty if the resource is cluster scoped. | | Optional: {}
|
envelope EnvelopeIdentifier | Envelope identifies the envelope object that contains this resource. | | Optional: {}
|
observationTime Time | ObservationTime is the time when we observe the configuration differences for the resource. | | Format: date-time
Required: {}
Type: string
|
targetClusterObservedGeneration integer | TargetClusterObservedGeneration is the generation of the resource on the target cluster
that contains the configuration differences.
This might be nil if the resource has not been created yet on the target cluster. | | Optional: {}
|
firstDiffedObservedTime Time | FirstDiffedObservedTime is the first time the resource on the target cluster is
observed to have configuration differences. | | Format: date-time
Required: {}
Type: string
|
observedDiffs PatchDetail array | ObservedDiffs are the details about the found configuration differences. Note that
Fleet might truncate the details as appropriate to control the object size.
Each detail entry specifies how the live state (the state on the member
cluster side) compares against the desired state (the state kept in the hub cluster manifest).
An event about the details will be emitted as well. | | Optional: {}
|
DriftDetails
DriftDetails describes the observed configuration drifts.
Appears in:
| Field | Description | Default | Validation |
|---|
observationTime Time | ObservationTime is the timestamp when the drift was last detected. | | Format: date-time
Required: {}
Type: string
|
observedInMemberClusterGeneration integer | ObservedInMemberClusterGeneration is the generation of the applied manifest on the member
cluster side. | | Required: {}
|
firstDriftedObservedTime Time | FirstDriftedObservedTime is the timestamp when the drift was first detected. | | Format: date-time
Required: {}
Type: string
|
observedDrifts PatchDetail array | ObservedDrifts describes each drifted field found from the applied manifest.
Fleet might truncate the details as appropriate to control object size.
Each entry specifies how the live state (the state on the member cluster side) compares
against the desired state (the state kept in the hub cluster manifest). | | Optional: {}
|
DriftedResourcePlacement
DriftedResourcePlacement contains the details of a resource with configuration drifts.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group is the group name of the selected resource. | | Optional: {}
|
version string | Version is the version of the selected resource. | | Required: {}
|
kind string | Kind represents the Kind of the selected resources. | | Required: {}
|
name string | Name of the target resource. | | Required: {}
|
namespace string | Namespace is the namespace of the resource. Empty if the resource is cluster scoped. | | Optional: {}
|
envelope EnvelopeIdentifier | Envelope identifies the envelope object that contains this resource. | | Optional: {}
|
observationTime Time | ObservationTime is the time when we observe the configuration drifts for the resource. | | Format: date-time
Required: {}
Type: string
|
targetClusterObservedGeneration integer | TargetClusterObservedGeneration is the generation of the resource on the target cluster
that contains the configuration drifts. | | Required: {}
|
firstDriftedObservedTime Time | FirstDriftedObservedTime is the first time the resource on the target cluster is
observed to have configuration drifts. | | Format: date-time
Required: {}
Type: string
|
observedDrifts PatchDetail array | ObservedDrifts are the details about the found configuration drifts. Note that
Fleet might truncate the details as appropriate to control the object size.
Each detail entry specifies how the live state (the state on the member
cluster side) compares against the desired state (the state kept in the hub cluster manifest).
An event about the details will be emitted as well. | | Optional: {}
|
EnvelopeIdentifier
EnvelopeIdentifier identifies the envelope object that contains the selected resource.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | Name of the envelope object. | | Required: {}
|
namespace string | Namespace is the namespace of the envelope object. Empty if the envelope object is cluster scoped. | | Optional: {}
|
type EnvelopeType | Type of the envelope object. | ConfigMap | Enum: [ConfigMap]
Optional: {}
|
EnvelopeType
Underlying type: string
EnvelopeType defines the type of the envelope object.
Appears in:
| Field | Description |
|---|
ConfigMap | ConfigMapEnvelopeType means the envelope object is of type ConfigMap.
|
FailedResourcePlacement
FailedResourcePlacement contains the failure details of a failed resource placement.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group is the group name of the selected resource. | | Optional: {}
|
version string | Version is the version of the selected resource. | | Required: {}
|
kind string | Kind represents the Kind of the selected resources. | | Required: {}
|
name string | Name of the target resource. | | Required: {}
|
namespace string | Namespace is the namespace of the resource. Empty if the resource is cluster scoped. | | Optional: {}
|
envelope EnvelopeIdentifier | Envelope identifies the envelope object that contains this resource. | | Optional: {}
|
condition Condition | The failed condition status. | | Required: {}
|
JSONPatchOverride
JSONPatchOverride applies a JSON patch on the selected resources following RFC 6902.
Appears in:
| Field | Description | Default | Validation |
|---|
op JSONPatchOverrideOperator | Operator defines the operation on the target field. | | Enum: [add remove replace]
Required: {}
|
path string | Path defines the target location.
Note: override will fail if the resource path does not exist. | | Required: {}
|
value JSON | Value defines the content to be applied on the target location.
Value should be empty when operator is remove.
We have reserved a few variables in this field that will be replaced by the actual values.
Those variables all start with $ and are case sensitive.
Here is the list of currently supported variables:
$\{MEMBER-CLUSTER-NAME\}: this will be replaced by the name of the memberCluster CR that represents this cluster. | | Optional: {}
|
JSONPatchOverrideOperator
Underlying type: string
JSONPatchOverrideOperator defines the supported JSON patch operator.
Appears in:
| Field | Description |
|---|
add | JSONPatchOverrideOpAdd adds the value to the target location.
An example target JSON document:
{ “foo”: [ “bar”, “baz” ] }
A JSON Patch override:
[
{ “op”: “add”, “path”: “/foo/1”, “value”: “qux” }
]
The resulting JSON document:
{ “foo”: [ “bar”, “qux”, “baz” ] }
|
remove | JSONPatchOverrideOpRemove removes the value from the target location.
An example target JSON document:
{
“baz”: “qux”,
“foo”: “bar”
}
A JSON Patch override:
[
{ “op”: “remove”, “path”: “/baz” }
]
The resulting JSON document:
{ “foo”: “bar” }
|
replace | JSONPatchOverrideOpReplace replaces the value at the target location with a new value.
An example target JSON document:
{
“baz”: “qux”,
“foo”: “bar”
}
A JSON Patch override:
[
{ “op”: “replace”, “path”: “/baz”, “value”: “boo” }
]
The resulting JSON document:
{
“baz”: “boo”,
“foo”: “bar”
}
|
Manifest
Manifest represents a resource to be deployed on spoke cluster.
Appears in:
ManifestCondition
ManifestCondition represents the conditions of the resources deployed on
spoke cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
identifier WorkResourceIdentifier | resourceId represents a identity of a resource linking to manifests in spec. | | Required: {}
|
conditions Condition array | Conditions represents the conditions of this resource on spoke cluster | | Required: {}
|
driftDetails DriftDetails | DriftDetails explains about the observed configuration drifts.
Fleet might truncate the details as appropriate to control object size.
Note that configuration drifts can only occur on a resource if it is currently owned by
Fleet and its corresponding placement is set to use the ClientSideApply or ServerSideApply
apply strategy. In other words, DriftDetails and DiffDetails will not be populated
at the same time. | | Optional: {}
|
diffDetails DiffDetails | DiffDetails explains the details about the observed configuration differences.
Fleet might truncate the details as appropriate to control object size.
Note that configuration differences can only occur on a resource if it is not currently owned
by Fleet (i.e., it is a pre-existing resource that needs to be taken over), or if its
corresponding placement is set to use the ReportDiff apply strategy. In other words,
DiffDetails and DriftDetails will not be populated at the same time. | | Optional: {}
|
NamespacedName
NamespacedName comprises a resource name, with a mandatory namespace.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | Name is the name of the namespaced scope resource. | | Required: {}
|
namespace string | Namespace is namespace of the namespaced scope resource. | | Required: {}
|
OverridePolicy
OverridePolicy defines how to override the selected resources on the target clusters.
More is to be added.
Appears in:
| Field | Description | Default | Validation |
|---|
overrideRules OverrideRule array | OverrideRules defines an array of override rules to be applied on the selected resources.
The order of the rules determines the override order.
When there are two rules selecting the same fields on the target cluster, the last one will win.
You can have 1-20 rules. | | MaxItems: 20
MinItems: 1
Required: {}
Required: {}
|
OverrideRule
OverrideRule defines how to override the selected resources on the target clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterSelector ClusterSelector | ClusterSelectors selects the target clusters.
The resources will be overridden before applying to the matching clusters.
An empty clusterSelector selects ALL the member clusters.
A nil clusterSelector selects NO member clusters.
For now, only labelSelector is supported. | | Optional: {}
|
overrideType OverrideType | OverrideType defines the type of the override rules. | JSONPatch | Enum: [JSONPatch Delete]
Optional: {}
|
jsonPatchOverrides JSONPatchOverride array | JSONPatchOverrides defines a list of JSON patch override rules.
This field is only allowed when OverrideType is JSONPatch. | | MaxItems: 20
MinItems: 1
Optional: {}
|
OverrideType
Underlying type: string
OverrideType defines the type of Override
Appears in:
| Field | Description |
|---|
JSONPatch | JSONPatchOverrideType applies a JSON patch on the selected resources following RFC 6902.
|
Delete | DeleteOverrideType deletes the selected resources on the target clusters.
|
PatchDetail
PatchDetail describes a patch that explains an observed configuration drift or
difference.
A patch detail can be transcribed as a JSON patch operation, as specified in RFC 6902.
Appears in:
| Field | Description | Default | Validation |
|---|
path string | The JSON path that points to a field that has drifted or has configuration differences. | | Required: {}
|
valueInMember string | The value at the JSON path from the member cluster side.
This field can be empty if the JSON path does not exist on the member cluster side; i.e.,
applying the manifest from the hub cluster side would add a new field. | | Optional: {}
|
valueInHub string | The value at the JSON path from the hub cluster side.
This field can be empty if the JSON path does not exist on the hub cluster side; i.e.,
applying the manifest from the hub cluster side would remove the field. | | Optional: {}
|
PlacementPolicy
PlacementPolicy contains the rules to select target member clusters to place the selected resources.
Note that only clusters that are both joined and satisfying the rules will be selected.
You can only specify at most one of the two fields: ClusterNames and Affinity.
If none is specified, all the joined clusters are selected.
Appears in:
| Field | Description | Default | Validation |
|---|
placementType PlacementType | Type of placement. Can be “PickAll”, “PickN” or “PickFixed”. Default is PickAll. | PickAll | Enum: [PickAll PickN PickFixed]
Optional: {}
|
clusterNames string array | ClusterNames contains a list of names of MemberCluster to place the selected resources.
Only valid if the placement type is “PickFixed” | | MaxItems: 100
Optional: {}
|
numberOfClusters integer | NumberOfClusters of placement. Only valid if the placement type is “PickN”. | | Minimum: 0
Optional: {}
|
affinity Affinity | Affinity contains cluster affinity scheduling rules. Defines which member clusters to place the selected resources.
Only valid if the placement type is “PickAll” or “PickN”. | | Optional: {}
|
topologySpreadConstraints TopologySpreadConstraint array | TopologySpreadConstraints describes how a group of resources ought to spread across multiple topology
domains. Scheduler will schedule resources in a way which abides by the constraints.
All topologySpreadConstraints are ANDed.
Only valid if the placement type is “PickN”. | | Optional: {}
|
tolerations Toleration array | If specified, the ClusterResourcePlacement’s Tolerations.
Tolerations cannot be updated or deleted.
This field is beta-level and is for the taints and tolerations feature. | | MaxItems: 100
Optional: {}
|
PlacementRef
PlacementRef is the reference to a placement.
For now, we only support ClusterResourcePlacement.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | | | Required: {}
|
scope ResourceScope | Scope defines the scope of the placement.
A clusterResourceOverride can only reference a clusterResourcePlacement (cluster-scoped),
and a resourceOverride can reference either a clusterResourcePlacement or resourcePlacement (namespaced).
The referenced resourcePlacement must be in the same namespace as the resourceOverride. | Cluster | Enum: [Cluster Namespaced]
Optional: {}
|
PlacementType
Underlying type: string
PlacementType identifies the type of placement.
Appears in:
| Field | Description |
|---|
PickAll | PickAllPlacementType picks all clusters that satisfy the rules.
|
PickN | PickNPlacementType picks N clusters that satisfy the rules.
|
PickFixed | PickFixedPlacementType picks a fixed set of clusters.
|
PreferredClusterSelector
Appears in:
| Field | Description | Default | Validation |
|---|
weight integer | Weight associated with matching the corresponding clusterSelectorTerm, in the range [-100, 100]. | | Maximum: 100
Minimum: -100
Required: {}
|
preference ClusterSelectorTerm | A cluster selector term, associated with the corresponding weight. | | Required: {}
|
PropertySelectorOperator
Underlying type: string
PropertySelectorOperator is the operator that can be used with PropertySelectorRequirements.
Appears in:
| Field | Description |
|---|
Gt | PropertySelectorGreaterThan dictates Fleet to select cluster if its observed value of a given
property is greater than the value specified in the requirement.
|
Ge | PropertySelectorGreaterThanOrEqualTo dictates Fleet to select cluster if its observed value
of a given property is greater than or equal to the value specified in the requirement.
|
Eq | PropertySelectorEqualTo dictates Fleet to select cluster if its observed value of a given
property is equal to the values specified in the requirement.
|
Ne | PropertySelectorNotEqualTo dictates Fleet to select cluster if its observed value of a given
property is not equal to the values specified in the requirement.
|
Lt | PropertySelectorLessThan dictates Fleet to select cluster if its observed value of a given
property is less than the value specified in the requirement.
|
Le | PropertySelectorLessThanOrEqualTo dictates Fleet to select cluster if its observed value of a
given property is less than or equal to the value specified in the requirement.
|
PropertySelectorRequirement
PropertySelectorRequirement is a specific property requirement when picking clusters for
resource placement.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | Name is the name of the property; it should be a Kubernetes label name. | | Required: {}
|
operator PropertySelectorOperator | Operator specifies the relationship between a cluster’s observed value of the specified
property and the values given in the requirement. | | Required: {}
|
values string array | Values are a list of values of the specified property which Fleet will compare against
the observed values of individual member clusters in accordance with the given
operator.
At this moment, each value should be a Kubernetes quantity. For more information, see
https://pkg.go.dev/k8s.io/apimachinery/pkg/api/resource#Quantity.
If the operator is Gt (greater than), Ge (greater than or equal to), Lt (less than),
or Le (less than or equal to), Eq (equal to), or Ne (ne), exactly one value must be
specified in the list. | | MaxItems: 1
Required: {}
|
PropertySortOrder
Underlying type: string
Appears in:
| Field | Description |
|---|
Descending | Descending instructs Fleet to sort in descending order, that is, the clusters with higher
observed values of a property are most preferred and should have higher weights. We will
use linear scaling to calculate the weight for each cluster based on the observed values.
For example, with this order, if Fleet sorts all clusters by a specific property where the
observed values are in the range [10, 100], and a weight of 100 is specified;
Fleet will assign:
* a weight of 100 to the cluster with the maximum observed value (100); and
* a weight of 0 to the cluster with the minimum observed value (10); and
* a weight of 11 to the cluster with an observed value of 20.
It is calculated using the formula below:
((20 - 10)) / (100 - 10)) * 100 = 11
|
Ascending | Ascending instructs Fleet to sort in ascending order, that is, the clusters with lower
observed values are most preferred and should have higher weights. We will use linear scaling
to calculate the weight for each cluster based on the observed values.
For example, with this order, if Fleet sorts all clusters by a specific property where
the observed values are in the range [10, 100], and a weight of 100 is specified;
Fleet will assign:
* a weight of 0 to the cluster with the maximum observed value (100); and
* a weight of 100 to the cluster with the minimum observed value (10); and
* a weight of 89 to the cluster with an observed value of 20.
It is calculated using the formula below:
(1 - ((20 - 10) / (100 - 10))) * 100 = 89
|
ResourceBindingSpec
ResourceBindingSpec defines the desired state of ClusterResourceBinding.
Appears in:
| Field | Description | Default | Validation |
|---|
state BindingState | The desired state of the binding. Possible values: Scheduled, Bound, Unscheduled. | | Required: {}
|
resourceSnapshotName string | ResourceSnapshotName is the name of the resource snapshot that this resource binding points to.
If the resources are divided into multiple snapshots because of the resource size limit,
it points to the name of the leading snapshot of the index group. | | |
resourceOverrideSnapshots NamespacedName array | ResourceOverrideSnapshots is a list of ResourceOverride snapshots associated with the selected resources. | | |
clusterResourceOverrideSnapshots string array | ClusterResourceOverrides contains a list of applicable ClusterResourceOverride snapshot names associated with the
selected resources. | | |
schedulingPolicySnapshotName string | SchedulingPolicySnapshotName is the name of the scheduling policy snapshot that this resource binding
points to; more specifically, the scheduler creates this bindings in accordance with this
scheduling policy snapshot. | | |
targetCluster string | TargetCluster is the name of the cluster that the scheduler assigns the resources to. | | |
clusterDecision ClusterDecision | ClusterDecision explains why the scheduler selected this cluster. | | |
applyStrategy ApplyStrategy | ApplyStrategy describes how to resolve the conflict if the resource to be placed already exists in the target cluster
and is owned by other appliers.
This field is a beta-level feature. | | Optional: {}
|
ResourceBindingStatus
ResourceBindingStatus represents the current status of a ClusterResourceBinding.
Appears in:
| Field | Description | Default | Validation |
|---|
failedPlacements FailedResourcePlacement array | FailedPlacements is a list of all the resources failed to be placed to the given cluster or the resource is unavailable.
Note that we only include 100 failed resource placements even if there are more than 100. | | MaxItems: 100
Optional: {}
|
driftedPlacements DriftedResourcePlacement array | DriftedPlacements is a list of resources that have drifted from their desired states
kept in the hub cluster, as found by Fleet using the drift detection mechanism.
To control the object size, only the first 100 drifted resources will be included.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
diffedPlacements DiffedResourcePlacement array | DiffedPlacements is a list of resources that have configuration differences from their
corresponding hub cluster manifests. Fleet will report such differences when:
* The CRP uses the ReportDiff apply strategy, which instructs Fleet to compare the hub
cluster manifests against the live resources without actually performing any apply op; or
* Fleet finds a pre-existing resource on the member cluster side that does not match its
hub cluster counterpart, and the CRP has been configured to only take over a resource if
no configuration differences are found.
To control the object size, only the first 100 diffed resources will be included.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for ClusterResourceBinding. | | Optional: {}
|
ResourceContent
ResourceContent contains the content of a resource
Appears in:
ResourceIdentifier
ResourceIdentifier identifies one Kubernetes resource.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group is the group name of the selected resource. | | Optional: {}
|
version string | Version is the version of the selected resource. | | Required: {}
|
kind string | Kind represents the Kind of the selected resources. | | Required: {}
|
name string | Name of the target resource. | | Required: {}
|
namespace string | Namespace is the namespace of the resource. Empty if the resource is cluster scoped. | | Optional: {}
|
envelope EnvelopeIdentifier | Envelope identifies the envelope object that contains this resource. | | Optional: {}
|
ResourceOverride
ResourceOverride defines a group of override policies about how to override the selected namespaced scope resources
to target clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ResourceOverride | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceOverrideSpec | The desired state of ResourceOverrideSpec. | | Required: {}
|
ResourceOverrideSnapshot
ResourceOverrideSnapshot is used to store a snapshot of ResourceOverride.
Its spec is immutable.
We assign an ever-increasing index for snapshots.
The naming convention of a ResourceOverrideSnapshot is {ResourceOverride}-{resourceIndex}.
resourceIndex will begin with 0.
Each snapshot MUST have the following labels:
OverrideTrackingLabel which points to its owner ResourceOverride.IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | ResourceOverrideSnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceOverrideSnapshotSpec | The desired state of ResourceOverrideSnapshot. | | Required: {}
|
ResourceOverrideSnapshotSpec
ResourceOverrideSnapshotSpec defines the desired state of ResourceOverride.
Appears in:
| Field | Description | Default | Validation |
|---|
overrideSpec ResourceOverrideSpec | OverrideSpec stores the spec of ResourceOverride. | | |
overrideHash integer array | OverrideHash is the sha-256 hash value of the OverrideSpec field. | | Required: {}
|
ResourceOverrideSpec
ResourceOverrideSpec defines the desired state of the Override.
The ResourceOverride create or update will fail when the resource has been selected by the existing ResourceOverride.
If the resource is selected by both ClusterResourceOverride and ResourceOverride, ResourceOverride will win when resolving
conflicts.
Appears in:
| Field | Description | Default | Validation |
|---|
placement PlacementRef | Placement defines whether the override is applied to a specific placement or not.
If set, the override will trigger the placement rollout immediately when the rollout strategy type is RollingUpdate.
Otherwise, it will be applied to the next rollout.
The recommended way is to set the placement so that the override can be rolled out immediately. | | Optional: {}
|
resourceSelectors ResourceSelector array | ResourceSelectors is an array of selectors used to select namespace scoped resources. The selectors are ORed.
You can have 1-20 selectors. | | MaxItems: 20
MinItems: 1
Required: {}
Required: {}
|
policy OverridePolicy | Policy defines how to override the selected resources on the target clusters. | | Required: {}
|
ResourcePlacementStatus
ResourcePlacementStatus represents the placement status of selected resources for one target cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterName string | ClusterName is the name of the cluster this resource is assigned to.
If it is not empty, its value should be unique cross all placement decisions for the Placement. | | Optional: {}
|
applicableResourceOverrides NamespacedName array | ApplicableResourceOverrides contains a list of applicable ResourceOverride snapshots associated with the selected
resources.
This field is alpha-level and is for the override policy feature. | | Optional: {}
|
applicableClusterResourceOverrides string array | ApplicableClusterResourceOverrides contains a list of applicable ClusterResourceOverride snapshots associated with
the selected resources.
This field is alpha-level and is for the override policy feature. | | Optional: {}
|
failedPlacements FailedResourcePlacement array | FailedPlacements is a list of all the resources failed to be placed to the given cluster or the resource is unavailable.
Note that we only include 100 failed resource placements even if there are more than 100.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
driftedPlacements DriftedResourcePlacement array | DriftedPlacements is a list of resources that have drifted from their desired states
kept in the hub cluster, as found by Fleet using the drift detection mechanism.
To control the object size, only the first 100 drifted resources will be included.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
diffedPlacements DiffedResourcePlacement array | DiffedPlacements is a list of resources that have configuration differences from their
corresponding hub cluster manifests. Fleet will report such differences when:
* The CRP uses the ReportDiff apply strategy, which instructs Fleet to compare the hub
cluster manifests against the live resources without actually performing any apply op; or
* Fleet finds a pre-existing resource on the member cluster side that does not match its
hub cluster counterpart, and the CRP has been configured to only take over a resource if
no configuration differences are found.
To control the object size, only the first 100 diffed resources will be included.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for ResourcePlacementStatus. | | Optional: {}
|
ResourceScope
Underlying type: string
ResourceScope defines the scope of placement reference.
Appears in:
| Field | Description |
|---|
Cluster | ClusterScoped indicates placement is cluster-scoped.
|
Namespaced | NamespaceScoped indicates placement is namespace-scoped.
|
ResourceSelector
ResourceSelector is used to select namespace scoped resources as the target resources to be placed.
All the fields are ANDed. In other words, a resource must match all the fields to be selected.
The resource namespace will inherit from the parent object scope.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group name of the namespace-scoped resource.
Use an empty string to select resources under the core API group (e.g., services). | | Required: {}
|
version string | Version of the namespace-scoped resource. | | Required: {}
|
kind string | Kind of the namespace-scoped resource. | | Required: {}
|
name string | Name of the namespace-scoped resource. | | Required: {}
|
ResourceSnapshotSpec
ResourceSnapshotSpec defines the desired state of ResourceSnapshot.
Appears in:
| Field | Description | Default | Validation |
|---|
selectedResources ResourceContent array | SelectedResources contains a list of resources selected by ResourceSelectors. | | Required: {}
|
ResourceSnapshotStatus
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions is an array of current observed conditions for ResourceSnapshot. | | Optional: {}
|
RollingUpdateConfig
RollingUpdateConfig contains the config to control the desired behavior of rolling update.
Appears in:
| Field | Description | Default | Validation |
|---|
maxUnavailable IntOrString | The maximum number of clusters that can be unavailable during the rolling update
comparing to the desired number of clusters.
The desired number equals to the NumberOfClusters field when the placement type is PickN.
The desired number equals to the number of clusters scheduler selected when the placement type is PickAll.
Value can be an absolute number (ex: 5) or a percentage of the desired number of clusters (ex: 10%).
Absolute number is calculated from percentage by rounding up.
We consider a resource unavailable when we either remove it from a cluster or in-place
upgrade the resources content on the same cluster.
The minimum of MaxUnavailable is 0 to allow no downtime moving a placement from one cluster to another.
Please set it to be greater than 0 to avoid rolling out stuck during in-place resource update.
Defaults to 25%. | 25% | Pattern: ^((100|[0-9]\{1,2\})%|[0-9]+)$
XIntOrString: {}
Optional: {}
|
maxSurge IntOrString | The maximum number of clusters that can be scheduled above the desired number of clusters.
The desired number equals to the NumberOfClusters field when the placement type is PickN.
The desired number equals to the number of clusters scheduler selected when the placement type is PickAll.
Value can be an absolute number (ex: 5) or a percentage of desire (ex: 10%).
Absolute number is calculated from percentage by rounding up.
This does not apply to the case that we do in-place update of resources on the same cluster.
This can not be 0 if MaxUnavailable is 0.
Defaults to 25%. | 25% | Pattern: ^((100|[0-9]\{1,2\})%|[0-9]+)$
XIntOrString: {}
Optional: {}
|
unavailablePeriodSeconds integer | UnavailablePeriodSeconds is used to configure the waiting time between rollout phases when we
cannot determine if the resources have rolled out successfully or not.
We have a built-in resource state detector to determine the availability status of following well-known Kubernetes
native resources: Deployment, StatefulSet, DaemonSet, Service, Namespace, ConfigMap, Secret,
ClusterRole, ClusterRoleBinding, Role, RoleBinding.
Please see SafeRollout for more details.
For other types of resources, we consider them as available after UnavailablePeriodSeconds seconds
have passed since they were successfully applied to the target cluster.
Default is 60. | 60 | Optional: {}
|
RolloutStrategy
RolloutStrategy describes how to roll out a new change in selected resources to target clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
type RolloutStrategyType | Type of rollout. The only supported type is “RollingUpdate”. Default is “RollingUpdate”. | RollingUpdate | Enum: [RollingUpdate]
Optional: {}
|
rollingUpdate RollingUpdateConfig | Rolling update config params. Present only if RolloutStrategyType = RollingUpdate. | | Optional: {}
|
applyStrategy ApplyStrategy | ApplyStrategy describes how to resolve the conflict if the resource to be placed already exists in the target cluster
and is owned by other appliers.
This field is a beta-level feature. | | Optional: {}
|
RolloutStrategyType
Underlying type: string
Appears in:
| Field | Description |
|---|
RollingUpdate | RollingUpdateRolloutStrategyType replaces the old placed resource using rolling update
i.e. gradually create the new one while replace the old ones.
|
SchedulingPolicySnapshotSpec
SchedulingPolicySnapshotSpec defines the desired state of SchedulingPolicySnapshot.
Appears in:
| Field | Description | Default | Validation |
|---|
policy PlacementPolicy | Policy defines how to select member clusters to place the selected resources.
If unspecified, all the joined member clusters are selected. | | Optional: {}
|
policyHash integer array | PolicyHash is the sha-256 hash value of the Policy field. | | Required: {}
|
SchedulingPolicySnapshotStatus
SchedulingPolicySnapshotStatus defines the observed state of SchedulingPolicySnapshot.
Appears in:
| Field | Description | Default | Validation |
|---|
observedCRPGeneration integer | ObservedCRPGeneration is the generation of the CRP which the scheduler uses to perform
the scheduling cycle and prepare the scheduling status. | | Required: {}
|
conditions Condition array | Conditions is an array of current observed conditions for SchedulingPolicySnapshot. | | Optional: {}
|
targetClusters ClusterDecision array | ClusterDecisions contains a list of names of member clusters considered by the scheduler.
Note that all the selected clusters must present in the list while not all the
member clusters are guaranteed to be listed due to the size limit. We will try to
add the clusters that can provide the most insight to the list first. | | MaxItems: 1000
Optional: {}
|
ServerSideApplyConfig
ServerSideApplyConfig defines the configuration for server side apply.
Details: https://kubernetes.io/docs/reference/using-api/server-side-apply/#conflicts
Appears in:
| Field | Description | Default | Validation |
|---|
force boolean | Force represents to force apply to succeed when resolving the conflicts
For any conflicting fields,
- If true, use the values from the resource to be applied to overwrite the values of the existing resource in the
target cluster, as well as take over ownership of such fields.
- If false, apply will fail with the reason ApplyConflictWithOtherApplier.
For non-conflicting fields, values stay unchanged and ownership are shared between appliers. | | Optional: {}
|
StageConfig
StageConfig describes a single update stage.
The clusters in each stage are updated sequentially.
The update stops if any of the updates fail.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | The name of the stage. This MUST be unique within the same StagedUpdateStrategy. | | MaxLength: 63
Pattern: ^[a-z0-9]+$
Required: {}
|
labelSelector LabelSelector | LabelSelector is a label query over all the joined member clusters. Clusters matching the query are selected
for this stage. There cannot be overlapping clusters between stages when the stagedUpdateRun is created.
If the label selector is empty, the stage includes all the selected clusters.
If the label selector is nil, the stage does not include any selected clusters. | | Optional: {}
|
sortingLabelKey string | The label key used to sort the selected clusters.
The clusters within the stage are updated sequentially following the rule below:
- primary: Ascending order based on the value of the label key, interpreted as integers if present.
- secondary: Ascending order based on the name of the cluster if the label key is absent or the label value is the same. | | Optional: {}
|
maxConcurrency IntOrString | MaxConcurrency specifies the maximum number of clusters that can be updated concurrently within this stage.
Value can be an absolute number (ex: 5) or a percentage of the total clusters in the stage (ex: 50%).
Fractional results are rounded down. A minimum of 1 update is enforced.
If not specified, all clusters in the stage are updated sequentially (effectively maxConcurrency = 1).
Defaults to 1. | 1 | Optional: {}
Pattern: ^(100|[1-9][0-9]?)%$
XIntOrString: {}
|
afterStageTasks StageTask array | The collection of tasks that each stage needs to complete successfully before moving to the next stage.
Each task is executed in parallel and there cannot be more than one task of the same type. | | MaxItems: 2
Optional: {}
|
beforeStageTasks StageTask array | The collection of tasks that needs to completed successfully by each stage before starting the stage.
Each task is executed in parallel and there cannot be more than one task of the same type. | | MaxItems: 1
Optional: {}
|
StageTask
StageTask is the pre or post stage task that needs to be completed before starting or moving to the next stage.
Appears in:
| Field | Description | Default | Validation |
|---|
type StageTaskType | The type of the before or after stage task. | | Enum: [TimedWait Approval]
Required: {}
|
waitTime Duration | The time to wait after all the clusters in the current stage complete the update before moving to the next stage. | | Optional: {}
Pattern: ^0|([0-9]+(\.[0-9]+)?(s|m|h))+$
Type: string
|
StageTaskStatus
Appears in:
| Field | Description | Default | Validation |
|---|
type StageTaskType | The type of the pre or post update task. | | Enum: [TimedWait Approval]
Required: {}
|
approvalRequestName string | The name of the approval request object that is created for this stage.
Only valid if the AfterStageTaskType is Approval. | | Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for the specific type of pre or post update task.
Known conditions are “ApprovalRequestCreated”, “WaitTimeElapsed”, and “ApprovalRequestApproved”. | | Optional: {}
|
StageTaskType
Underlying type: string
StageTaskType identifies a specific type of the AfterStageTask or BeforeStageTask.
Appears in:
| Field | Description |
|---|
TimedWait | StageTaskTypeTimedWait indicates the stage task is a timed wait.
|
Approval | StageTaskTypeApproval indicates the stage task is an approval.
|
StageUpdatingStatus
StageUpdatingStatus defines the status of the update run in a stage.
Appears in:
| Field | Description | Default | Validation |
|---|
stageName string | The name of the stage. | | Required: {}
|
clusters ClusterUpdatingStatus array | The list of each cluster’s updating status in this stage. | | Required: {}
|
afterStageTaskStatus StageTaskStatus array | The status of the post-update tasks associated with the current stage.
Empty if the stage has not finished updating all the clusters. | | MaxItems: 2
Optional: {}
|
beforeStageTaskStatus StageTaskStatus array | The status of the pre-update tasks associated with the current stage. | | MaxItems: 1
Optional: {}
|
startTime Time | The time when the update started on the stage. Empty if the stage has not started updating. | | Format: date-time
Optional: {}
Type: string
|
endTime Time | The time when the update finished on the stage. Empty if the stage has not started updating. | | Format: date-time
Optional: {}
Type: string
|
conditions Condition array | Conditions is an array of current observed updating conditions for the stage. Empty if the stage has not started updating.
Known conditions are “Progressing”, “Succeeded”. | | Optional: {}
|
StagedUpdateRun
StagedUpdateRun represents a stage by stage update process that applies ResourcePlacement
selected resources to specified clusters.
Resources from unselected clusters are removed after all stages in the update strategy are completed.
Each StagedUpdateRun object corresponds to a single release of a specific resource version.
The release is abandoned if the StagedUpdateRun object is deleted or the scheduling decision changes.
The name of the StagedUpdateRun must conform to RFC 1123.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | StagedUpdateRun | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec UpdateRunSpec | The desired state of StagedUpdateRun. | | Required: {}
|
status UpdateRunStatus | The observed status of StagedUpdateRun. | | Optional: {}
|
StagedUpdateStrategy
StagedUpdateStrategy defines a reusable strategy that specifies the stages and the sequence
in which the selected cluster resources will be updated on the member clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | StagedUpdateStrategy | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec UpdateStrategySpec | The desired state of StagedUpdateStrategy. | | Required: {}
|
State
Underlying type: string
State represents the desired state of an update run.
Appears in:
| Field | Description |
|---|
Initialize | StateInitialize describes user intent to initialize but not run the update run.
This is the default state when an update run is created.
Users can subsequently set the state to Run.
|
Run | StateRun describes user intent to execute (or resume execution if stopped).
Users can subsequently set the state to Stop.
|
Stop | StateStop describes user intent to stop the update run.
Users can subsequently set the state to Run.
|
Toleration
Toleration allows ClusterResourcePlacement to tolerate any taint that matches
the triple <key,value,effect> using the matching operator .
Appears in:
| Field | Description | Default | Validation |
|---|
key string | Key is the taint key that the toleration applies to. Empty means match all taint keys.
If the key is empty, operator must be Exists; this combination means to match all values and all keys. | | Optional: {}
|
operator TolerationOperator | Operator represents a key’s relationship to the value.
Valid operators are Exists and Equal. Defaults to Equal.
Exists is equivalent to wildcard for value, so that a
ClusterResourcePlacement can tolerate all taints of a particular category. | Equal | Enum: [Equal Exists]
Optional: {}
|
value string | Value is the taint value the toleration matches to.
If the operator is Exists, the value should be empty, otherwise just a regular string. | | Optional: {}
|
effect TaintEffect | Effect indicates the taint effect to match. Empty means match all taint effects.
When specified, only allowed value is NoSchedule. | | Enum: [NoSchedule]
Optional: {}
|
TopologySpreadConstraint
TopologySpreadConstraint specifies how to spread resources among the given cluster topology.
Appears in:
| Field | Description | Default | Validation |
|---|
maxSkew integer | MaxSkew describes the degree to which resources may be unevenly distributed.
When whenUnsatisfiable=DoNotSchedule, it is the maximum permitted difference
between the number of resource copies in the target topology and the global minimum.
The global minimum is the minimum number of resource copies in a domain.
When whenUnsatisfiable=ScheduleAnyway, it is used to give higher precedence
to topologies that satisfy it.
It’s an optional field. Default value is 1 and 0 is not allowed. | 1 | Minimum: 1
Optional: {}
|
topologyKey string | TopologyKey is the key of cluster labels. Clusters that have a label with this key
and identical values are considered to be in the same topology.
We consider each <key, value> as a “bucket”, and try to put balanced number
of replicas of the resource into each bucket honor the MaxSkew value.
It’s a required field. | | Required: {}
|
whenUnsatisfiable UnsatisfiableConstraintAction | WhenUnsatisfiable indicates how to deal with the resource if it doesn’t satisfy
the spread constraint.
- DoNotSchedule (default) tells the scheduler not to schedule it.
- ScheduleAnyway tells the scheduler to schedule the resource in any cluster,
but giving higher precedence to topologies that would help reduce the skew.
It’s an optional field. | | Optional: {}
|
UnsatisfiableConstraintAction
Underlying type: string
UnsatisfiableConstraintAction defines the type of actions that can be taken if a constraint is not satisfied.
Appears in:
| Field | Description |
|---|
DoNotSchedule | DoNotSchedule instructs the scheduler not to schedule the resource
onto the cluster when constraints are not satisfied.
|
ScheduleAnyway | ScheduleAnyway instructs the scheduler to schedule the resource
even if constraints are not satisfied.
|
UpdateRunSpec
UpdateRunSpec defines the desired rollout strategy and the snapshot indices of the resources to be updated.
It specifies a stage-by-stage update process across selected clusters for the given ResourcePlacement object.
Appears in:
| Field | Description | Default | Validation |
|---|
placementName string | PlacementName is the name of placement that this update run is applied to.
There can be multiple active update runs for each placement, but
it’s up to the DevOps team to ensure they don’t conflict with each other. | | MaxLength: 255
Required: {}
|
resourceSnapshotIndex string | The resource snapshot index of the selected resources to be updated across clusters.
The index represents a group of resource snapshots that includes all the resources a ResourcePlacement selected. | | Optional: {}
|
stagedRolloutStrategyName string | The name of the update strategy that specifies the stages and the sequence
in which the selected resources will be updated on the member clusters. The stages
are computed according to the referenced strategy when the update run starts
and recorded in the status field. | | Required: {}
|
state State | State indicates the desired state of the update run.
Initialize: The update run should be initialized but execution should not start (default).
Run: The update run should execute or resume execution.
Stop: The update run should stop execution. | Initialize | Enum: [Initialize Run Stop]
Optional: {}
|
UpdateRunStatus
UpdateRunStatus defines the observed state of the ClusterStagedUpdateRun.
Appears in:
| Field | Description | Default | Validation |
|---|
policySnapshotIndexUsed string | PolicySnapShotIndexUsed records the policy snapshot index of the ClusterResourcePlacement (CRP) that
the update run is based on. The index represents the latest policy snapshot at the start of the update run.
If a newer policy snapshot is detected after the run starts, the staged update run is abandoned.
The scheduler must identify all clusters that meet the current policy before the update run begins.
All clusters involved in the update run are selected from the list of clusters scheduled by the CRP according
to the current policy. | | Optional: {}
|
policyObservedClusterCount integer | PolicyObservedClusterCount records the number of observed clusters in the policy snapshot.
It is recorded at the beginning of the update run from the policy snapshot object.
If the ObservedClusterCount value is updated during the update run, the update run is abandoned. | | Optional: {}
|
resourceSnapshotIndexUsed string | ResourceSnapshotIndexUsed records the resource snapshot index that the update run is based on.
The index represents the same resource snapshots as specified in the spec field, or the latest. | | |
appliedStrategy ApplyStrategy | ApplyStrategy is the apply strategy that the stagedUpdateRun is using.
It is the same as the apply strategy in the CRP when the staged update run starts.
The apply strategy is not updated during the update run even if it changes in the CRP. | | Optional: {}
|
stagedUpdateStrategySnapshot UpdateStrategySpec | UpdateStrategySnapshot is the snapshot of the UpdateStrategy used for the update run.
The snapshot is immutable during the update run.
The strategy is applied to the list of clusters scheduled by the CRP according to the current policy.
The update run fails to initialize if the strategy fails to produce a valid list of stages where each selected
cluster is included in exactly one stage. | | Optional: {}
|
stagesStatus StageUpdatingStatus array | StagesStatus lists the current updating status of each stage.
The list is empty if the update run is not started or failed to initialize. | | Optional: {}
|
deletionStageStatus StageUpdatingStatus | DeletionStageStatus lists the current status of the deletion stage. The deletion stage
removes all the resources from the clusters that are not selected by the
current policy after all the update stages are completed. | | Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for StagedUpdateRun.
Known conditions are “Initialized”, “Progressing”, “Succeeded”. | | Optional: {}
|
UpdateStrategySpec
UpdateStrategySpec defines the desired state of the StagedUpdateStrategy.
Appears in:
| Field | Description | Default | Validation |
|---|
stages StageConfig array | Stage specifies the configuration for each update stage. | | MaxItems: 31
Required: {}
|
WhenToApplyType
Underlying type: string
WhenToApplyType describes when Fleet would apply the manifests on the hub cluster to
the member clusters.
Appears in:
| Field | Description |
|---|
Always | WhenToApplyTypeAlways instructs Fleet to periodically apply hub cluster manifests
on the member cluster side; this will effectively overwrite any change in the fields
managed by Fleet (i.e., specified in the hub cluster manifest).
|
IfNotDrifted | WhenToApplyTypeIfNotDrifted instructs Fleet to stop applying hub cluster manifests on
clusters that have drifted from the desired state; apply ops would still continue on
the rest of the clusters.
|
WhenToTakeOverType
Underlying type: string
WhenToTakeOverType describes the type of the action to take when we first apply the
resources to the member cluster.
Appears in:
| Field | Description |
|---|
IfNoDiff | WhenToTakeOverTypeIfNoDiff instructs Fleet to apply a manifest with a corresponding
pre-existing resource on a member cluster if and only if the pre-existing resource
looks the same as the manifest. Should there be any inconsistency, Fleet will skip
the apply op; no change will be made on the resource and Fleet will not claim
ownership on it.
Note that this will not stop Fleet from processing other manifests in the same
placement that do not concern the takeover process (e.g., the manifests that have
not been created yet, or that are already under the management of Fleet).
|
Always | WhenToTakeOverTypeAlways instructs Fleet to always apply manifests to a member cluster,
even if there are some corresponding pre-existing resources. Some fields on these
resources might be overwritten, and Fleet will claim ownership on them.
|
Never | WhenToTakeOverTypeNever instructs Fleet to never apply a manifest to a member cluster
if there is a corresponding pre-existing resource.
Note that this will not stop Fleet from processing other manifests in the same placement
that do not concern the takeover process (e.g., the manifests that have not been created
yet, or that are already under the management of Fleet).
If you would like Fleet to stop processing manifests all together and do not assume
ownership on any pre-existing resources, use this option along with the ReportDiff
apply strategy type. This setup would instruct Fleet to touch nothing on the member
cluster side but still report configuration differences between the hub cluster
and member clusters. Fleet will not give up ownership that it has already assumed, though.
|
Work
Work is the Schema for the works API.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | Work | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec WorkSpec | spec defines the workload of a work. | | Optional: {}
|
status WorkStatus | status defines the status of each applied manifest on the spoke cluster. | | |
WorkList
WorkList contains a list of Work.
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1 | | |
kind string | WorkList | | |
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | | Optional: {}
|
items Work array | List of works. | | |
WorkResourceIdentifier
WorkResourceIdentifier provides the identifiers needed to interact with any arbitrary object.
Renamed original “ResourceIdentifier” so that it won’t conflict with ResourceIdentifier defined in the clusterresourceplacement_types.go.
Appears in:
| Field | Description | Default | Validation |
|---|
ordinal integer | Ordinal represents an index in manifests list, so the condition can still be linked
to a manifest even though manifest cannot be parsed successfully. | | |
group string | Group is the group of the resource. | | |
version string | Version is the version of the resource. | | |
kind string | Kind is the kind of the resource. | | |
resource string | Resource is the resource type of the resource | | |
namespace string | Namespace is the namespace of the resource, the resource is cluster scoped if the value
is empty | | |
name string | Name is the name of the resource | | |
WorkSpec
WorkSpec defines the desired state of Work.
Appears in:
| Field | Description | Default | Validation |
|---|
workload WorkloadTemplate | Workload represents the manifest workload to be deployed on spoke cluster | | |
applyStrategy ApplyStrategy | ApplyStrategy describes how to resolve the conflict if the resource to be placed already exists in the target cluster
and is owned by other appliers.
This field is a beta-level feature. | | Optional: {}
|
WorkStatus
WorkStatus defines the observed state of Work.
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions contains the different condition statuses for this work.
Valid condition types are:
1. Applied represents workload in Work is applied successfully on the spoke cluster.
2. Progressing represents workload in Work in the transitioning from one state to another the on the spoke cluster.
3. Available represents workload in Work exists on the spoke cluster.
4. Degraded represents the current state of workload does not match the desired
state for a certain period. | | |
manifestConditions ManifestCondition array | ManifestConditions represents the conditions of each resource in work deployed on
spoke cluster. | | Optional: {}
|
WorkloadTemplate
WorkloadTemplate represents the manifest workload to be deployed on spoke cluster
Appears in:
| Field | Description | Default | Validation |
|---|
manifests Manifest array | Manifests represents a list of kubernetes resources to be deployed on the spoke cluster. | | Optional: {}
|
7.4 - placement.kubernetes-fleet.io/v1beta1
API Reference
Packages
placement.kubernetes-fleet.io/v1beta1
Resource Types
Affinity
Affinity is a group of cluster affinity scheduling rules. More to be added.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterAffinity ClusterAffinity | ClusterAffinity contains cluster affinity scheduling rules for the selected resources. | | Optional: {}
|
AppliedResourceMeta represents the group, version, resource, name and namespace of a resource.
Since these resources have been created, they must have valid group, version, resource, namespace, and name.
Appears in:
| Field | Description | Default | Validation |
|---|
ordinal integer | Ordinal represents an index in manifests list, so the condition can still be linked
to a manifest even though manifest cannot be parsed successfully. | | |
group string | Group is the group of the resource. | | |
version string | Version is the version of the resource. | | |
kind string | Kind is the kind of the resource. | | |
resource string | Resource is the resource type of the resource. | | |
namespace string | Namespace is the namespace of the resource, the resource is cluster scoped if the value
is empty. | | |
name string | Name is the name of the resource. | | |
uid UID | UID is set on successful deletion of the Kubernetes resource by controller. The
resource might be still visible on the managed cluster after this field is set.
It is not directly settable by a client. | | Optional: {}
|
AppliedWork
AppliedWork represents an applied work on managed cluster that is placed
on a managed cluster. An appliedwork links to a work on a hub recording resources
deployed in the managed cluster.
When the agent is removed from managed cluster, cluster-admin on managed cluster
can delete appliedwork to remove resources deployed by the agent.
The name of the appliedwork must be the same as {work name}
The namespace of the appliedwork should be the same as the resource applied on
the managed cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | AppliedWork | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec AppliedWorkSpec | Spec represents the desired configuration of AppliedWork. | | Required: {}
Required: {}
|
status AppliedWorkStatus | Status represents the current status of AppliedWork. | | Optional: {}
|
AppliedWorkList
AppliedWorkList contains a list of AppliedWork.
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | AppliedWorkList | | |
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | | Optional: {}
|
items AppliedWork array | List of works. | | |
AppliedWorkSpec
AppliedWorkSpec represents the desired configuration of AppliedWork.
Appears in:
| Field | Description | Default | Validation |
|---|
workName string | WorkName represents the name of the related work on the hub. | | Required: {}
Required: {}
|
workNamespace string | WorkNamespace represents the namespace of the related work on the hub. | | Required: {}
Required: {}
|
AppliedWorkStatus
AppliedWorkStatus represents the current status of AppliedWork.
Appears in:
| Field | Description | Default | Validation |
|---|
appliedResources AppliedResourceMeta array | AppliedResources represents a list of resources defined within the Work that are applied.
Only resources with valid GroupVersionResource, namespace, and name are suitable.
An item in this slice is deleted when there is no mapped manifest in Work.Spec or by finalizer.
The resource relating to the item will also be removed from managed cluster.
The deleted resource may still be present until the finalizers for that resource are finished.
However, the resource will not be undeleted, so it can be removed from this list and eventual consistency is preserved. | | Optional: {}
|
ApplyStrategy
ApplyStrategy describes when and how to apply the selected resource to the target cluster.
Note: If multiple CRPs try to place the same resource with different apply strategy, the later ones will fail with the
reason ApplyConflictBetweenPlacements.
Appears in:
| Field | Description | Default | Validation |
|---|
comparisonOption ComparisonOptionType | ComparisonOption controls how Fleet compares the desired state of a resource, as kept in
a hub cluster manifest, with the current state of the resource (if applicable) in the
member cluster.
Available options are:
* PartialComparison: with this option, Fleet will compare only fields that are managed by
Fleet, i.e., the fields that are specified explicitly in the hub cluster manifest.
Unmanaged fields are ignored. This is the default option.
* FullComparison: with this option, Fleet will compare all fields of the resource,
even if the fields are absent from the hub cluster manifest.
Consider using the PartialComparison option if you would like to:
* use the default values for certain fields; or
* let another agent, e.g., HPAs, VPAs, etc., on the member cluster side manage some fields; or
* allow ad-hoc or cluster-specific settings on the member cluster side.
To use the FullComparison option, it is recommended that you:
* specify all fields as appropriate in the hub cluster, even if you are OK with using default
values;
* make sure that no fields are managed by agents other than Fleet on the member cluster
side, such as HPAs, VPAs, or other controllers.
See the Fleet documentation for further explanations and usage examples. | PartialComparison | Enum: [PartialComparison FullComparison]
Optional: {}
|
whenToApply WhenToApplyType | WhenToApply controls when Fleet would apply the manifests on the hub cluster to the member
clusters.
Available options are:
* Always: with this option, Fleet will periodically apply hub cluster manifests
on the member cluster side; this will effectively overwrite any change in the fields
managed by Fleet (i.e., specified in the hub cluster manifest). This is the default
option.
Note that this option would revert any ad-hoc changes made on the member cluster side in the
managed fields; if you would like to make temporary edits on the member cluster side
in the managed fields, switch to IfNotDrifted option. Note that changes in unmanaged
fields will be left alone; if you use the FullDiff compare option, such changes will
be reported as drifts.
* IfNotDrifted: with this option, Fleet will stop applying hub cluster manifests on
clusters that have drifted from the desired state; apply ops would still continue on
the rest of the clusters. Drifts are calculated using the ComparisonOption,
as explained in the corresponding field.
Use this option if you would like Fleet to detect drifts in your multi-cluster setup.
A drift occurs when an agent makes an ad-hoc change on the member cluster side that
makes affected resources deviate from its desired state as kept in the hub cluster;
and this option grants you an opportunity to view the drift details and take actions
accordingly. The drift details will be reported in the CRP status.
To fix a drift, you may:
* revert the changes manually on the member cluster side
* update the hub cluster manifest; this will trigger Fleet to apply the latest revision
of the manifests, which will overwrite the drifted fields
(if they are managed by Fleet)
* switch to the Always option; this will trigger Fleet to apply the current revision
of the manifests, which will overwrite the drifted fields (if they are managed by Fleet).
* if applicable and necessary, delete the drifted resources on the member cluster side; Fleet
will attempt to re-create them using the hub cluster manifests | Always | Enum: [Always IfNotDrifted]
Optional: {}
|
type ApplyStrategyType | Type is the apply strategy to use; it determines how Fleet applies manifests from the
hub cluster to a member cluster.
Available options are:
* ClientSideApply: Fleet uses three-way merge to apply manifests, similar to how kubectl
performs a client-side apply. This is the default option.
Note that this strategy requires that Fleet keep the last applied configuration in the
annotation of an applied resource. If the object gets so large that apply ops can no longer
be executed, Fleet will switch to server-side apply.
Use ComparisonOption and WhenToApply settings to control when an apply op can be executed.
* ServerSideApply: Fleet uses server-side apply to apply manifests; Fleet itself will
become the field manager for specified fields in the manifests. Specify
ServerSideApplyConfig as appropriate if you would like Fleet to take over field
ownership upon conflicts. This is the recommended option for most scenarios; it might
help reduce object size and safely resolve conflicts between field values. For more
information, please refer to the Kubernetes documentation
(https://kubernetes.io/docs/reference/using-api/server-side-apply/#comparison-with-client-side-apply).
Use ComparisonOption and WhenToApply settings to control when an apply op can be executed.
* ReportDiff: Fleet will compare the desired state of a resource as kept in the hub cluster
with its current state (if applicable) on the member cluster side, and report any
differences. No actual apply ops would be executed, and resources will be left alone as they
are on the member clusters.
If configuration differences are found on a resource, Fleet will consider this as an apply
error, which might block rollout depending on the specified rollout strategy.
Use ComparisonOption setting to control how the difference is calculated.
ClientSideApply and ServerSideApply apply strategies only work when Fleet can assume
ownership of a resource (e.g., the resource is created by Fleet, or Fleet has taken over
the resource). See the comments on the WhenToTakeOver field for more information.
ReportDiff apply strategy, however, will function regardless of Fleet’s ownership
status. One may set up a CRP with the ReportDiff strategy and the Never takeover option,
and this will turn Fleet into a detection tool that reports only configuration differences
but do not touch any resources on the member cluster side.
For a comparison between the different strategies and usage examples, refer to the
Fleet documentation. | ClientSideApply | Enum: [ClientSideApply ServerSideApply ReportDiff]
Optional: {}
|
allowCoOwnership boolean | AllowCoOwnership controls whether co-ownership between Fleet and other agents are allowed
on a Fleet-managed resource. If set to false, Fleet will refuse to apply manifests to
a resource that has been owned by one or more non-Fleet agents.
Note that Fleet does not support the case where one resource is being placed multiple
times by different CRPs on the same member cluster. An apply error will be returned if
Fleet finds that a resource has been owned by another placement attempt by Fleet, even
with the AllowCoOwnership setting set to true. | | |
serverSideApplyConfig ServerSideApplyConfig | ServerSideApplyConfig defines the configuration for server side apply. It is honored only when type is ServerSideApply. | | Optional: {}
|
whenToTakeOver WhenToTakeOverType | WhenToTakeOver determines the action to take when Fleet applies resources to a member
cluster for the first time and finds out that the resource already exists in the cluster.
This setting is most relevant in cases where you would like Fleet to manage pre-existing
resources on a member cluster.
Available options include:
* Always: with this action, Fleet will apply the hub cluster manifests to the member
clusters even if the affected resources already exist. This is the default action.
Note that this might lead to fields being overwritten on the member clusters, if they
are specified in the hub cluster manifests.
* IfNoDiff: with this action, Fleet will apply the hub cluster manifests to the member
clusters if (and only if) pre-existing resources look the same as the hub cluster manifests.
This is a safer option as pre-existing resources that are inconsistent with the hub cluster
manifests will not be overwritten; Fleet will ignore them until the inconsistencies
are resolved properly: any change you make to the hub cluster manifests would not be
applied, and if you delete the manifests or even the ClusterResourcePlacement itself
from the hub cluster, these pre-existing resources would not be taken away.
Fleet will check for inconsistencies in accordance with the ComparisonOption setting. See also
the comments on the ComparisonOption field for more information.
If a diff has been found in a field that is managed by Fleet (i.e., the field
*is specified ** in the hub cluster manifest), consider one of the following actions:
* set the field in the member cluster to be of the same value as that in the hub cluster
manifest.
* update the hub cluster manifest so that its field value matches with that in the member
cluster.
* switch to the Always action, which will allow Fleet to overwrite the field with the
value in the hub cluster manifest.
If a diff has been found in a field that is not managed by Fleet (i.e., the field
is not specified in the hub cluster manifest), consider one of the following actions:
* remove the field from the member cluster.
* update the hub cluster manifest so that the field is included in the hub cluster manifest.
If appropriate, you may also delete the object from the member cluster; Fleet will recreate
it using the hub cluster manifest.
Never: with this action, Fleet will not apply a hub cluster manifest to the member
clusters if there is a corresponding pre-existing resource. However, if a manifest
has never been applied yet; or it has a corresponding resource which Fleet has assumed
ownership, apply op will still be executed.
This is the safest option; one will have to remove the pre-existing resources (so that
Fleet can re-create them) or switch to a different
WhenToTakeOver option before Fleet starts processing the corresponding hub cluster
manifests.
If you prefer Fleet stop processing all manifests, use this option along with the
ReportDiff apply strategy type. This setup would instruct Fleet to touch nothing
on the member cluster side but still report configuration differences between the
hub cluster and member clusters. Fleet will not give up ownership
that it has already assumed though. | Always | Enum: [Always IfNoDiff Never]
Optional: {}
|
ApplyStrategyType
Underlying type: string
ApplyStrategyType describes the type of the strategy used to apply the resource to the target cluster.
Appears in:
| Field | Description |
|---|
ClientSideApply | ApplyStrategyTypeClientSideApply will use three-way merge patch similar to how kubectl apply does by storing
last applied state in the last-applied-configuration annotation.
When the last-applied-configuration annotation size is greater than 256kB, it falls back to the server-side apply.
|
ServerSideApply | ApplyStrategyTypeServerSideApply will use server-side apply to resolve conflicts between the resource to be placed
and the existing resource in the target cluster.
Details: https://kubernetes.io/docs/reference/using-api/server-side-apply
|
ReportDiff | ApplyStrategyTypeReportDiff will report differences between the desired state of a
resource as kept in the hub cluster and its current state (if applicable) on the member
cluster side. No actual apply ops would be executed.
|
ApprovalRequest
ApprovalRequest defines a request for user approval for staged update run.
The request object MUST have the following labels:
TargetUpdateRun: Points to the staged update run that this approval request is for.TargetStage: The name of the stage that this approval request is for.IsLatestUpdateRunApproval: Indicates whether this approval request is the latest one related to this update run.TaskType: Indicates whether this approval request is for the before or after stage task.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ApprovalRequest | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ApprovalRequestSpec | The desired state of ApprovalRequest. | | Required: {}
|
status ApprovalRequestStatus | The observed state of ApprovalRequest. | | Optional: {}
|
ApprovalRequestSpec
ApprovalRequestSpec defines the desired state of the update run approval request.
The entire spec is immutable.
Appears in:
| Field | Description | Default | Validation |
|---|
parentStageRollout string | The name of the staged update run that this approval request is for. | | Required: {}
|
targetStage string | The name of the update stage that this approval request is for. | | Required: {}
|
ApprovalRequestStatus
ApprovalRequestStatus defines the observed state of the ClusterApprovalRequest.
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions is an array of current observed conditions for the specific type of post-update task.
Known conditions are “Approved” and “ApprovalAccepted”. | | Optional: {}
|
BackReportedStatus
Appears in:
| Field | Description | Default | Validation |
|---|
observedStatus RawExtension | | | EmbeddedResource: {}
|
observationTime Time | ObservationTime is the timestamp when the status was last back reported. | | Format: date-time
Required: {}
Type: string
|
BindingState
Underlying type: string
BindingState is the state of the binding.
Appears in:
| Field | Description |
|---|
Scheduled | BindingStateScheduled means the binding is scheduled but need to be bound to the target cluster.
|
Bound | BindingStateBound means the binding is bound to the target cluster.
|
Unscheduled | BindingStateUnscheduled means the binding is not scheduled on to the target cluster anymore.
This is a state that rollout controller cares about.
The work generator still treat this as bound until rollout controller deletes the binding.
|
ClusterAffinity
ClusterAffinity contains cluster affinity scheduling rules for the selected resources.
Appears in:
| Field | Description | Default | Validation |
|---|
requiredDuringSchedulingIgnoredDuringExecution ClusterSelector | If the affinity requirements specified by this field are not met at
scheduling time, the resource will not be scheduled onto the cluster.
If the affinity requirements specified by this field cease to be met
at some point after the placement (e.g. due to an update), the system
may or may not try to eventually remove the resource from the cluster. | | Optional: {}
|
preferredDuringSchedulingIgnoredDuringExecution PreferredClusterSelector array | The scheduler computes a score for each cluster at schedule time by iterating
through the elements of this field and adding “weight” to the sum if the cluster
matches the corresponding matchExpression. The scheduler then chooses the first
N clusters with the highest sum to satisfy the placement.
This field is ignored if the placement type is “PickAll”.
If the cluster score changes at some point after the placement (e.g. due to an update),
the system may or may not try to eventually move the resource from a cluster with a lower score
to a cluster with higher score. | | Optional: {}
|
ClusterApprovalRequest
ClusterApprovalRequest defines a request for user approval for cluster staged update run.
The request object MUST have the following labels:
TargetUpdateRun: Points to the cluster staged update run that this approval request is for.TargetStage: The name of the stage that this approval request is for.IsLatestUpdateRunApproval: Indicates whether this approval request is the latest one related to this update run.TaskType: Indicates whether this approval request is for the before or after stage task.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterApprovalRequest | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ApprovalRequestSpec | The desired state of ClusterApprovalRequest. | | Required: {}
|
status ApprovalRequestStatus | The observed state of ClusterApprovalRequest. | | Optional: {}
|
ClusterDecision
ClusterDecision represents a decision from a placement
An empty ClusterDecision indicates it is not scheduled yet.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterName string | ClusterName is the name of the ManagedCluster. If it is not empty, its value should be unique cross all
placement decisions for the Placement. | | Required: {}
Required: {}
|
selected boolean | Selected indicates if this cluster is selected by the scheduler. | | Required: {}
|
clusterScore ClusterScore | ClusterScore represents the score of the cluster calculated by the scheduler. | | Optional: {}
|
reason string | Reason represents the reason why the cluster is selected or not. | | Required: {}
|
ClusterResourceBinding
ClusterResourceBinding represents a scheduling decision that binds a group of resources to a cluster.
It MUST have a label named CRPTrackingLabel that points to the cluster resource policy that creates it.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterResourceBinding | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceBindingSpec | The desired state of ClusterResourceBinding. | | Required: {}
|
status ResourceBindingStatus | The observed status of ClusterResourceBinding. | | Optional: {}
|
ClusterResourceEnvelope
ClusterResourceEnvelope wraps cluster-scoped resources for placement.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterResourceEnvelope | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
data object (keys:string, values:RawExtension) | The manifests wrapped in this envelope.
Each manifest is uniquely identified by a string key, typically a filename that represents
the manifest. The value is the manifest object itself. | | MaxProperties: 50
MinProperties: 1
Required: {}
|
ClusterResourceOverride
ClusterResourceOverride defines a group of override policies about how to override the selected cluster scope resources
to target clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterResourceOverride | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ClusterResourceOverrideSpec | The desired state of ClusterResourceOverrideSpec. | | Required: {}
|
ClusterResourceOverrideSnapshot
ClusterResourceOverrideSnapshot is used to store a snapshot of ClusterResourceOverride.
Its spec is immutable.
We assign an ever-increasing index for snapshots.
The naming convention of a ClusterResourceOverrideSnapshot is {ClusterResourceOverride}-{resourceIndex}.
resourceIndex will begin with 0.
Each snapshot MUST have the following labels:
OverrideTrackingLabel which points to its owner ClusterResourceOverride.IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterResourceOverrideSnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ClusterResourceOverrideSnapshotSpec | The desired state of ClusterResourceOverrideSnapshotSpec. | | Required: {}
|
ClusterResourceOverrideSnapshotSpec
ClusterResourceOverrideSnapshotSpec defines the desired state of ClusterResourceOverride.
Appears in:
| Field | Description | Default | Validation |
|---|
overrideSpec ClusterResourceOverrideSpec | OverrideSpec stores the spec of ClusterResourceOverride. | | |
overrideHash integer array | OverrideHash is the sha-256 hash value of the OverrideSpec field. | | Required: {}
|
ClusterResourceOverrideSpec
ClusterResourceOverrideSpec defines the desired state of the Override.
The ClusterResourceOverride create or update will fail when the resource has been selected by the existing ClusterResourceOverride.
If the resource is selected by both ClusterResourceOverride and ResourceOverride, ResourceOverride will win when resolving
conflicts.
Appears in:
| Field | Description | Default | Validation |
|---|
placement PlacementRef | Placement defines whether the override is applied to a specific placement or not.
If set, the override will trigger the placement rollout immediately when the rollout strategy type is RollingUpdate.
Otherwise, it will be applied to the next rollout.
The recommended way is to set the placement so that the override can be rolled out immediately. | | Optional: {}
|
clusterResourceSelectors ResourceSelectorTerm array | ClusterResourceSelectors is an array of selectors used to select cluster scoped resources. The selectors are ORed.
If a namespace is selected, ALL the resources under the namespace are selected automatically.
LabelSelector is not supported.
You can have 1-20 selectors.
We only support Name selector for now. | | MaxItems: 20
MinItems: 1
Required: {}
Required: {}
|
policy OverridePolicy | Policy defines how to override the selected resources on the target clusters. | | Required: {}
|
ClusterResourcePlacement
ClusterResourcePlacement is used to select cluster scoped resources, including built-in resources and custom resources,
and placement them onto selected member clusters in a fleet.
If a namespace is selected, ALL the resources under the namespace are placed to the target clusters.
Note that you can’t select the following resources:
- reserved namespaces including: default, kube-* (reserved for Kubernetes system namespaces),
fleet-* (reserved for fleet system namespaces).
- reserved fleet resource types including: MemberCluster, InternalMemberCluster, ClusterResourcePlacement,
ClusterSchedulingPolicySnapshot, ClusterResourceSnapshot, ClusterResourceBinding, etc.
ClusterSchedulingPolicySnapshot and ClusterResourceSnapshot objects are created when there are changes in the
system to keep the history of the changes affecting a ClusterResourcePlacement.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterResourcePlacement | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec PlacementSpec | The desired state of ClusterResourcePlacement. | | Required: {}
|
status PlacementStatus | The observed status of ClusterResourcePlacement. | | Optional: {}
|
ClusterResourcePlacementDisruptionBudget
ClusterResourcePlacementDisruptionBudget is the policy applied to a ClusterResourcePlacement
object that specifies its disruption budget, i.e., how many placements (clusters) can be
down at the same time due to voluntary disruptions (e.g., evictions). Involuntary
disruptions are not subject to this budget, but will still count against it.
To apply a ClusterResourcePlacementDisruptionBudget to a ClusterResourcePlacement, use the
same name for the ClusterResourcePlacementDisruptionBudget object as the ClusterResourcePlacement
object. This guarantees a 1:1 link between the two objects.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterResourcePlacementDisruptionBudget | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec PlacementDisruptionBudgetSpec | Spec is the desired state of the ClusterResourcePlacementDisruptionBudget. | | Required: {}
|
ClusterResourcePlacementEviction
ClusterResourcePlacementEviction is an eviction attempt on a specific placement from
a ClusterResourcePlacement object; one may use this API to force the removal of specific
resources from a cluster.
An eviction is a voluntary disruption; its execution is subject to the disruption budget
linked with the target ClusterResourcePlacement object (if present).
Beware that an eviction alone does not guarantee that a placement will not re-appear; i.e.,
after an eviction, the Fleet scheduler might still pick the previous target cluster for
placement. To prevent this, considering adding proper taints to the target cluster before running
an eviction that will exclude it from future placements; this is especially true in scenarios
where one would like to perform a cluster replacement.
For safety reasons, Fleet will only execute an eviction once; the spec in this object is immutable,
and once executed, the object will be ignored after. To trigger another eviction attempt on the
same placement from the same ClusterResourcePlacement object, one must re-create (delete and
create) the same Eviction object. Note also that an Eviction object will be
ignored once it is deemed invalid (e.g., such an object might be targeting a CRP object or
a placement that does not exist yet), even if it does become valid later
(e.g., the CRP object or the placement appears later). To fix the situation, re-create the
Eviction object.
Note: Eviction of resources from a cluster propagated by a PickFixed CRP is not allowed.
If the user wants to remove resources from a cluster propagated by a PickFixed CRP simply
remove the cluster name from cluster names field from the CRP spec.
Executed evictions might be kept around for a while for auditing purposes; the Fleet controllers might
have a TTL set up for such objects and will garbage collect them automatically. For further
information, see the Fleet documentation.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterResourcePlacementEviction | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec PlacementEvictionSpec | Spec is the desired state of the ClusterResourcePlacementEviction.
Note that all fields in the spec are immutable. | | Required: {}
|
status PlacementEvictionStatus | Status is the observed state of the ClusterResourcePlacementEviction. | | Optional: {}
|
ClusterResourcePlacementStatus
ClusterResourcePlacementStatus is a namespaced resource that mirrors the PlacementStatus of a corresponding
ClusterResourcePlacement object. This allows namespace-scoped access to cluster-scoped placement status.
The LastUpdatedTime field is updated whenever the CRPS object is updated.
This object will be created within the target namespace that contains resources being managed by the CRP.
When multiple ClusterResourcePlacements target the same namespace, each ClusterResourcePlacementStatus within that
namespace is uniquely identified by its object name, which corresponds to the specific ClusterResourcePlacement
that created it.
The name of this object should be the same as the name of the corresponding ClusterResourcePlacement.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterResourcePlacementStatus | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
sourceStatus PlacementStatus | Source status copied from the corresponding ClusterResourcePlacement. | | Required: {}
|
lastUpdatedTime Time | LastUpdatedTime is the timestamp when this CRPS object was last updated.
This field is set to the current time whenever the CRPS object is created or modified. | | Format: date-time
Required: {}
Type: string
|
ClusterResourceSnapshot
ClusterResourceSnapshot is used to store a snapshot of selected resources by a resource placement policy.
Its spec is immutable.
We may need to produce more than one resourceSnapshot for all the resources a ResourcePlacement selected to get around the 1MB size limit of k8s objects.
We assign an ever-increasing index for each such group of resourceSnapshots.
The naming convention of a clusterResourceSnapshot is {CRPName}-{resourceIndex}-{subindex}
where the name of the first snapshot of a group has no subindex part so its name is {CRPName}-{resourceIndex}-snapshot.
resourceIndex will begin with 0.
Each snapshot MUST have the following labels:
CRPTrackingLabel which points to its owner CRP.ResourceIndexLabel which is the index of the snapshot group.IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
All the snapshots within the same index group must have the same ResourceIndexLabel.
The first snapshot of the index group MUST have the following annotations:
NumberOfResourceSnapshotsAnnotation to store the total number of resource snapshots in the index group.ResourceGroupHashAnnotation whose value is the sha-256 hash of all the snapshots belong to the same snapshot index.
Each snapshot (excluding the first snapshot) MUST have the following annotations:
SubindexOfResourceSnapshotAnnotation to store the subindex of resource snapshot in the group.
Snapshot may have the following annotations to indicate the time of next resourceSnapshot candidate detected by the controller:
NextResourceSnapshotCandidateDetectionTimeAnnotation to store the time of next resourceSnapshot candidate detected by the controller.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterResourceSnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceSnapshotSpec | The desired state of ResourceSnapshot. | | Required: {}
|
status ResourceSnapshotStatus | The observed status of ResourceSnapshot. | | Optional: {}
|
ClusterSchedulingPolicySnapshot
ClusterSchedulingPolicySnapshot is used to store a snapshot of cluster placement policy.
Its spec is immutable.
The naming convention of a ClusterSchedulingPolicySnapshot is {CRPName}-{PolicySnapshotIndex}.
PolicySnapshotIndex will begin with 0.
Each snapshot must have the following labels:
CRPTrackingLabel which points to its owner CRP.PolicyIndexLabel which is the index of the policy snapshot.IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterSchedulingPolicySnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec SchedulingPolicySnapshotSpec | The desired state of SchedulingPolicySnapshot. | | Required: {}
|
status SchedulingPolicySnapshotStatus | The observed status of SchedulingPolicySnapshot. | | Optional: {}
|
ClusterScore
ClusterScore represents the score of the cluster calculated by the scheduler.
Appears in:
| Field | Description | Default | Validation |
|---|
affinityScore integer | AffinityScore represents the affinity score of the cluster calculated by the last
scheduling decision based on the preferred affinity selector.
An affinity score may not present if the cluster does not meet the required affinity. | | Optional: {}
|
priorityScore integer | TopologySpreadScore represents the priority score of the cluster calculated by the last
scheduling decision based on the topology spread applied to the cluster.
A priority score may not present if the cluster does not meet the topology spread. | | Optional: {}
|
ClusterSelector
Appears in:
| Field | Description | Default | Validation |
|---|
clusterSelectorTerms ClusterSelectorTerm array | ClusterSelectorTerms is a list of cluster selector terms. The terms are ORed. | | MaxItems: 10
Required: {}
|
ClusterSelectorTerm
Underlying type: struct{LabelSelector *k8s.io/apimachinery/pkg/apis/meta/v1.LabelSelector “json:"labelSelector,omitempty"”; PropertySelector *PropertySelector “json:"propertySelector,omitempty"”; PropertySorter *PropertySorter “json:"propertySorter,omitempty"”}
Appears in:
ClusterStagedUpdateRun
ClusterStagedUpdateRun represents a stage by stage update process that applies ClusterResourcePlacement
selected resources to specified clusters.
Resources from unselected clusters are removed after all stages in the update strategy are completed.
Each ClusterStagedUpdateRun object corresponds to a single release of a specific resource version.
The release is abandoned if the ClusterStagedUpdateRun object is deleted or the scheduling decision changes.
The name of the ClusterStagedUpdateRun must conform to RFC 1123.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterStagedUpdateRun | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec UpdateRunSpec | The desired state of ClusterStagedUpdateRun. | | Required: {}
|
status UpdateRunStatus | The observed status of ClusterStagedUpdateRun. | | Optional: {}
|
ClusterStagedUpdateStrategy
ClusterStagedUpdateStrategy defines a reusable strategy that specifies the stages and the sequence
in which the selected cluster resources will be updated on the member clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ClusterStagedUpdateStrategy | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec UpdateStrategySpec | The desired state of ClusterStagedUpdateStrategy. | | Required: {}
|
ClusterUpdatingStatus
ClusterUpdatingStatus defines the status of the update run on a cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterName string | The name of the cluster. | | Required: {}
|
resourceOverrideSnapshots NamespacedName array | ResourceOverrideSnapshots is a list of ResourceOverride snapshots associated with the cluster.
The list is computed at the beginning of the update run and not updated during the update run.
The list is empty if there are no resource overrides associated with the cluster. | | Optional: {}
|
clusterResourceOverrideSnapshots string array | ClusterResourceOverrides contains a list of applicable ClusterResourceOverride snapshot names
associated with the cluster.
The list is computed at the beginning of the update run and not updated during the update run.
The list is empty if there are no cluster overrides associated with the cluster. | | Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for clusters. Empty if the cluster has not started updating.
Known conditions are “Started”, “Succeeded”. | | Optional: {}
|
ComparisonOptionType
Underlying type: string
ComparisonOptionType describes the compare option that Fleet uses to detect drifts and/or
calculate differences.
Appears in:
| Field | Description |
|---|
PartialComparison | ComparisonOptionTypePartialComparison will compare only fields that are managed by Fleet, i.e.,
fields that are specified explicitly in the hub cluster manifest. Unmanaged fields
are ignored.
|
FullComparison | ComparisonOptionTypeFullDiff will compare all fields of the resource, even if the fields
are absent from the hub cluster manifest.
|
DeletePropagationPolicy
Underlying type: string
DeletePropagationPolicy identifies the propagation policy when a placement is deleted.
Appears in:
| Field | Description |
|---|
Abandon | DeletePropagationPolicyAbandon instructs Fleet to leave (abandon) all placed resources on member
clusters when the placement is deleted.
|
Delete | DeletePropagationPolicyDelete instructs Fleet to delete all placed resources on member clusters
when the placement is deleted. This is the default behavior.
|
DeleteStrategy
DeleteStrategy configures the deletion behavior when a placement is deleted.
Appears in:
| Field | Description | Default | Validation |
|---|
propagationPolicy DeletePropagationPolicy | PropagationPolicy controls whether to delete placed resources when placement is deleted.
Available options:
* Delete: all placed resources on member clusters will be deleted when
the placement is deleted. This is the default behavior.
* Abandon: all placed resources on member clusters will be left intact (abandoned)
when the placement is deleted. | Delete | Enum: [Abandon Delete]
Optional: {}
|
DiffDetails
DiffDetails describes the observed configuration differences.
Appears in:
| Field | Description | Default | Validation |
|---|
observationTime Time | ObservationTime is the timestamp when the configuration difference was last detected. | | Format: date-time
Required: {}
Type: string
|
observedInMemberClusterGeneration integer | ObservedInMemberClusterGeneration is the generation of the applied manifest on the member
cluster side.
This might be nil if the resource has not been created yet in the member cluster. | | Optional: {}
|
firstDiffedObservedTime Time | FirstDiffedObservedTime is the timestamp when the configuration difference
was first detected. | | Format: date-time
Required: {}
Type: string
|
observedDiffs PatchDetail array | ObservedDiffs describes each field with configuration difference as found from the
member cluster side.
Fleet might truncate the details as appropriate to control object size.
Each entry specifies how the live state (the state on the member cluster side) compares
against the desired state (the state kept in the hub cluster manifest). | | Optional: {}
|
DiffedResourcePlacement
DiffedResourcePlacement contains the details of a resource with configuration differences.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group is the group name of the selected resource. | | Optional: {}
|
version string | Version is the version of the selected resource. | | Required: {}
|
kind string | Kind represents the Kind of the selected resources. | | Required: {}
|
name string | Name of the target resource. | | Required: {}
|
namespace string | Namespace is the namespace of the resource. Empty if the resource is cluster scoped. | | Optional: {}
|
envelope EnvelopeIdentifier | Envelope identifies the envelope object that contains this resource. | | Optional: {}
|
observationTime Time | ObservationTime is the time when we observe the configuration differences for the resource. | | Format: date-time
Required: {}
Type: string
|
targetClusterObservedGeneration integer | TargetClusterObservedGeneration is the generation of the resource on the target cluster
that contains the configuration differences.
This might be nil if the resource has not been created yet on the target cluster. | | Optional: {}
|
firstDiffedObservedTime Time | FirstDiffedObservedTime is the first time the resource on the target cluster is
observed to have configuration differences. | | Format: date-time
Required: {}
Type: string
|
observedDiffs PatchDetail array | ObservedDiffs are the details about the found configuration differences. Note that
Fleet might truncate the details as appropriate to control the object size.
Each detail entry specifies how the live state (the state on the member
cluster side) compares against the desired state (the state kept in the hub cluster manifest).
An event about the details will be emitted as well. | | Optional: {}
|
DriftDetails
DriftDetails describes the observed configuration drifts.
Appears in:
| Field | Description | Default | Validation |
|---|
observationTime Time | ObservationTime is the timestamp when the drift was last detected. | | Format: date-time
Required: {}
Type: string
|
observedInMemberClusterGeneration integer | ObservedInMemberClusterGeneration is the generation of the applied manifest on the member
cluster side. | | Required: {}
|
firstDriftedObservedTime Time | FirstDriftedObservedTime is the timestamp when the drift was first detected. | | Format: date-time
Required: {}
Type: string
|
observedDrifts PatchDetail array | ObservedDrifts describes each drifted field found from the applied manifest.
Fleet might truncate the details as appropriate to control object size.
Each entry specifies how the live state (the state on the member cluster side) compares
against the desired state (the state kept in the hub cluster manifest). | | Optional: {}
|
DriftedResourcePlacement
DriftedResourcePlacement contains the details of a resource with configuration drifts.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group is the group name of the selected resource. | | Optional: {}
|
version string | Version is the version of the selected resource. | | Required: {}
|
kind string | Kind represents the Kind of the selected resources. | | Required: {}
|
name string | Name of the target resource. | | Required: {}
|
namespace string | Namespace is the namespace of the resource. Empty if the resource is cluster scoped. | | Optional: {}
|
envelope EnvelopeIdentifier | Envelope identifies the envelope object that contains this resource. | | Optional: {}
|
observationTime Time | ObservationTime is the time when we observe the configuration drifts for the resource. | | Format: date-time
Required: {}
Type: string
|
targetClusterObservedGeneration integer | TargetClusterObservedGeneration is the generation of the resource on the target cluster
that contains the configuration drifts. | | Required: {}
|
firstDriftedObservedTime Time | FirstDriftedObservedTime is the first time the resource on the target cluster is
observed to have configuration drifts. | | Format: date-time
Required: {}
Type: string
|
observedDrifts PatchDetail array | ObservedDrifts are the details about the found configuration drifts. Note that
Fleet might truncate the details as appropriate to control the object size.
Each detail entry specifies how the live state (the state on the member
cluster side) compares against the desired state (the state kept in the hub cluster manifest).
An event about the details will be emitted as well. | | Optional: {}
|
EnvelopeIdentifier
EnvelopeIdentifier identifies the envelope object that contains the selected resource.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | Name of the envelope object. | | Required: {}
|
namespace string | Namespace is the namespace of the envelope object. Empty if the envelope object is cluster scoped. | | Optional: {}
|
type EnvelopeType | Type of the envelope object. | ConfigMap | Enum: [ConfigMap ClusterResourceEnvelope ResourceEnvelope]
Optional: {}
|
EnvelopeType
Underlying type: string
EnvelopeType defines the type of the envelope object.
Appears in:
| Field | Description |
|---|
ConfigMap | ConfigMapEnvelopeType means the envelope object is of type ConfigMap.
TO-DO (chenyu1): drop this type after the configMap-based envelopes become obsolete.
|
ClusterResourceEnvelope | ClusterResourceEnvelopeType is the envelope type that represents the ClusterResourceEnvelope custom resource.
|
ResourceEnvelope | ResourceEnvelopeType is the envelope type that represents the ResourceEnvelope custom resource.
|
FailedResourcePlacement
FailedResourcePlacement contains the failure details of a failed resource placement.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group is the group name of the selected resource. | | Optional: {}
|
version string | Version is the version of the selected resource. | | Required: {}
|
kind string | Kind represents the Kind of the selected resources. | | Required: {}
|
name string | Name of the target resource. | | Required: {}
|
namespace string | Namespace is the namespace of the resource. Empty if the resource is cluster scoped. | | Optional: {}
|
envelope EnvelopeIdentifier | Envelope identifies the envelope object that contains this resource. | | Optional: {}
|
condition Condition | The failed condition status. | | Required: {}
|
JSONPatchOverride
JSONPatchOverride applies a JSON patch on the selected resources following RFC 6902.
Appears in:
| Field | Description | Default | Validation |
|---|
op JSONPatchOverrideOperator | Operator defines the operation on the target field. | | Enum: [add remove replace]
Required: {}
|
path string | Path defines the target location.
Note: override will fail if the resource path does not exist. | | Required: {}
|
value JSON | Value defines the content to be applied on the target location.
Value should be empty when operator is remove.
We have reserved a few variables in this field that will be replaced by the actual values.
Those variables all start with $ and are case sensitive.
Here is the list of currently supported variables:
$\{MEMBER-CLUSTER-NAME\}: this will be replaced by the name of the memberCluster CR that represents this cluster. | | Optional: {}
|
JSONPatchOverrideOperator
Underlying type: string
JSONPatchOverrideOperator defines the supported JSON patch operator.
Appears in:
| Field | Description |
|---|
add | JSONPatchOverrideOpAdd adds the value to the target location.
An example target JSON document:
{ “foo”: [ “bar”, “baz” ] }
A JSON Patch override:
[
{ “op”: “add”, “path”: “/foo/1”, “value”: “qux” }
]
The resulting JSON document:
{ “foo”: [ “bar”, “qux”, “baz” ] }
|
remove | JSONPatchOverrideOpRemove removes the value from the target location.
An example target JSON document:
{
“baz”: “qux”,
“foo”: “bar”
}
A JSON Patch override:
[
{ “op”: “remove”, “path”: “/baz” }
]
The resulting JSON document:
{ “foo”: “bar” }
|
replace | JSONPatchOverrideOpReplace replaces the value at the target location with a new value.
An example target JSON document:
{
“baz”: “qux”,
“foo”: “bar”
}
A JSON Patch override:
[
{ “op”: “replace”, “path”: “/baz”, “value”: “boo” }
]
The resulting JSON document:
{
“baz”: “boo”,
“foo”: “bar”
}
|
Manifest
Manifest represents a resource to be deployed on spoke cluster.
Appears in:
ManifestCondition
ManifestCondition represents the conditions of the resources deployed on
spoke cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
identifier WorkResourceIdentifier | resourceId represents a identity of a resource linking to manifests in spec. | | Required: {}
|
conditions Condition array | Conditions represents the conditions of this resource on spoke cluster | | Required: {}
|
driftDetails DriftDetails | DriftDetails explains about the observed configuration drifts.
Fleet might truncate the details as appropriate to control object size.
Note that configuration drifts can only occur on a resource if it is currently owned by
Fleet and its corresponding placement is set to use the ClientSideApply or ServerSideApply
apply strategy. In other words, DriftDetails and DiffDetails will not be populated
at the same time. | | Optional: {}
|
diffDetails DiffDetails | DiffDetails explains the details about the observed configuration differences.
Fleet might truncate the details as appropriate to control object size.
Note that configuration differences can only occur on a resource if it is not currently owned
by Fleet (i.e., it is a pre-existing resource that needs to be taken over), or if its
corresponding placement is set to use the ReportDiff apply strategy. In other words,
DiffDetails and DriftDetails will not be populated at the same time. | | Optional: {}
|
backReportedStatus BackReportedStatus | BackReportedStatus is the status reported back from the member cluster (if applicable). | | Optional: {}
|
NamespacedName
NamespacedName comprises a resource name, with a mandatory namespace.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | Name is the name of the namespaced scope resource. | | Required: {}
|
namespace string | Namespace is namespace of the namespaced scope resource. | | Required: {}
|
OverridePolicy
OverridePolicy defines how to override the selected resources on the target clusters.
More is to be added.
Appears in:
| Field | Description | Default | Validation |
|---|
overrideRules OverrideRule array | OverrideRules defines an array of override rules to be applied on the selected resources.
The order of the rules determines the override order.
When there are two rules selecting the same fields on the target cluster, the last one will win.
You can have 1-20 rules. | | MaxItems: 20
MinItems: 1
Required: {}
Required: {}
|
OverrideRule
OverrideRule defines how to override the selected resources on the target clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterSelector ClusterSelector | ClusterSelectors selects the target clusters.
The resources will be overridden before applying to the matching clusters.
An empty clusterSelector selects ALL the member clusters.
A nil clusterSelector selects NO member clusters.
For now, only labelSelector is supported. | | Optional: {}
|
overrideType OverrideType | OverrideType defines the type of the override rules. | JSONPatch | Enum: [JSONPatch Delete]
Optional: {}
|
jsonPatchOverrides JSONPatchOverride array | JSONPatchOverrides defines a list of JSON patch override rules.
This field is only allowed when OverrideType is JSONPatch. | | MaxItems: 20
MinItems: 1
Optional: {}
|
OverrideType
Underlying type: string
OverrideType defines the type of Override
Appears in:
| Field | Description |
|---|
JSONPatch | JSONPatchOverrideType applies a JSON patch on the selected resources following RFC 6902.
|
Delete | DeleteOverrideType deletes the selected resources on the target clusters.
|
PatchDetail
PatchDetail describes a patch that explains an observed configuration drift or
difference.
A patch detail can be transcribed as a JSON patch operation, as specified in RFC 6902.
Appears in:
| Field | Description | Default | Validation |
|---|
path string | The JSON path that points to a field that has drifted or has configuration differences. | | Required: {}
|
valueInMember string | The value at the JSON path from the member cluster side.
This field can be empty if the JSON path does not exist on the member cluster side; i.e.,
applying the manifest from the hub cluster side would add a new field. | | Optional: {}
|
valueInHub string | The value at the JSON path from the hub cluster side.
This field can be empty if the JSON path does not exist on the hub cluster side; i.e.,
applying the manifest from the hub cluster side would remove the field. | | Optional: {}
|
PerClusterPlacementStatus
PerClusterPlacementStatus represents the placement status of selected resources for one target cluster.
Appears in:
| Field | Description | Default | Validation |
|---|
clusterName string | ClusterName is the name of the cluster this resource is assigned to.
If it is not empty, its value should be unique cross all placement decisions for the Placement. | | Optional: {}
|
observedResourceIndex string | ObservedResourceIndex is the index of the resource snapshot that is currently being rolled out to the given cluster.
This field is only meaningful if the ClusterName is not empty. | | Optional: {}
|
applicableResourceOverrides NamespacedName array | ApplicableResourceOverrides contains a list of applicable ResourceOverride snapshots associated with the selected
resources.
This field is alpha-level and is for the override policy feature. | | Optional: {}
|
applicableClusterResourceOverrides string array | ApplicableClusterResourceOverrides contains a list of applicable ClusterResourceOverride snapshots associated with
the selected resources.
This field is alpha-level and is for the override policy feature. | | Optional: {}
|
failedPlacements FailedResourcePlacement array | FailedPlacements is a list of all the resources failed to be placed to the given cluster or the resource is unavailable.
Note that we only include 100 failed resource placements even if there are more than 100.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
driftedPlacements DriftedResourcePlacement array | DriftedPlacements is a list of resources that have drifted from their desired states
kept in the hub cluster, as found by Fleet using the drift detection mechanism.
To control the object size, only the first 100 drifted resources will be included.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
diffedPlacements DiffedResourcePlacement array | DiffedPlacements is a list of resources that have configuration differences from their
corresponding hub cluster manifests. Fleet will report such differences when:
* The CRP uses the ReportDiff apply strategy, which instructs Fleet to compare the hub
cluster manifests against the live resources without actually performing any apply op; or
* Fleet finds a pre-existing resource on the member cluster side that does not match its
hub cluster counterpart, and the CRP has been configured to only take over a resource if
no configuration differences are found.
To control the object size, only the first 100 diffed resources will be included.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions on the cluster.
Each condition corresponds to the resource snapshot at the index specified by ObservedResourceIndex.
For example, the condition of type RolloutStarted is observing the rollout status of the resource snapshot with index ObservedResourceIndex. | | Optional: {}
|
PlacementDisruptionBudgetSpec
PlacementDisruptionBudgetSpec is the desired state of the PlacementDisruptionBudget.
Appears in:
| Field | Description | Default | Validation |
|---|
maxUnavailable IntOrString | MaxUnavailable is the maximum number of placements (clusters) that can be down at the
same time due to voluntary disruptions. For example, a setting of 1 would imply that
a voluntary disruption (e.g., an eviction) can only happen if all placements (clusters)
from the linked Placement object are applied and available.
This can be either an absolute value (e.g., 1) or a percentage (e.g., 10%).
If a percentage is specified, Fleet will calculate the corresponding absolute values
as follows:
* if the linked Placement object is of the PickFixed placement type,
we don’t perform any calculation because eviction is not allowed for PickFixed CRP.
* if the linked Placement object is of the PickAll placement type, MaxUnavailable cannot
be specified since we cannot derive the total number of clusters selected.
* if the linked Placement object is of the PickN placement type,
the percentage is against the number of clusters specified in the placement (i.e., the
value of the NumberOfClusters fields in the placement policy).
The end result will be rounded up to the nearest integer if applicable.
One may use a value of 0 for this field; in this case, no voluntary disruption would be
allowed.
This field is mutually exclusive with the MinAvailable field in the spec; exactly one
of them can be set at a time. | | XIntOrString: {}
Optional: {}
|
minAvailable IntOrString | MinAvailable is the minimum number of placements (clusters) that must be available at any
time despite voluntary disruptions. For example, a setting of 10 would imply that
a voluntary disruption (e.g., an eviction) can only happen if there are at least 11
placements (clusters) from the linked Placement object are applied and available.
This can be either an absolute value (e.g., 1) or a percentage (e.g., 10%).
If a percentage is specified, Fleet will calculate the corresponding absolute values
as follows:
* if the linked Placement object is of the PickFixed placement type,
we don’t perform any calculation because eviction is not allowed for PickFixed CRP.
* if the linked Placement object is of the PickAll placement type, MinAvailable can be
specified but only as an integer since we cannot derive the total number of clusters selected.
* if the linked Placement object is of the PickN placement type,
the percentage is against the number of clusters specified in the placement (i.e., the
value of the NumberOfClusters fields in the placement policy).
The end result will be rounded up to the nearest integer if applicable.
One may use a value of 0 for this field; in this case, voluntary disruption would be
allowed at any time.
This field is mutually exclusive with the MaxUnavailable field in the spec; exactly one
of them can be set at a time. | | XIntOrString: {}
Optional: {}
|
PlacementEvictionSpec
PlacementEvictionSpec is the desired state of the parent PlacementEviction.
Appears in:
| Field | Description | Default | Validation |
|---|
placementName string | PlacementName is the name of the Placement object which
the Eviction object targets. | | MaxLength: 255
Required: {}
|
clusterName string | ClusterName is the name of the cluster that the Eviction object targets. | | MaxLength: 255
Required: {}
|
PlacementEvictionStatus
PlacementEvictionStatus is the observed state of the parent PlacementEviction.
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions is the list of currently observed conditions for the
PlacementEviction object.
Available condition types include:
* Valid: whether the Eviction object is valid, i.e., it targets at a valid placement.
* Executed: whether the Eviction object has been executed. | | Optional: {}
|
PlacementPolicy
PlacementPolicy contains the rules to select target member clusters to place the selected resources.
Note that only clusters that are both joined and satisfying the rules will be selected.
You can only specify at most one of the two fields: ClusterNames and Affinity.
If none is specified, all the joined clusters are selected.
Appears in:
| Field | Description | Default | Validation |
|---|
placementType PlacementType | Type of placement. Can be “PickAll”, “PickN” or “PickFixed”. Default is PickAll. | PickAll | Enum: [PickAll PickN PickFixed]
Optional: {}
|
clusterNames string array | ClusterNames contains a list of names of MemberCluster to place the selected resources.
Only valid if the placement type is “PickFixed” | | MaxItems: 100
Optional: {}
|
numberOfClusters integer | NumberOfClusters of placement. Only valid if the placement type is “PickN”. | | Minimum: 0
Optional: {}
|
affinity Affinity | Affinity contains cluster affinity scheduling rules. Defines which member clusters to place the selected resources.
Only valid if the placement type is “PickAll” or “PickN”. | | Optional: {}
|
topologySpreadConstraints TopologySpreadConstraint array | TopologySpreadConstraints describes how a group of resources ought to spread across multiple topology
domains. Scheduler will schedule resources in a way which abides by the constraints.
All topologySpreadConstraints are ANDed.
Only valid if the placement type is “PickN”. | | Optional: {}
|
tolerations Toleration array | If specified, the ClusterResourcePlacement’s Tolerations.
Tolerations cannot be updated or deleted.
This field is beta-level and is for the taints and tolerations feature. | | MaxItems: 100
Optional: {}
|
PlacementRef
PlacementRef is the reference to a placement.
For now, we only support ClusterResourcePlacement.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | Name is the reference to the name of placement. | | Required: {}
|
scope ResourceScope | Scope defines the scope of the placement.
A clusterResourceOverride can only reference a clusterResourcePlacement (cluster-scoped),
and a resourceOverride can reference either a clusterResourcePlacement or resourcePlacement (namespaced).
The referenced resourcePlacement must be in the same namespace as the resourceOverride. | Cluster | Enum: [Cluster Namespaced]
Optional: {}
|
PlacementSpec
PlacementSpec defines the desired state of ClusterResourcePlacement and ResourcePlacement.
Appears in:
| Field | Description | Default | Validation |
|---|
resourceSelectors ResourceSelectorTerm array | ResourceSelectors is an array of selectors used to select cluster scoped resources. The selectors are ORed.
You can have 1-100 selectors. | | MaxItems: 100
MinItems: 1
Required: {}
|
policy PlacementPolicy | Policy defines how to select member clusters to place the selected resources.
If unspecified, all the joined member clusters are selected. | | Optional: {}
|
strategy RolloutStrategy | The rollout strategy to use to replace existing placement with new ones. | | Optional: {}
|
revisionHistoryLimit integer | The number of old SchedulingPolicySnapshot or ResourceSnapshot resources to retain to allow rollback.
This is a pointer to distinguish between explicit zero and not specified.
Defaults to 10. | 10 | Maximum: 1000
Minimum: 1
Optional: {}
|
statusReportingScope StatusReportingScope | StatusReportingScope controls where ClusterResourcePlacement status information is made available.
When set to “ClusterScopeOnly”, status is accessible only through the cluster-scoped ClusterResourcePlacement object.
When set to “NamespaceAccessible”, a ClusterResourcePlacementStatus object is created in the target namespace,
providing namespace-scoped access to the placement status alongside the cluster-scoped status. This option is only
supported when the ClusterResourcePlacement targets exactly one namespace.
Defaults to “ClusterScopeOnly”. | ClusterScopeOnly | Enum: [ClusterScopeOnly NamespaceAccessible]
Optional: {}
|
PlacementStatus
PlacementStatus defines the observed status of the ClusterResourcePlacement and ResourcePlacement object.
Appears in:
| Field | Description | Default | Validation |
|---|
selectedResources ResourceIdentifier array | SelectedResources contains a list of resources selected by ResourceSelectors.
This field is only meaningful if the ObservedResourceIndex is not empty. | | Optional: {}
|
observedResourceIndex string | Resource index logically represents the generation of the selected resources.
We take a new snapshot of the selected resources whenever the selection or their content change.
Each snapshot has a different resource index.
One resource snapshot can contain multiple clusterResourceSnapshots CRs in order to store large amount of resources.
To get clusterResourceSnapshot of a given resource index, use the following command:
kubectl get ClusterResourceSnapshot --selector=kubernetes-fleet.io/resource-index=$ObservedResourceIndex
If the rollout strategy type is RollingUpdate, ObservedResourceIndex is the default-latest resource snapshot index.
If the rollout strategy type is External, rollout and version control are managed by an external controller,
and this field is not empty only if all targeted clusters observe the same resource index in PlacementStatuses. | | Optional: {}
|
placementStatuses PerClusterPlacementStatus array | PerClusterPlacementStatuses contains a list of placement status on the clusters that are selected by PlacementPolicy.
Each selected cluster according to the observed resource placement is guaranteed to have a corresponding placementStatuses.
In the pickN case, there are N placement statuses where N = NumberOfClusters; Or in the pickFixed case, there are
N placement statuses where N = ClusterNames.
In these cases, some of them may not have assigned clusters when we cannot fill the required number of clusters. | | Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for ClusterResourcePlacement.
All conditions except ClusterResourcePlacementScheduled correspond to the resource snapshot at the index specified by ObservedResourceIndex.
For example, a condition of ClusterResourcePlacementWorkSynchronized type
is observing the synchronization status of the resource snapshot with index ObservedResourceIndex.
If the rollout strategy type is External, and ObservedResourceIndex is unset due to clusters reporting different resource indices,
conditions except ClusterResourcePlacementScheduled will be empty or set to Unknown. | | Optional: {}
|
PlacementType
Underlying type: string
PlacementType identifies the type of placement.
Appears in:
| Field | Description |
|---|
PickAll | PickAllPlacementType picks all clusters that satisfy the rules.
|
PickN | PickNPlacementType picks N clusters that satisfy the rules.
|
PickFixed | PickFixedPlacementType picks a fixed set of clusters.
|
PreferredClusterSelector
Appears in:
| Field | Description | Default | Validation |
|---|
weight integer | Weight associated with matching the corresponding clusterSelectorTerm, in the range [-100, 100]. | | Maximum: 100
Minimum: -100
Required: {}
|
preference ClusterSelectorTerm | A cluster selector term, associated with the corresponding weight. | | Required: {}
|
PropertySelectorOperator
Underlying type: string
PropertySelectorOperator is the operator that can be used with PropertySelectorRequirements.
Appears in:
| Field | Description |
|---|
Gt | PropertySelectorGreaterThan dictates Fleet to select cluster if its observed value of a given
property is greater than the value specified in the requirement.
|
Ge | PropertySelectorGreaterThanOrEqualTo dictates Fleet to select cluster if its observed value
of a given property is greater than or equal to the value specified in the requirement.
|
Eq | PropertySelectorEqualTo dictates Fleet to select cluster if its observed value of a given
property is equal to the values specified in the requirement.
|
Ne | PropertySelectorNotEqualTo dictates Fleet to select cluster if its observed value of a given
property is not equal to the values specified in the requirement.
|
Lt | PropertySelectorLessThan dictates Fleet to select cluster if its observed value of a given
property is less than the value specified in the requirement.
|
Le | PropertySelectorLessThanOrEqualTo dictates Fleet to select cluster if its observed value of a
given property is less than or equal to the value specified in the requirement.
|
PropertySelectorRequirement
PropertySelectorRequirement is a specific property requirement when picking clusters for
resource placement.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | Name is the name of the property; it should be a Kubernetes label name. | | Required: {}
|
operator PropertySelectorOperator | Operator specifies the relationship between a cluster’s observed value of the specified
property and the values given in the requirement. | | Required: {}
|
values string array | Values are a list of values of the specified property which Fleet will compare against
the observed values of individual member clusters in accordance with the given
operator.
At this moment, each value should be a Kubernetes quantity. For more information, see
https://pkg.go.dev/k8s.io/apimachinery/pkg/api/resource#Quantity.
If the operator is Gt (greater than), Ge (greater than or equal to), Lt (less than),
or Le (less than or equal to), Eq (equal to), or Ne (ne), exactly one value must be
specified in the list. | | MaxItems: 1
Required: {}
|
PropertySortOrder
Underlying type: string
Appears in:
| Field | Description |
|---|
Descending | Descending instructs Fleet to sort in descending order, that is, the clusters with higher
observed values of a property are most preferred and should have higher weights. We will
use linear scaling to calculate the weight for each cluster based on the observed values.
For example, with this order, if Fleet sorts all clusters by a specific property where the
observed values are in the range [10, 100], and a weight of 100 is specified;
Fleet will assign:
* a weight of 100 to the cluster with the maximum observed value (100); and
* a weight of 0 to the cluster with the minimum observed value (10); and
* a weight of 11 to the cluster with an observed value of 20.
It is calculated using the formula below:
((20 - 10)) / (100 - 10)) * 100 = 11
|
Ascending | Ascending instructs Fleet to sort in ascending order, that is, the clusters with lower
observed values are most preferred and should have higher weights. We will use linear scaling
to calculate the weight for each cluster based on the observed values.
For example, with this order, if Fleet sorts all clusters by a specific property where
the observed values are in the range [10, 100], and a weight of 100 is specified;
Fleet will assign:
* a weight of 0 to the cluster with the maximum observed value (100); and
* a weight of 100 to the cluster with the minimum observed value (10); and
* a weight of 89 to the cluster with an observed value of 20.
It is calculated using the formula below:
(1 - ((20 - 10) / (100 - 10))) * 100 = 89
|
ReportBackDestination
Underlying type: string
Appears in:
| Field | Description |
|---|
OriginalResource | ReportBackDestinationOriginalResource implies the status fields will be copied verbatim to the
the original resource on the hub cluster side. This is only performed when the placement object has a
scheduling policy that selects exactly one member cluster (i.e., a pickFixed scheduling policy with
exactly one cluster name, or a pickN scheduling policy with the numberOfClusters field set to 1).
|
WorkAPI | ReportBackDestinationWorkAPI implies the status fields will be copied verbatim via the Work API
on the hub cluster side. Users may look up the status of a specific resource applied to a specific
member cluster by inspecting the corresponding Work object on the hub cluster side.
|
ReportBackStrategy
ReportBackStrategy describes how to report back the resource status from member clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
type ReportBackStrategyType | Type dictates the type of the report back strategy to use.
Available options include:
* Disabled: status back-reporting is disabled. This is the default behavior.
* Mirror: status back-reporting is enabled by copying the status fields verbatim to
a destination on the hub cluster side; see the Destination field for more information. | Disabled | Enum: [Disabled Mirror]
Required: {}
|
destination ReportBackDestination | Destination dictates where to copy the status fields to when the report back strategy type is Mirror.
Available options include:
* OriginalResource: the status fields will be copied verbatim to the original resource on the hub cluster side.
This is only performed when the placement object has a scheduling policy that selects exactly one member cluster
(i.e., a pickFixed scheduling policy with exactly one cluster name, or a pickN scheduling policy with the numberOfClusters
field set to 1).
* WorkAPI: the status fields will be copied verbatim via the Work API on the hub cluster side. Users may look up
the status of a specific resource applied to a specific member cluster by inspecting the corresponding Work object
on the hub cluster side. This is the default behavior. | | Enum: [OriginalResource WorkAPI]
Optional: {}
|
ReportBackStrategyType
Underlying type: string
Appears in:
| Field | Description |
|---|
Disabled | ReportBackStrategyTypeDisabled disables status back-reporting from the member clusters.
|
Mirror | ReportBackStrategyTypeMirror enables status back-reporting by
copying the status fields verbatim to some destination on the hub cluster side.
|
ResourceBinding
ResourceBinding represents a scheduling decision that binds a group of resources to a cluster.
It MUST have a label named CRPTrackingLabel that points to the resource placement that creates it.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ResourceBinding | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceBindingSpec | The desired state of ResourceBinding. | | Required: {}
|
status ResourceBindingStatus | The observed status of ResourceBinding. | | Optional: {}
|
ResourceBindingSpec
ResourceBindingSpec defines the desired state of ClusterResourceBinding.
Appears in:
| Field | Description | Default | Validation |
|---|
state BindingState | The desired state of the binding. Possible values: Scheduled, Bound, Unscheduled. | | Required: {}
|
resourceSnapshotName string | ResourceSnapshotName is the name of the resource snapshot that this resource binding points to.
If the resources are divided into multiple snapshots because of the resource size limit,
it points to the name of the leading snapshot of the index group. | | |
resourceOverrideSnapshots NamespacedName array | ResourceOverrideSnapshots is a list of ResourceOverride snapshots associated with the selected resources. | | |
clusterResourceOverrideSnapshots string array | ClusterResourceOverrides contains a list of applicable ClusterResourceOverride snapshot names associated with the
selected resources. | | |
schedulingPolicySnapshotName string | SchedulingPolicySnapshotName is the name of the scheduling policy snapshot that this resource binding
points to; more specifically, the scheduler creates this bindings in accordance with this
scheduling policy snapshot. | | |
targetCluster string | TargetCluster is the name of the cluster that the scheduler assigns the resources to. | | |
clusterDecision ClusterDecision | ClusterDecision explains why the scheduler selected this cluster. | | |
applyStrategy ApplyStrategy | ApplyStrategy describes how to resolve the conflict if the resource to be placed already exists in the target cluster
and is owned by other appliers. | | Optional: {}
|
ResourceBindingStatus
ResourceBindingStatus represents the current status of a ClusterResourceBinding.
Appears in:
| Field | Description | Default | Validation |
|---|
failedPlacements FailedResourcePlacement array | FailedPlacements is a list of all the resources failed to be placed to the given cluster or the resource is unavailable.
Note that we only include 100 failed resource placements even if there are more than 100. | | MaxItems: 100
Optional: {}
|
driftedPlacements DriftedResourcePlacement array | DriftedPlacements is a list of resources that have drifted from their desired states
kept in the hub cluster, as found by Fleet using the drift detection mechanism.
To control the object size, only the first 100 drifted resources will be included.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
diffedPlacements DiffedResourcePlacement array | DiffedPlacements is a list of resources that have configuration differences from their
corresponding hub cluster manifests. Fleet will report such differences when:
* The CRP uses the ReportDiff apply strategy, which instructs Fleet to compare the hub
cluster manifests against the live resources without actually performing any apply op; or
* Fleet finds a pre-existing resource on the member cluster side that does not match its
hub cluster counterpart, and the CRP has been configured to only take over a resource if
no configuration differences are found.
To control the object size, only the first 100 diffed resources will be included.
This field is only meaningful if the ClusterName is not empty. | | MaxItems: 100
Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for ClusterResourceBinding. | | Optional: {}
|
ResourceContent
ResourceContent contains the content of a resource
Appears in:
ResourceEnvelope
ResourceEnvelope wraps namespaced resources for placement.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ResourceEnvelope | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
data object (keys:string, values:RawExtension) | The manifests wrapped in this envelope.
Each manifest is uniquely identified by a string key, typically a filename that represents
the manifest. The value is the manifest object itself. | | MaxProperties: 50
MinProperties: 1
Required: {}
|
ResourceIdentifier
ResourceIdentifier identifies one Kubernetes resource.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group is the group name of the selected resource. | | Optional: {}
|
version string | Version is the version of the selected resource. | | Required: {}
|
kind string | Kind represents the Kind of the selected resources. | | Required: {}
|
name string | Name of the target resource. | | Required: {}
|
namespace string | Namespace is the namespace of the resource. Empty if the resource is cluster scoped. | | Optional: {}
|
envelope EnvelopeIdentifier | Envelope identifies the envelope object that contains this resource. | | Optional: {}
|
ResourceOverride
ResourceOverride defines a group of override policies about how to override the selected namespaced scope resources
to target clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ResourceOverride | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceOverrideSpec | The desired state of ResourceOverrideSpec. | | Required: {}
|
ResourceOverrideSnapshot
ResourceOverrideSnapshot is used to store a snapshot of ResourceOverride.
Its spec is immutable.
We assign an ever-increasing index for snapshots.
The naming convention of a ResourceOverrideSnapshot is {ResourceOverride}-{resourceIndex}.
resourceIndex will begin with 0.
Each snapshot MUST have the following labels:
OverrideTrackingLabel which points to its owner ResourceOverride.IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ResourceOverrideSnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceOverrideSnapshotSpec | The desired state of ResourceOverrideSnapshot. | | Required: {}
|
ResourceOverrideSnapshotSpec
ResourceOverrideSnapshotSpec defines the desired state of ResourceOverride.
Appears in:
| Field | Description | Default | Validation |
|---|
overrideSpec ResourceOverrideSpec | OverrideSpec stores the spec of ResourceOverride. | | |
overrideHash integer array | OverrideHash is the sha-256 hash value of the OverrideSpec field. | | Required: {}
|
ResourceOverrideSpec
ResourceOverrideSpec defines the desired state of the Override.
The ResourceOverride create or update will fail when the resource has been selected by the existing ResourceOverride.
If the resource is selected by both ClusterResourceOverride and ResourceOverride, ResourceOverride will win when resolving
conflicts.
Appears in:
| Field | Description | Default | Validation |
|---|
placement PlacementRef | Placement defines whether the override is applied to a specific placement or not.
If set, the override will trigger the placement rollout immediately when the rollout strategy type is RollingUpdate.
Otherwise, it will be applied to the next rollout.
The recommended way is to set the placement so that the override can be rolled out immediately. | | Optional: {}
|
resourceSelectors ResourceSelector array | ResourceSelectors is an array of selectors used to select namespace scoped resources. The selectors are ORed.
You can have 1-20 selectors. | | MaxItems: 20
MinItems: 1
Required: {}
Required: {}
|
policy OverridePolicy | Policy defines how to override the selected resources on the target clusters. | | Required: {}
|
ResourcePlacement
ResourcePlacement is used to select namespace scoped resources, including built-in resources and custom resources,
and placement them onto selected member clusters in a fleet.
SchedulingPolicySnapshot and ResourceSnapshot objects are created in the same namespace when there are changes in the
system to keep the history of the changes affecting a ResourcePlacement. We will also create ResourceBinding objects in the same namespace.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ResourcePlacement | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec PlacementSpec | The desired state of ResourcePlacement. | | Required: {}
|
status PlacementStatus | The observed status of ResourcePlacement. | | Optional: {}
|
ResourceScope
Underlying type: string
ResourceScope defines the scope of placement reference.
Appears in:
| Field | Description |
|---|
Cluster | ClusterScoped indicates placement is cluster-scoped.
|
Namespaced | NamespaceScoped indicates placement is namespace-scoped.
|
ResourceSelector
ResourceSelector is used to select namespace scoped resources as the target resources to be placed.
All the fields are ANDed. In other words, a resource must match all the fields to be selected.
The resource namespace will inherit from the parent object scope.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group name of the namespace-scoped resource.
Use an empty string to select resources under the core API group (e.g., services). | | Required: {}
|
version string | Version of the namespace-scoped resource. | | Required: {}
|
kind string | Kind of the namespace-scoped resource. | | Required: {}
|
name string | Name of the namespace-scoped resource. | | Required: {}
|
ResourceSelectorTerm
ResourceSelectorTerm is used to select resources as the target resources to be placed.
All the fields are ANDed. In other words, a resource must match all the fields to be selected.
Appears in:
| Field | Description | Default | Validation |
|---|
group string | Group name of the be selected resource.
Use an empty string to select resources under the core API group (e.g., namespaces). | | Required: {}
|
version string | Version of the to be selected resource. | | Required: {}
|
kind string | Kind of the to be selected resource.
Special behavior when Kind is namespace (ClusterResourcePlacement only):
Note: ResourcePlacement cannot select namespaces since it is namespace-scoped and selects resources within a namespace.
For ClusterResourcePlacement, you can use SelectionScope to control what gets selected:
- NamespaceOnly: Only the namespace object itself
- NamespaceWithResources: The namespace AND all resources within it (default)
- NamespaceWithResourceSelectors: The namespace AND resources specified by additional selectors
When SelectionScope is NamespaceWithResourceSelectors, you can define additional ResourceSelectorTerms
(after the namespace selector) to specify which resources to include. These additional selectors can
target both namespace-scoped resources (within the selected namespace) and cluster-scoped resources.
Important requirements for NamespaceWithResourceSelectors mode:
- Exactly one namespace selector with this mode is allowed
- The namespace selector must select by name (not by label)
- Only one namespace selector is allowed when using this mode (cannot mix with other namespace selectors)
- All requirements are validated via CEL at API validation time
- If the selected namespace is deleted after CRP creation, the controller will report an error condition
Example using NamespaceWithResourceSelectors:
- Namespace selector: {Group: “”, Version: “v1”, Kind: “Namespace”, Name: “prod”, SelectionScope: “NamespaceWithResourceSelectors”}
- Additional selector: {Group: “apps”, Version: “v1”, Kind: “Deployment”, LabelSelector: {app: “frontend”}}
- Third selector: {Group: “rbac.authorization.k8s.io”, Version: “v1”, Kind: “ClusterRole”, Name: “admin”}
This selects: the “prod” namespace, all Deployments with label app=frontend in “prod”, and the “admin” ClusterRole. | | Required: {}
|
name string | Name of the be selected resource. | | Optional: {}
|
labelSelector LabelSelector | A label query over all the be selected resources. Resources matching the query are selected.
Note that namespace-scoped resources can’t be selected even if they match the query. | | Optional: {}
|
selectionScope SelectionScope | SelectionScope defines the scope of resource selections when the Kind is namespace.
This field is only applicable when Kind is “Namespace” and is ignored for other resource kinds.
See the Kind field documentation for detailed examples and usage patterns. | NamespaceWithResources | Enum: [NamespaceOnly NamespaceWithResources NamespaceWithResourceSelectors]
Optional: {}
|
ResourceSnapshot
ResourceSnapshot is used to store a snapshot of selected resources by a resource placement policy.
Its spec is immutable.
We may need to produce more than one resourceSnapshot for all the resources a ResourcePlacement selected to get around the 1MB size limit of k8s objects.
We assign an ever-increasing index for each such group of resourceSnapshots.
The naming convention of a resourceSnapshot is {RPName}-{resourceIndex}-{subindex}
where the name of the first snapshot of a group has no subindex part so its name is {RPName}-{resourceIndex}-snapshot.
resourceIndex will begin with 0.
Each snapshot MUST have the following labels:
CRPTrackingLabel which points to its owner resource placement.ResourceIndexLabel which is the index of the snapshot group.
The first snapshot of the index group MAY have the following labels:
IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
All the snapshots within the same index group must have the same ResourceIndexLabel.
The first snapshot of the index group MUST have the following annotations:
NumberOfResourceSnapshotsAnnotation to store the total number of resource snapshots in the index group.ResourceGroupHashAnnotation whose value is the sha-256 hash of all the snapshots belong to the same snapshot index.
Each snapshot (excluding the first snapshot) MUST have the following annotations:
SubindexOfResourceSnapshotAnnotation to store the subindex of resource snapshot in the group.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | ResourceSnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec ResourceSnapshotSpec | The desired state of ResourceSnapshot. | | Required: {}
|
status ResourceSnapshotStatus | The observed status of ResourceSnapshot. | | Optional: {}
|
ResourceSnapshotSpec
ResourceSnapshotSpec defines the desired state of ResourceSnapshot.
Appears in:
| Field | Description | Default | Validation |
|---|
selectedResources ResourceContent array | SelectedResources contains a list of resources selected by ResourceSelectors. | | Required: {}
|
ResourceSnapshotStatus
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions is an array of current observed conditions for ResourceSnapshot. | | Optional: {}
|
RollingUpdateConfig
RollingUpdateConfig contains the config to control the desired behavior of rolling update.
Appears in:
| Field | Description | Default | Validation |
|---|
maxUnavailable IntOrString | The maximum number of clusters that can be unavailable during the rolling update
comparing to the desired number of clusters.
The desired number equals to the NumberOfClusters field when the placement type is PickN.
The desired number equals to the number of clusters scheduler selected when the placement type is PickAll.
Value can be an absolute number (ex: 5) or a percentage of the desired number of clusters (ex: 10%).
Absolute number is calculated from percentage by rounding up.
We consider a resource unavailable when we either remove it from a cluster or in-place
upgrade the resources content on the same cluster.
The minimum of MaxUnavailable is 0 to allow no downtime moving a placement from one cluster to another.
Please set it to be greater than 0 to avoid rolling out stuck during in-place resource update.
Defaults to 25%. | 25% | Optional: {}
Pattern: ^((100|[0-9]\{1,2\})%|[0-9]+)$
XIntOrString: {}
|
maxSurge IntOrString | The maximum number of clusters that can be scheduled above the desired number of clusters.
The desired number equals to the NumberOfClusters field when the placement type is PickN.
The desired number equals to the number of clusters scheduler selected when the placement type is PickAll.
Value can be an absolute number (ex: 5) or a percentage of desire (ex: 10%).
Absolute number is calculated from percentage by rounding up.
This does not apply to the case that we do in-place update of resources on the same cluster.
This can not be 0 if MaxUnavailable is 0.
Defaults to 25%. | 25% | Optional: {}
Pattern: ^((100|[0-9]\{1,2\})%|[0-9]+)$
XIntOrString: {}
|
unavailablePeriodSeconds integer | UnavailablePeriodSeconds is used to configure the waiting time between rollout phases when we
cannot determine if the resources have rolled out successfully or not.
We have a built-in resource state detector to determine the availability status of following well-known Kubernetes
native resources: Deployment, StatefulSet, DaemonSet, Service, Namespace, ConfigMap, Secret,
ClusterRole, ClusterRoleBinding, Role, RoleBinding.
Please see SafeRollout for more details.
For other types of resources, we consider them as available after UnavailablePeriodSeconds seconds
have passed since they were successfully applied to the target cluster.
Default is 60. | 60 | Optional: {}
|
RolloutStrategy
RolloutStrategy describes how to roll out a new change in selected resources to target clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
type RolloutStrategyType | Type of rollout. The only supported types are “RollingUpdate” and “External”.
Default is “RollingUpdate”. | RollingUpdate | Enum: [RollingUpdate External]
|
rollingUpdate RollingUpdateConfig | Rolling update config params. Present only if RolloutStrategyType = RollingUpdate. | | Optional: {}
|
applyStrategy ApplyStrategy | ApplyStrategy describes when and how to apply the selected resources to the target cluster. | | Optional: {}
|
deleteStrategy DeleteStrategy | DeleteStrategy configures the deletion behavior when the ClusterResourcePlacement is deleted. | | Optional: {}
|
reportBackStrategy ReportBackStrategy | ReportBackStrategy describes how to report back the status of applied resources on the member cluster. | | Optional: {}
|
RolloutStrategyType
Underlying type: string
Appears in:
| Field | Description |
|---|
RollingUpdate | RollingUpdateRolloutStrategyType replaces the old placed resource using rolling update
i.e. gradually create the new one while replace the old ones.
|
External | ExternalRolloutStrategyType means there is an external rollout controller that will
handle the rollout of the resources.
|
SchedulingPolicySnapshot
SchedulingPolicySnapshot is used to store a snapshot of cluster placement policy.
Its spec is immutable.
The naming convention of a SchedulingPolicySnapshot is {RPName}-{PolicySnapshotIndex}.
PolicySnapshotIndex will begin with 0.
Each snapshot must have the following labels:
CRPTrackingLabel which points to its placement owner.PolicyIndexLabel which is the index of the policy snapshot.IsLatestSnapshotLabel which indicates whether the snapshot is the latest one.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | SchedulingPolicySnapshot | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec SchedulingPolicySnapshotSpec | The desired state of SchedulingPolicySnapshot. | | Required: {}
|
status SchedulingPolicySnapshotStatus | The observed status of SchedulingPolicySnapshot. | | Optional: {}
|
SchedulingPolicySnapshotSpec
SchedulingPolicySnapshotSpec defines the desired state of SchedulingPolicySnapshot.
Appears in:
| Field | Description | Default | Validation |
|---|
policy PlacementPolicy | Policy defines how to select member clusters to place the selected resources.
If unspecified, all the joined member clusters are selected. | | Optional: {}
|
policyHash integer array | PolicyHash is the sha-256 hash value of the Policy field. | | Required: {}
|
SchedulingPolicySnapshotStatus
SchedulingPolicySnapshotStatus defines the observed state of SchedulingPolicySnapshot.
Appears in:
| Field | Description | Default | Validation |
|---|
observedCRPGeneration integer | ObservedCRPGeneration is the generation of the resource placement which the scheduler uses to perform
the scheduling cycle and prepare the scheduling status. | | Required: {}
|
conditions Condition array | Conditions is an array of current observed conditions for SchedulingPolicySnapshot. | | Optional: {}
|
targetClusters ClusterDecision array | ClusterDecisions contains a list of names of member clusters considered by the scheduler.
Note that all the selected clusters must present in the list while not all the
member clusters are guaranteed to be listed due to the size limit. We will try to
add the clusters that can provide the most insight to the list first. | | MaxItems: 1000
Optional: {}
|
SelectionScope
Underlying type: string
SelectionScope defines the scope of resource selections when selecting namespaces.
This only applies when a ResourceSelectorTerm has Kind=“Namespace”.
Appears in:
| Field | Description |
|---|
NamespaceOnly | NamespaceOnly means only the namespace object itself is selected.
Use case: When you want to create/manage only the namespace without any resources inside it.
Example: Creating a namespace with specific labels/annotations on member clusters.
|
NamespaceWithResources | NamespaceWithResources means the namespace and ALL resources within it are selected.
This is the default behavior for backward compatibility.
Use case: When you want to replicate an entire namespace with all its contents to member clusters.
Example: Copying a complete application stack (deployments, services, configmaps, etc.) across clusters.
Note: This is the default value. When you select a namespace without specifying SelectionScope,
this mode is used automatically.
|
NamespaceWithResourceSelectors | NamespaceWithResourceSelectors allows fine-grained selection of specific resources within a namespace.
The namespace itself is always selected, and you can optionally specify which resources to include
by adding additional ResourceSelectorTerm entries after the namespace selector.
Use cases:
1. Select only specific resource types from a namespace (e.g., only Deployments and Services)
2. Select resources matching certain labels within a namespace
3. Include specific cluster-scoped resources along with namespace-scoped resources
How “additional selectors” work:
- Exactly one namespace selector with NamespaceWithResourceSelectors mode is required
- This selector must select a namespace by name (label selectors not allowed)
- ADDITIONAL selectors specify which resources to include:
- Namespace-scoped resources are filtered to only those within the selected namespace
- Cluster-scoped resources are included as specified (not limited to the namespace)
- If no additional selectors are provided, only the namespace object itself is selected
Example 1 - Select specific deployments from a namespace:
Selector 1: {Group: “”, Version: “v1”, Kind: “Namespace”, Name: “production”, SelectionScope: “NamespaceWithResourceSelectors”}
Selector 2: {Group: “apps”, Version: “v1”, Kind: “Deployment”, LabelSelector: {tier: “frontend”}}
Result: The “production” namespace + all Deployments labeled tier=frontend within “production”
Example 2 - Select namespace with multiple resource types:
Selector 1: {Group: “”, Version: “v1”, Kind: “Namespace”, Name: “app”, SelectionScope: “NamespaceWithResourceSelectors”}
Selector 2: {Group: “apps”, Version: “v1”, Kind: “Deployment”}
Selector 3: {Group: “”, Version: “v1”, Kind: “Service”}
Result: The “app” namespace + ALL Deployments and Services within “app”
Example 3 - Include cluster-scoped resources:
Selector 1: {Group: “”, Version: “v1”, Kind: “Namespace”, Name: “app”, SelectionScope: “NamespaceWithResourceSelectors”}
Selector 2: {Group: “apps”, Version: “v1”, Kind: “Deployment”}
Selector 3: {Group: “rbac.authorization.k8s.io”, Version: “v1”, Kind: “ClusterRole”, Name: “app-admin”}
Result: The “app” namespace + ALL Deployments in “app” + the “app-admin” ClusterRole
Important constraints:
- Exactly ONE namespace selector with NamespaceWithResourceSelectors mode is allowed
- The namespace selector must select by name (label selectors not allowed)
- Only ONE namespace selector total is allowed when using this mode (cannot mix with other namespace selectors)
- All constraints are enforced via CEL at API validation time
Runtime behavior:
- If the selected namespace is deleted after the CRP is created, the controller will detect this during
the next reconciliation and report an error condition in the CRP status
- The CRP will transition to a failed state until the namespace is recreated or the CRP is updated
|
ServerSideApplyConfig
ServerSideApplyConfig defines the configuration for server side apply.
Details: https://kubernetes.io/docs/reference/using-api/server-side-apply/#conflicts
Appears in:
| Field | Description | Default | Validation |
|---|
force boolean | Force represents to force apply to succeed when resolving the conflicts
For any conflicting fields,
- If true, use the values from the resource to be applied to overwrite the values of the existing resource in the
target cluster, as well as take over ownership of such fields.
- If false, apply will fail with the reason ApplyConflictWithOtherApplier.
For non-conflicting fields, values stay unchanged and ownership are shared between appliers. | | Optional: {}
|
StageConfig
StageConfig describes a single update stage.
The clusters in each stage are updated sequentially.
The update stops if any of the updates fail.
Appears in:
| Field | Description | Default | Validation |
|---|
name string | The name of the stage. This MUST be unique within the same StagedUpdateStrategy. | | MaxLength: 63
Pattern: ^[a-z0-9]+$
Required: {}
|
labelSelector LabelSelector | LabelSelector is a label query over all the joined member clusters. Clusters matching the query are selected
for this stage. There cannot be overlapping clusters between stages when the stagedUpdateRun is created.
If the label selector is empty, the stage includes all the selected clusters.
If the label selector is nil, the stage does not include any selected clusters. | | Optional: {}
|
sortingLabelKey string | The label key used to sort the selected clusters.
The clusters within the stage are updated sequentially following the rule below:
- primary: Ascending order based on the value of the label key, interpreted as integers if present.
- secondary: Ascending order based on the name of the cluster if the label key is absent or the label value is the same. | | Optional: {}
|
maxConcurrency IntOrString | MaxConcurrency specifies the maximum number of clusters that can be updated concurrently within this stage.
Value can be an absolute number (ex: 5) or a percentage of the total clusters in the stage (ex: 50%).
Fractional results are rounded down. A minimum of 1 update is enforced.
If not specified, all clusters in the stage are updated sequentially (effectively maxConcurrency = 1).
Defaults to 1. | 1 | Optional: {}
Pattern: ^(100|[1-9][0-9]?)%$
XIntOrString: {}
|
afterStageTasks StageTask array | The collection of tasks that each stage needs to complete successfully before moving to the next stage.
Each task is executed in parallel and there cannot be more than one task of the same type. | | MaxItems: 2
Optional: {}
|
beforeStageTasks StageTask array | The collection of tasks that needs to completed successfully by each stage before starting the stage.
Each task is executed in parallel and there cannot be more than one task of the same type. | | MaxItems: 1
Optional: {}
|
StageTask
StageTask is the pre or post stage task that needs to be completed before starting or moving to the next stage.
Appears in:
| Field | Description | Default | Validation |
|---|
type StageTaskType | The type of the before or after stage task. | | Enum: [TimedWait Approval]
Required: {}
|
waitTime Duration | The time to wait after all the clusters in the current stage complete the update before moving to the next stage. | | Optional: {}
Pattern: ^0|([0-9]+(\.[0-9]+)?(s|m|h))+$
Type: string
|
StageTaskStatus
Appears in:
| Field | Description | Default | Validation |
|---|
type StageTaskType | The type of the pre or post update task. | | Enum: [TimedWait Approval]
Required: {}
|
approvalRequestName string | The name of the approval request object that is created for this stage.
Only valid if the AfterStageTaskType is Approval. | | Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for the specific type of pre or post update task.
Known conditions are “ApprovalRequestCreated”, “WaitTimeElapsed”, and “ApprovalRequestApproved”. | | Optional: {}
|
StageTaskType
Underlying type: string
StageTaskType identifies a specific type of the AfterStageTask or BeforeStageTask.
Appears in:
| Field | Description |
|---|
TimedWait | StageTaskTypeTimedWait indicates the stage task is a timed wait.
|
Approval | StageTaskTypeApproval indicates the stage task is an approval.
|
StageUpdatingStatus
StageUpdatingStatus defines the status of the update run in a stage.
Appears in:
| Field | Description | Default | Validation |
|---|
stageName string | The name of the stage. | | Required: {}
|
clusters ClusterUpdatingStatus array | The list of each cluster’s updating status in this stage. | | Required: {}
|
afterStageTaskStatus StageTaskStatus array | The status of the post-update tasks associated with the current stage.
Empty if the stage has not finished updating all the clusters. | | MaxItems: 2
Optional: {}
|
beforeStageTaskStatus StageTaskStatus array | The status of the pre-update tasks associated with the current stage. | | MaxItems: 1
Optional: {}
|
startTime Time | The time when the update started on the stage. Empty if the stage has not started updating. | | Format: date-time
Optional: {}
Type: string
|
endTime Time | The time when the update finished on the stage. Empty if the stage has not started updating. | | Format: date-time
Optional: {}
Type: string
|
conditions Condition array | Conditions is an array of current observed updating conditions for the stage. Empty if the stage has not started updating.
Known conditions are “Progressing”, “Succeeded”. | | Optional: {}
|
StagedUpdateRun
StagedUpdateRun represents a stage by stage update process that applies ResourcePlacement
selected resources to specified clusters.
Resources from unselected clusters are removed after all stages in the update strategy are completed.
Each StagedUpdateRun object corresponds to a single release of a specific resource version.
The release is abandoned if the StagedUpdateRun object is deleted or the scheduling decision changes.
The name of the StagedUpdateRun must conform to RFC 1123.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | StagedUpdateRun | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec UpdateRunSpec | The desired state of StagedUpdateRun. | | Required: {}
|
status UpdateRunStatus | The observed status of StagedUpdateRun. | | Optional: {}
|
StagedUpdateStrategy
StagedUpdateStrategy defines a reusable strategy that specifies the stages and the sequence
in which the selected cluster resources will be updated on the member clusters.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | StagedUpdateStrategy | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec UpdateStrategySpec | The desired state of StagedUpdateStrategy. | | Required: {}
|
State
Underlying type: string
State represents the desired state of an update run.
Appears in:
| Field | Description |
|---|
Initialize | StateInitialize describes user intent to initialize but not run the update run.
This is the default state when an update run is created.
Users can subsequently set the state to Run.
|
Run | StateRun describes user intent to execute (or resume execution if stopped).
Users can subsequently set the state to Stop.
|
Stop | StateStop describes user intent to stop the update run.
Users can subsequently set the state to Run.
|
StatusReportingScope
Underlying type: string
StatusReportingScope defines where ClusterResourcePlacement status information is made available.
This setting only applies to ClusterResourcePlacements that select resources from a single namespace.
It enables different levels of access to placement status across cluster and namespace scopes.
Appears in:
| Field | Description |
|---|
ClusterScopeOnly | ClusterScopeOnly makes status available only through the cluster-scoped ClusterResourcePlacement object.
This is the default behavior where status information is accessible only to users with cluster-level permissions.
|
NamespaceAccessible | NamespaceAccessible makes status available in both cluster and namespace scopes.
In addition to the cluster-scoped status, a ClusterResourcePlacementStatus object is created
in the target namespace, enabling namespace-scoped users to access placement status information.
|
Toleration
Toleration allows ClusterResourcePlacement to tolerate any taint that matches
the triple <key,value,effect> using the matching operator .
Appears in:
| Field | Description | Default | Validation |
|---|
key string | Key is the taint key that the toleration applies to. Empty means match all taint keys.
If the key is empty, operator must be Exists; this combination means to match all values and all keys. | | Optional: {}
|
operator TolerationOperator | Operator represents a key’s relationship to the value.
Valid operators are Exists and Equal. Defaults to Equal.
Exists is equivalent to wildcard for value, so that a
ClusterResourcePlacement can tolerate all taints of a particular category. | Equal | Enum: [Equal Exists]
Optional: {}
|
value string | Value is the taint value the toleration matches to.
If the operator is Exists, the value should be empty, otherwise just a regular string. | | Optional: {}
|
effect TaintEffect | Effect indicates the taint effect to match. Empty means match all taint effects.
When specified, only allowed value is NoSchedule. | | Enum: [NoSchedule]
Optional: {}
|
TopologySpreadConstraint
TopologySpreadConstraint specifies how to spread resources among the given cluster topology.
Appears in:
| Field | Description | Default | Validation |
|---|
maxSkew integer | MaxSkew describes the degree to which resources may be unevenly distributed.
When whenUnsatisfiable=DoNotSchedule, it is the maximum permitted difference
between the number of resource copies in the target topology and the global minimum.
The global minimum is the minimum number of resource copies in a domain.
When whenUnsatisfiable=ScheduleAnyway, it is used to give higher precedence
to topologies that satisfy it.
It’s an optional field. Default value is 1 and 0 is not allowed. | 1 | Minimum: 1
Optional: {}
|
topologyKey string | TopologyKey is the key of cluster labels. Clusters that have a label with this key
and identical values are considered to be in the same topology.
We consider each <key, value> as a “bucket”, and try to put balanced number
of replicas of the resource into each bucket honor the MaxSkew value.
It’s a required field. | | Required: {}
|
whenUnsatisfiable UnsatisfiableConstraintAction | WhenUnsatisfiable indicates how to deal with the resource if it doesn’t satisfy
the spread constraint.
- DoNotSchedule (default) tells the scheduler not to schedule it.
- ScheduleAnyway tells the scheduler to schedule the resource in any cluster,
but giving higher precedence to topologies that would help reduce the skew.
It’s an optional field. | | Optional: {}
|
UnsatisfiableConstraintAction
Underlying type: string
UnsatisfiableConstraintAction defines the type of actions that can be taken if a constraint is not satisfied.
Appears in:
| Field | Description |
|---|
DoNotSchedule | DoNotSchedule instructs the scheduler not to schedule the resource
onto the cluster when constraints are not satisfied.
|
ScheduleAnyway | ScheduleAnyway instructs the scheduler to schedule the resource
even if constraints are not satisfied.
|
UpdateRunSpec
UpdateRunSpec defines the desired rollout strategy and the snapshot indices of the resources to be updated.
It specifies a stage-by-stage update process across selected clusters for the given ResourcePlacement object.
Appears in:
| Field | Description | Default | Validation |
|---|
placementName string | PlacementName is the name of placement that this update run is applied to.
There can be multiple active update runs for each placement, but
it’s up to the DevOps team to ensure they don’t conflict with each other. | | MaxLength: 255
Required: {}
|
resourceSnapshotIndex string | The resource snapshot index of the selected resources to be updated across clusters.
The index represents a group of resource snapshots that includes all the resources a ResourcePlacement selected. | | Optional: {}
|
stagedRolloutStrategyName string | The name of the update strategy that specifies the stages and the sequence
in which the selected resources will be updated on the member clusters. The stages
are computed according to the referenced strategy when the update run starts
and recorded in the status field. | | Required: {}
|
state State | State indicates the desired state of the update run.
Initialize: The update run should be initialized but execution should not start (default).
Run: The update run should execute or resume execution.
Stop: The update run should stop execution. | Initialize | Enum: [Initialize Run Stop]
Optional: {}
|
UpdateRunStatus
UpdateRunStatus defines the observed state of the ClusterStagedUpdateRun.
Appears in:
| Field | Description | Default | Validation |
|---|
policySnapshotIndexUsed string | PolicySnapShotIndexUsed records the policy snapshot index of the ClusterResourcePlacement (CRP) that
the update run is based on. The index represents the latest policy snapshot at the start of the update run.
If a newer policy snapshot is detected after the run starts, the staged update run is abandoned.
The scheduler must identify all clusters that meet the current policy before the update run begins.
All clusters involved in the update run are selected from the list of clusters scheduled by the CRP according
to the current policy. | | Optional: {}
|
policyObservedClusterCount integer | PolicyObservedClusterCount records the number of observed clusters in the policy snapshot.
It is recorded at the beginning of the update run from the policy snapshot object.
If the ObservedClusterCount value is updated during the update run, the update run is abandoned. | | Optional: {}
|
resourceSnapshotIndexUsed string | ResourceSnapshotIndexUsed records the resource snapshot index that the update run is based on.
The index represents the same resource snapshots as specified in the spec field, or the latest. | | |
appliedStrategy ApplyStrategy | ApplyStrategy is the apply strategy that the stagedUpdateRun is using.
It is the same as the apply strategy in the CRP when the staged update run starts.
The apply strategy is not updated during the update run even if it changes in the CRP. | | Optional: {}
|
stagedUpdateStrategySnapshot UpdateStrategySpec | UpdateStrategySnapshot is the snapshot of the UpdateStrategy used for the update run.
The snapshot is immutable during the update run.
The strategy is applied to the list of clusters scheduled by the CRP according to the current policy.
The update run fails to initialize if the strategy fails to produce a valid list of stages where each selected
cluster is included in exactly one stage. | | Optional: {}
|
stagesStatus StageUpdatingStatus array | StagesStatus lists the current updating status of each stage.
The list is empty if the update run is not started or failed to initialize. | | Optional: {}
|
deletionStageStatus StageUpdatingStatus | DeletionStageStatus lists the current status of the deletion stage. The deletion stage
removes all the resources from the clusters that are not selected by the
current policy after all the update stages are completed. | | Optional: {}
|
conditions Condition array | Conditions is an array of current observed conditions for StagedUpdateRun.
Known conditions are “Initialized”, “Progressing”, “Succeeded”. | | Optional: {}
|
UpdateStrategySpec
UpdateStrategySpec defines the desired state of the StagedUpdateStrategy.
Appears in:
| Field | Description | Default | Validation |
|---|
stages StageConfig array | Stage specifies the configuration for each update stage. | | MaxItems: 31
Required: {}
|
WhenToApplyType
Underlying type: string
WhenToApplyType describes when Fleet would apply the manifests on the hub cluster to
the member clusters.
Appears in:
| Field | Description |
|---|
Always | WhenToApplyTypeAlways instructs Fleet to periodically apply hub cluster manifests
on the member cluster side; this will effectively overwrite any change in the fields
managed by Fleet (i.e., specified in the hub cluster manifest).
|
IfNotDrifted | WhenToApplyTypeIfNotDrifted instructs Fleet to stop applying hub cluster manifests on
clusters that have drifted from the desired state; apply ops would still continue on
the rest of the clusters.
|
WhenToTakeOverType
Underlying type: string
WhenToTakeOverType describes the type of the action to take when we first apply the
resources to the member cluster.
Appears in:
| Field | Description |
|---|
IfNoDiff | WhenToTakeOverTypeIfNoDiff instructs Fleet to apply a manifest with a corresponding
pre-existing resource on a member cluster if and only if the pre-existing resource
looks the same as the manifest. Should there be any inconsistency, Fleet will skip
the apply op; no change will be made on the resource and Fleet will not claim
ownership on it.
Note that this will not stop Fleet from processing other manifests in the same
placement that do not concern the takeover process (e.g., the manifests that have
not been created yet, or that are already under the management of Fleet).
|
Always | WhenToTakeOverTypeAlways instructs Fleet to always apply manifests to a member cluster,
even if there are some corresponding pre-existing resources. Some fields on these
resources might be overwritten, and Fleet will claim ownership on them.
|
Never | WhenToTakeOverTypeNever instructs Fleet to never apply a manifest to a member cluster
if there is a corresponding pre-existing resource.
Note that this will not stop Fleet from processing other manifests in the same placement
that do not concern the takeover process (e.g., the manifests that have not been created
yet, or that are already under the management of Fleet).
If you would like Fleet to stop processing manifests all together and do not assume
ownership on any pre-existing resources, use this option along with the ReportDiff
apply strategy type. This setup would instruct Fleet to touch nothing on the member
cluster side but still report configuration differences between the hub cluster
and member clusters. Fleet will not give up ownership that it has already assumed, though.
|
Work
Work is the Schema for the works API.
Appears in:
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | Work | | |
metadata ObjectMeta | Refer to Kubernetes API documentation for fields of metadata. | | |
spec WorkSpec | spec defines the workload of a work. | | Optional: {}
|
status WorkStatus | status defines the status of each applied manifest on the spoke cluster. | | |
WorkList
WorkList contains a list of Work.
| Field | Description | Default | Validation |
|---|
apiVersion string | placement.kubernetes-fleet.io/v1beta1 | | |
kind string | WorkList | | |
metadata ListMeta | Refer to Kubernetes API documentation for fields of metadata. | | Optional: {}
|
items Work array | List of works. | | |
WorkResourceIdentifier
WorkResourceIdentifier provides the identifiers needed to interact with any arbitrary object.
Renamed original “ResourceIdentifier” so that it won’t conflict with ResourceIdentifier defined in the clusterresourceplacement_types.go.
Appears in:
| Field | Description | Default | Validation |
|---|
ordinal integer | Ordinal represents an index in manifests list, so the condition can still be linked
to a manifest even though manifest cannot be parsed successfully. | | |
group string | Group is the group of the resource. | | |
version string | Version is the version of the resource. | | |
kind string | Kind is the kind of the resource. | | |
resource string | Resource is the resource type of the resource. | | |
namespace string | Namespace is the namespace of the resource, the resource is cluster scoped if the value
is empty. | | |
name string | Name is the name of the resource. | | |
WorkSpec
WorkSpec defines the desired state of Work.
Appears in:
| Field | Description | Default | Validation |
|---|
workload WorkloadTemplate | Workload represents the manifest workload to be deployed on spoke cluster | | |
applyStrategy ApplyStrategy | ApplyStrategy describes how to resolve the conflict if the resource to be placed already exists in the target cluster
and is owned by other appliers. | | Optional: {}
|
reportBackStrategy ReportBackStrategy | ReportBackStrategy describes how to report back the status of applied resources on the member cluster. | | Optional: {}
|
WorkStatus
WorkStatus defines the observed state of Work.
Appears in:
| Field | Description | Default | Validation |
|---|
conditions Condition array | Conditions contains the different condition statuses for this work.
Valid condition types are:
1. Applied represents workload in Work is applied successfully on the spoke cluster.
2. Progressing represents workload in Work in the transitioning from one state to another the on the spoke cluster.
3. Available represents workload in Work exists on the spoke cluster.
4. Degraded represents the current state of workload does not match the desired
state for a certain period. | | |
manifestConditions ManifestCondition array | ManifestConditions represents the conditions of each resource in work deployed on
spoke cluster. | | Optional: {}
|
WorkloadTemplate
WorkloadTemplate represents the manifest workload to be deployed on spoke cluster
Appears in:
| Field | Description | Default | Validation |
|---|
manifests Manifest array | Manifests represents a list of kubernetes resources to be deployed on the spoke cluster. | | Optional: {}
|